| 5.3 综合案例1 | 您所在的位置:网站首页 › 爬虫爬取豆瓣图书top250的目的 › 5.3 综合案例1 |
5.3 综合案例1
|
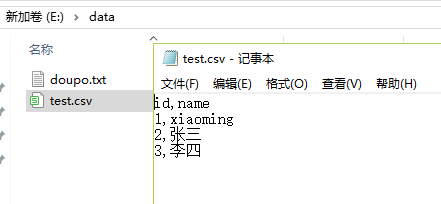
本节将利用Requests和Lxml第三方库,爬取豆瓣网图书TOP250数据,并存储到CSV格式的文件中。 5.3.1 将数据存储到CSV文件中 前面爬取的数据要么打印到屏幕上,要么存储到TXT文档中,这些格式并不利于数据的存储。那么大家平时是用什么来存储数据的呢?大部分读者可能是使用微软公司的Excel来储存数据,大规模的数据则是使用数据库(后面将会详细讲解)。CSV是存储表格数据的常用文件格式,Excel和很多应用都支持CSV格式,因为它很简洁。下面就是一个CSV文件的例子。 id,name 1,xiaoming 2,zhangsan 3,PeterPython中的csv库可以创建CSV文件,并写入数据: import csv fp = open('E:/data/test.csv','w+') #创建CSV文件 writer = csv.writer(fp) writer.writerow(('id','name')) writer.writerow(('1','xiaoming')) writer.writerow(('2','张三')) writer.writerow(('3','李四')) #写入行这时的本机E盘data文件夹里会生成名为test的CSV文件,用记事本打开,效果如下图所示。
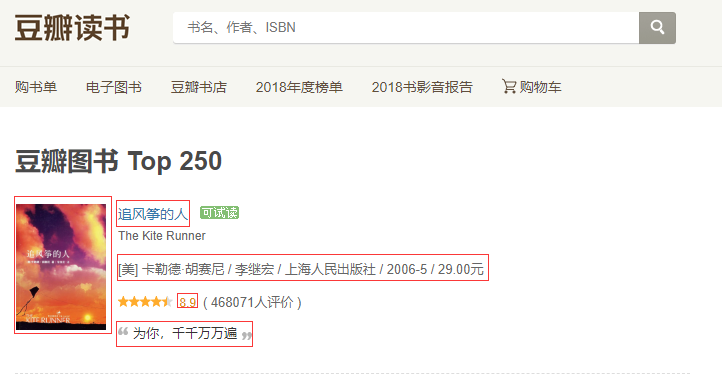
5.3.2 爬虫思路分析 ⑴本节爬取的内容为豆瓣图书TOP250的信息,如图所示。
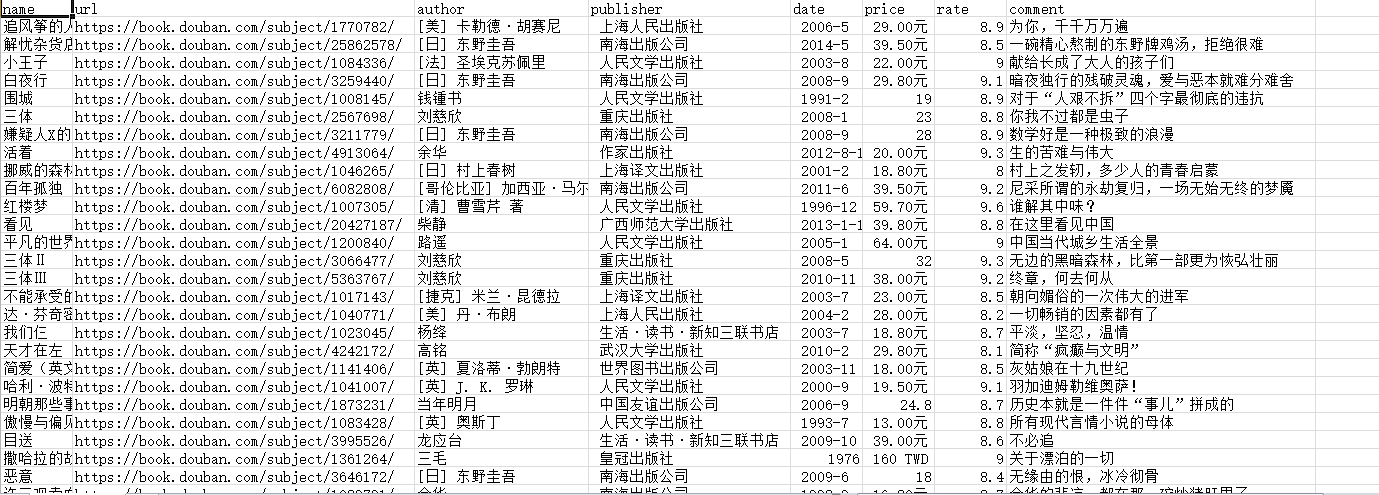
⑵爬取豆瓣网图书TOP250的10页信息,通过手动浏览,以下为前4页的网址: https://book.douban.com/top250? https://book.douban.com/top250?start=25 https://book.douban.com/top250?start=50 https://book.douban.com/top250?start=75然后把第1页的网址改为https://book.douban.com/top250?start=0也能正常浏览,因此只需要改start=后面的数字即可,以此来构造出10页的网址。 ⑶需要爬取的信息有:书名、书本的URL链接、作者、出版社和出版时间,书本价格、评分和评价,如下图所示。
注意:这里只爬取了第一个作者。 ⑷运用Python中的csv库,把爬取的信息存储在本地的CSV文本中。
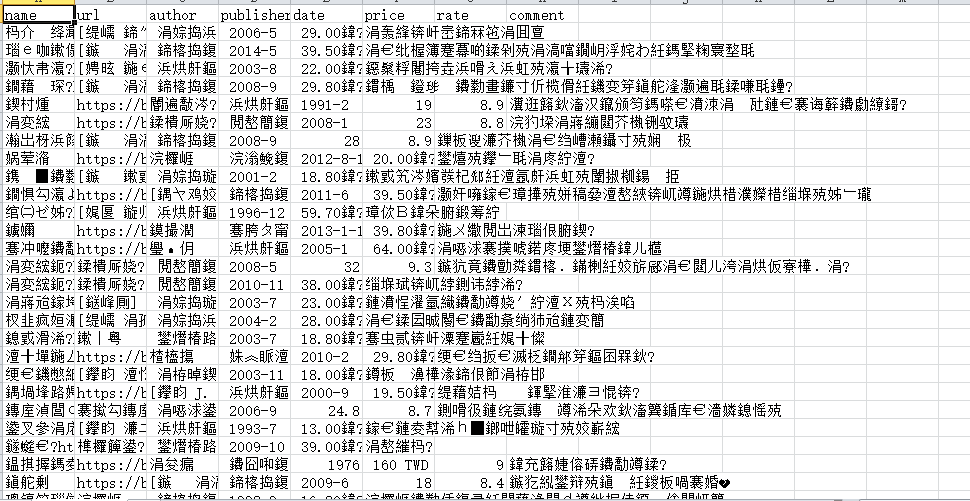
5.3.3 爬虫代码及分析 爬虫代码如下: 1 from lxml import etree 2 import requests 3 import csv #导入相应的库文件 4 5 fp = open('E:/data/doubanbook.csv','wt',newline='',encoding='utf-8') #创建csv 6 writer = csv.writer(fp) 7 writer.writerow(('name','url','author','publisher','date','price','rate','comment')) #写入header 8 9 urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)] #构造urls 10 11 headers = { 12 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' 13 } #加入请求头 14 15 for url in urls: 16 html = requests.get(url,headers=headers) 17 selector = etree.HTML(html.text) 18 infos = selector.xpath('//tr[@class="item"]') #取大标签,以此循环 19 for info in infos: 20 name = info.xpath('td/div/a/@title')[0] 21 url = info.xpath('td/div/a/@href')[0] 22 book_infos = info.xpath('td/p/text()')[0] 23 author = book_infos.split('/')[0] 24 publisher = book_infos.split('/')[-3] 25 date = book_infos.split('/')[-2] 26 price = book_infos.split('/')[-1] 27 rate = info.xpath('td/div/span[2]/text()')[0] 28 comments = info.xpath('td/p/span/text()') 29 comment = comments[0] if len(comments)!=0 else "空" 30 writer.writerow((name,url,author,publisher,date,price,rate,comment)) #写入数据 31 32 fp.close() #关闭csv文件 程序运行的结果保存在计算机里文件名为doubanbook的CSV文件中,如通过Excel打开会出现乱码错误,如图所示。
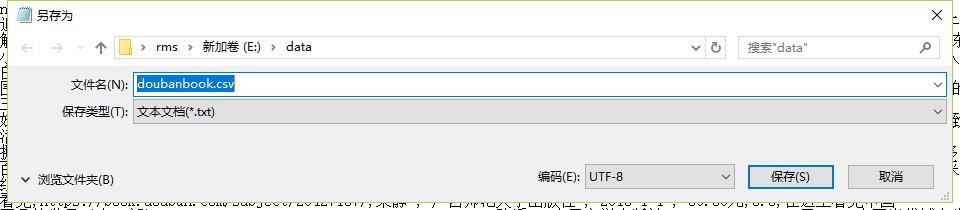
可以通过记事本打开,将其另存为编码为UTF-8的文件,便不会出现乱码问题,如图所示。
这时再通过Excel打开文件,便不会出现乱码问题了,如图所示。
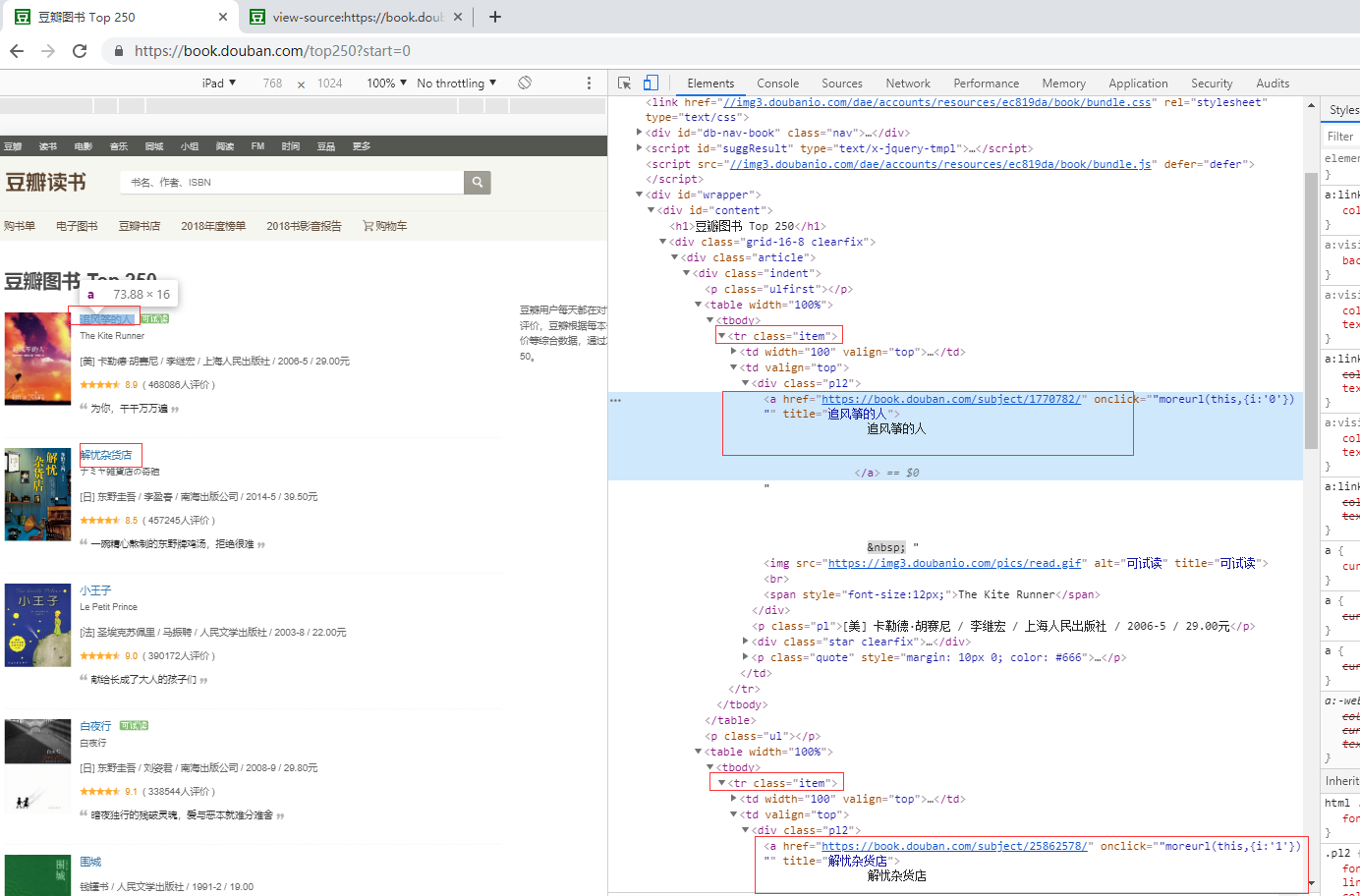
代码分析: ⑴第1~3行导入程序需要的库,Requests库用于请求网页获取网页数据,Lxml库永远解析提取数据,csv库用于存储数据。 ⑵第5~7行,创建csv文件,并且写入表头信息。 ⑶第9行,构造所有的URL链接。 ⑷第11~13行,通过Chrome浏览器的开发者工具,复制User-Agent,用于伪装为浏览器,便于爬虫的稳定性。 ⑸第15~30行,首先循环URL,根据“先抓大吼抓小,寻找循环点”的原则,找到每条信息的标签,如图所示。
然后再爬取详细信息,最后存入CSV文件中。 ⑹第32行关闭文件。
|

【本文地址】