| 深度学习实战:基于CNN的猫狗图像识别 | 您所在的位置:网站首页 › 狗结构图 › 深度学习实战:基于CNN的猫狗图像识别 |
深度学习实战:基于CNN的猫狗图像识别
|
公众号:尤而小屋作者:Peter编辑:Peter 大家好,我是Peter~ 本文记录了第一个基于卷积神经网络在图像识别领域的应用:猫狗图像识别。主要内容包含: 数据处理神经网络模型搭建数据增强实现本文中使用的深度学习框架是Keras; 图像数据来自kaggle官网:https://www.kaggle.com/c/dogs-vs-cats/data
数据集包含25000张图片,猫和狗各有12500张;创建每个类别1000个样本的训练集、500个样本的验证集和500个样本的测试集 注意:只取出部分的数据进行建模
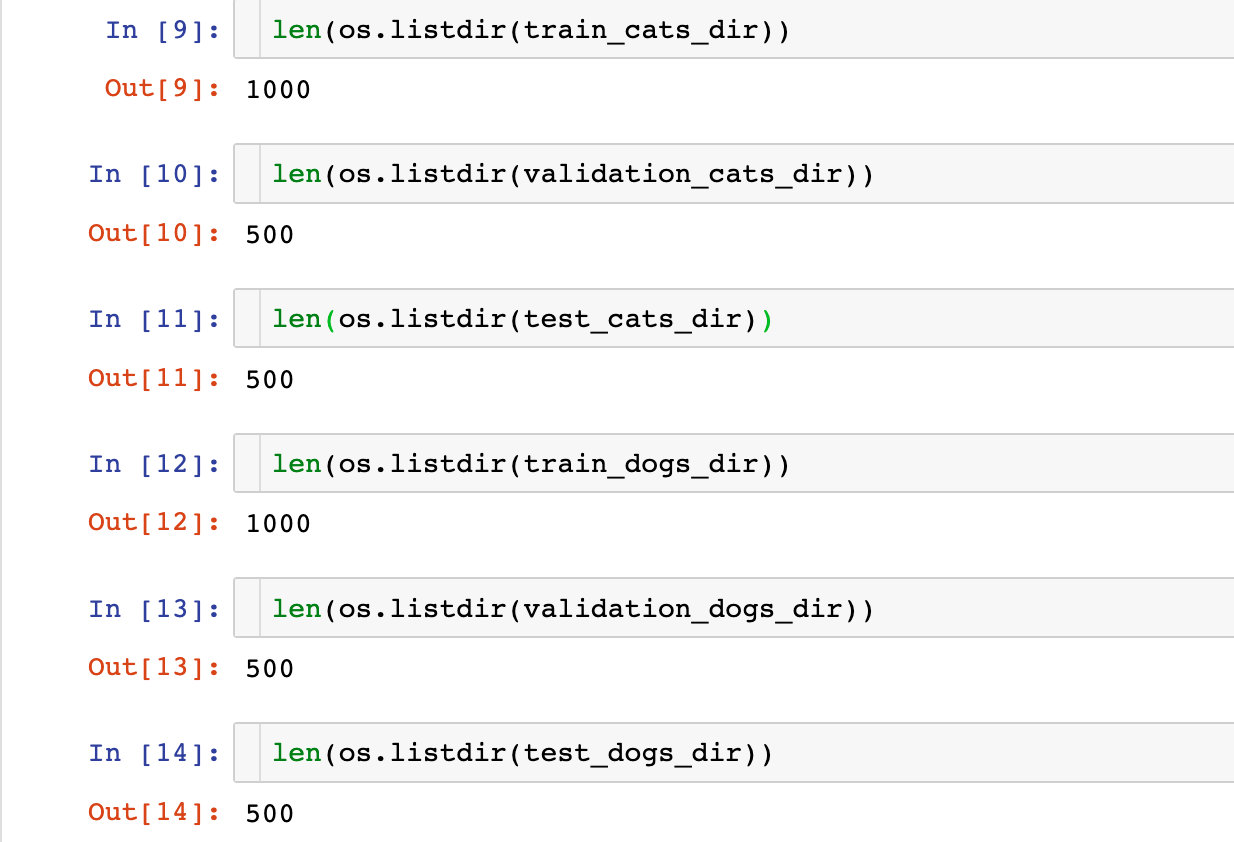
In [1]: import os, shutilIn [2]: current_dir = !pwd # 当前目录 current_dir[0]Out[2]: '/Users/peter/Desktop/kaggle/kaggle_12_dogs&cats/dogs-vs-cats'创建新的目录来存储需要的数据集: base_dir = current_dir[0] + '/cats_dogs_small' os.mkdir(base_dir) # 创建目录 # 分别创建训练集、验证集和测试集的目录 train_dir = os.path.join(base_dir,"train") os.mkdir(train_dir) validation_dir = os.path.join(base_dir,"validation") os.mkdir(validation_dir) test_dir = os.path.join(base_dir,"test") os.mkdir(test_dir) # 猫、狗的训练、验证、测试图像目录 train_cats_dir = os.path.join(train_dir, "cats") os.mkdir(train_cats_dir) train_dogs_dir = os.path.join(train_dir, "dogs") os.mkdir(train_dogs_dir) validation_cats_dir = os.path.join(validation_dir, "cats") os.mkdir(validation_cats_dir) validation_dogs_dir = os.path.join(validation_dir, "dogs") os.mkdir(validation_dogs_dir) test_cats_dir = os.path.join(test_dir, "cats") os.mkdir(test_cats_dir) test_dogs_dir = os.path.join(test_dir, "dogs") os.mkdir(test_dogs_dir) 数据集复制In [5]: # 1000张当做训练集train fnames = ['cat.{}.jpg'.format(i) for i in range(1000)] for fname in fnames: # 源目录文件 src = os.path.join(current_dir[0] + "/train", fname) # 目标目录 dst = os.path.join(train_cats_dir, fname) shutil.copyfile(src, dst)In [6]: # 500张当做验证集valiation fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)] for fname in fnames: src = os.path.join(current_dir[0] + "/train", fname) dst = os.path.join(validation_cats_dir, fname) shutil.copyfile(src, dst)In [7]: # 500张当做测试集test fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)] for fname in fnames: src = os.path.join(current_dir[0] + "/train", fname) dst = os.path.join(test_cats_dir, fname) shutil.copyfile(src, dst)In [8]: # 针对dog的3个同样操作 # 1、1000张当做训练集train fnames = ['dog.{}.jpg'.format(i) for i in range(1000)] for fname in fnames: src = os.path.join(current_dir[0] + "/train", fname) dst = os.path.join(train_dogs_dir, fname) shutil.copyfile(src, dst) # 2、500张当做验证集valiation fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)] for fname in fnames: src = os.path.join(current_dir[0] + "/train", fname) dst = os.path.join(validation_dogs_dir, fname) shutil.copyfile(src, dst) # 3、500张当做测试集test fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)] for fname in fnames: src = os.path.join(current_dir[0] + "/train", fname) dst = os.path.join(test_dogs_dir, fname) shutil.copyfile(src, dst) 检查数据针对猫狗两个类别中查看每个集(训练、验证、测试)中分别包含多少张图像:
复习一下卷积神经网络的构成:Conv2D层(使用relu激活函数) + MaxPooling2D层 交替堆叠构成。 当需要更大的图像和更复杂的问题,需要再添加一个 Conv2D层(使用relu激活函数) + MaxPooling2D层。 这样做的好处: 增大网络容量减少特征图的尺寸需要注意的是:猫狗分类是二分类问题,所以网络的最后一层是使用sigmoid激活的单一单元(大小为1的Dense层) 在网络中特征图的深度在逐渐增大(从32到128),但是特征图的尺寸在逐渐减小(从150-150到7-7) 深度增加:原始图像更复杂,需要更多的过滤器尺寸减小:更多的卷积和池化层对图像在不断地压缩和抽象 网络搭建In [15]: import tensorflow as tf from keras import layers from keras import models model = models.Sequential() model.add(tf.keras.layers.Conv2D(32,(3,3),activation="relu", input_shape=(150,150,3))) model.add(tf.keras.layers.MaxPooling2D((2,2))) model.add(tf.keras.layers.Conv2D(64,(3,3),activation="relu")) model.add(tf.keras.layers.MaxPooling2D((2,2))) model.add(tf.keras.layers.Conv2D(128,(3,3),activation="relu")) model.add(tf.keras.layers.MaxPooling2D((2,2))) model.add(tf.keras.layers.Conv2D(128,(3,3),activation="relu")) model.add(tf.keras.layers.MaxPooling2D((2,2))) # model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(512, activation="relu")) model.add(tf.keras.layers.Dense(1, activation="sigmoid")) model.summary()
网络最后一层是单一sigmoid单元,使用二元交叉熵作为损失函数 In [16]: # 原文:from keras import optimizers from tensorflow.keras import optimizers model.compile(loss="binary_crossentropy", optimizer=optimizers.RMSprop(lr=1e-4), metrics=["acc"]) 数据预处理数据输入到神经网络之前必须先转成浮点数张量。 keras有个处理图像的模块:keras.preprocessing.image。 它包含ImageDataGenerator类,可以快速创建Python生成器,将图形文件处理成张量批量 插播知识点:如何理解python中的生成器?
In [18]: from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator(rescale=1./255) # 进行缩放 test_datagen = ImageDataGenerator(rescale=1./255) # 进行缩放 train_generator = train_datagen.flow_from_directory( train_dir, # 待处理的目录 target_size=(150,150), # 图像大小设置 batch_size=20, class_mode="binary" # 损失函数是binary_crossentropy 所以使用二进制标签 ) validation_generator = test_datagen.flow_from_directory( validation_dir, # 待处理的目录 target_size=(150,150), # 图像大小设置 batch_size=20, class_mode="binary" # 损失函数是binary_crossentropy 所以使用二进制标签 ) Found 2000 images belonging to 2 classes. Found 1000 images belonging to 2 classes.In [19]: for data_batch, labels_batch in train_generator: print(data_batch.shape) print(labels_batch.shape) break (20, 150, 150, 3) (20,)生成器的输出是150-150的RGB图像和二进制标签,形状为(20,)组成的批量。每个批量包含20个样本(批量的大小)。 生成器会不断地生成这些批量,不断地循环目标文件夹中的图像。 keras模型使用fit_generator方法来拟合生成器的效果。模型有个参数steps_per_epoch参数:从生成器中抽取steps_per_epoch个批量后,拟合进入下一轮。 本例中:总共是2000个样本,每个批量是20个样本,所以需要100个批量 模型拟合In [20]: history = model.fit_generator( train_generator, # 第一个参数必须是Python生成器 steps_per_epoch=100, # 2000 / 20 epochs=30, # 迭代次数 validation_data=validation_generator, # 待验证的数据集 validation_steps=50 )
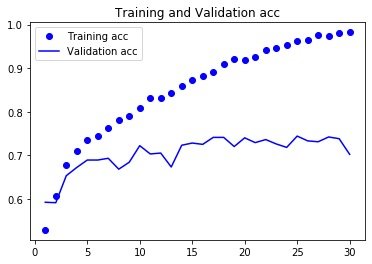
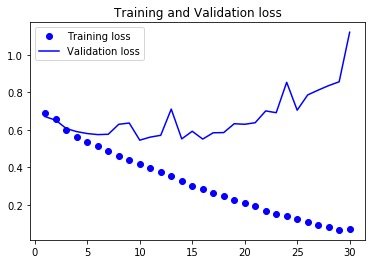
In [21]: # 保存模型 # model.save("cats_and_dogs_small.h5") 损失和精度曲线In [22]: import matplotlib.pyplot as plt %matplotlib inlineIn [23]: history_dict = history.history # 字典形式 for key, _ in history_dict.items(): print(key) loss acc val_loss val_accIn [24]: acc = history_dict["acc"] val_acc = history_dict["val_acc"] loss = history_dict["loss"] val_loss = history_dict["val_loss"]In [25]: epochs = range(1, len(acc)+1) # acc plt.plot(epochs, acc, "bo", label="Training acc") plt.plot(epochs, val_acc, "b", label="Validation acc") plt.title("Training and Validation acc") plt.legend() plt.figure() # loss plt.plot(epochs, loss, "bo", label="Training loss") plt.plot(epochs, val_loss, "b", label="Validation loss") plt.title("Training and Validation loss") plt.legend()
小结:得到过拟合的结论 随着时间的增加,训练精度在不断增加,接近100%,而验证精度则停留在70%验证的损失差不多在第6轮后达到最小值,后面一定轮数内保持不变,训练的损失一直下降,直接接近0 数据增强-data augmentation 什么是数据增强数据增强也是解决过拟合的一种方法,另外两种是: dropout权重衰减正则化什么是数据增强:从现有的训练样本中生成更多的训练数据,利用多种能够生成可信图像的随机变化来增加数据样本。 模型在训练时候不会查看两个完全相同的图像 设置数据增强In [26]: datagen = ImageDataGenerator( rotation_range=40, # 0-180的角度值 width_shift_range=0.2, # 水平和垂直方向的范围;相对于总宽度或者高度的比例 height_shift_range=0.2, shear_range=0.2, # 随机错切变换的角度 zoom_range=0.2, # 图像随机缩放的角度 horizontal_flip=True, # 随机将一半图像进行水平翻转 fill_mode="nearest" # 用于填充新创建像素的方法 ) 显示增强后图像In [27]: from keras.preprocessing import image fnames = [os.path.join(train_cats_dir,fname) for fname in os.listdir(train_cats_dir)] img_path = fnames[3]In [28]: # 读取图片并调整大小 img = image.load_img(img_path, target_size=(150,150)) # 转成数组 x = image.img_to_array(img) # shape转成(1,150,150,3) x = x.reshape((1,) + x.shape) i = 0 for batch in datagen.flow(x, batch_size=1): # 生成随机变换后的图像批量 plt.figure() imgplot = plt.imshow(image.array_to_img(batch[0])) i += 1 if i % 4 == 0: break # 循环是无限,需要在某个时刻终止 plt.show()
数据增强来训练网络的话,网络不会看到两次相同的输入。但是输入仍是高度相关的,不能完全消除过拟合。 可以考虑添加一个Dropout层,添加到密集分类连接器之前 In [29]: import tensorflow as tf from keras import layers from keras import models model = models.Sequential() model.add(tf.keras.layers.Conv2D(32,(3,3),activation="relu", input_shape=(150,150,3))) model.add(tf.keras.layers.MaxPooling2D((2,2))) model.add(tf.keras.layers.Conv2D(64,(3,3),activation="relu")) model.add(tf.keras.layers.MaxPooling2D((2,2))) model.add(tf.keras.layers.Conv2D(128,(3,3),activation="relu")) model.add(tf.keras.layers.MaxPooling2D((2,2))) model.add(tf.keras.layers.Conv2D(128,(3,3),activation="relu")) model.add(tf.keras.layers.MaxPooling2D((2,2))) # model.add(tf.keras.layers.Flatten()) # 添加内容 model.add(tf.keras.layers.Dropout(0.5)) model.add(tf.keras.layers.Dense(512, activation="relu")) model.add(tf.keras.layers.Dense(1, activation="sigmoid")) model.compile(loss="binary_crossentropy", optimizer=optimizers.RMSprop(lr=1e-4), metrics=["acc"])
关于报错解决:我们训练图像有2000张,验证图像1000张,和1000张测试图像。 steps_per_epoch=100,batch_size=32,如此数据应该是3200张,很明显输入训练数据不够。validation_steps=50,batch_size=32,如此数据应该是1600张,很明显验证数据不够。因此,改为steps_per_epoch=2000/32≈63,validation_steps=1000/32≈32。 In [44]: # 训练数据的增强 train_datagen = ImageDataGenerator( rescale=1. / 255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True ) # 不能增强验证数据 test_datagen = ImageDataGenerator(rescale=1.0 / 255) train_generator = train_datagen.flow_from_directory( train_dir, # 目标目录 target_size=(150,150), # 大小调整 batch_size=32, class_mode="binary" ) validation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150,150), batch_size=32, class_mode="binary" ) # 优化:报错有修改 history = model.fit_generator( train_generator, # 原文 steps_per_epoch=100, steps_per_epoch=63, # steps_per_epoch=2000/32≈63 取上限 epochs=100, validation_data=validation_generator, # 原文 validation_steps=50 validation_steps=32 # validation_steps=1000/32≈32 )
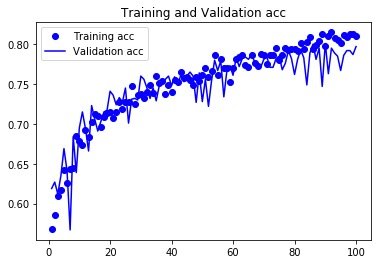
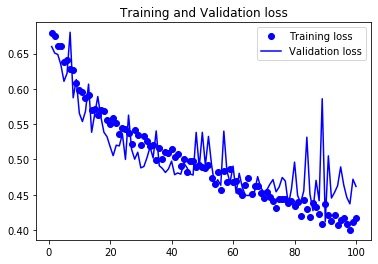
模型的保存: # 保存模型 model.save("cats_and_dogs_small_2.h5") 损失和精度曲线In [46]: history_dict = history.history # 字典形式 acc = history_dict["acc"] val_acc = history_dict["val_acc"] loss = history_dict["loss"] val_loss = history_dict["val_loss"]具体的绘图代码: epochs = range(1, len(acc)+1) # acc plt.plot(epochs, acc, "bo", label="Training acc") plt.plot(epochs, val_acc, "b", label="Validation acc") plt.title("Training and Validation acc") plt.legend() plt.figure() # loss plt.plot(epochs, loss, "bo", label="Training loss") plt.plot(epochs, val_loss, "b", label="Validation loss") plt.title("Training and Validation loss") plt.legend() plt.show()
结论:在使用了数据增强之后,模型不再拟合,训练集曲线紧跟着验证曲线;而且精度也变为81%,相比未正则之前得到了提高。 |











【本文地址】