| Python爬虫实战之三:requests | 您所在的位置:网站首页 › 爬取百度指数的python源码 › Python爬虫实战之三:requests |
Python爬虫实战之三:requests
|
本实战项目是中国大学MOOC国家精品课程《Python网络爬虫与信息提取》(by 嵩天 北京理工大学)学习笔记。代码段均可在ide中运行by now(2021-12-01). 1.爬取目标爬取的是百度/360搜索某个关键词返回的页面信息。 首先看一下百度请求数据的url长下面这样,这里搜索的是关键词字符串是‘Python’。
360搜索关键词'Python'的url及返回是下面这样的:
百度搜索url: http://www.baidu.com/s 360搜索url: http://www.so.com/s 3.技术路线继续深入了解requests方法的参数,在上一讲headers参数上又增加新参数‘params’的使用。 上一讲地址: Python爬虫实战之二:requests-爬取亚马逊商品详情页面_miracle2me的专栏-CSDN博客 本讲关键方法:requests.get(url,headers,params) 参数解释: url:需要爬取的网址 headers:以键值对形式传入浏览器的user-agent params:参数,针对本项目需要传入的请求关键词 4.全代码及输出 百度搜索代码 # 百度搜索全代码 # 全代码 url ='http://www.baidu.com/s' keyword ='Python' kv = {'wd':keyword} try: headers ={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3878.400 QQBrowser/10.8.4518.400'} r= requests.get(url,headers = headers,params = kv) r.raise_for_status() r.encoding= r.apparent_encoding print(r.text[:2000]) except: print('爬取失败') 百度关键词爬取结果
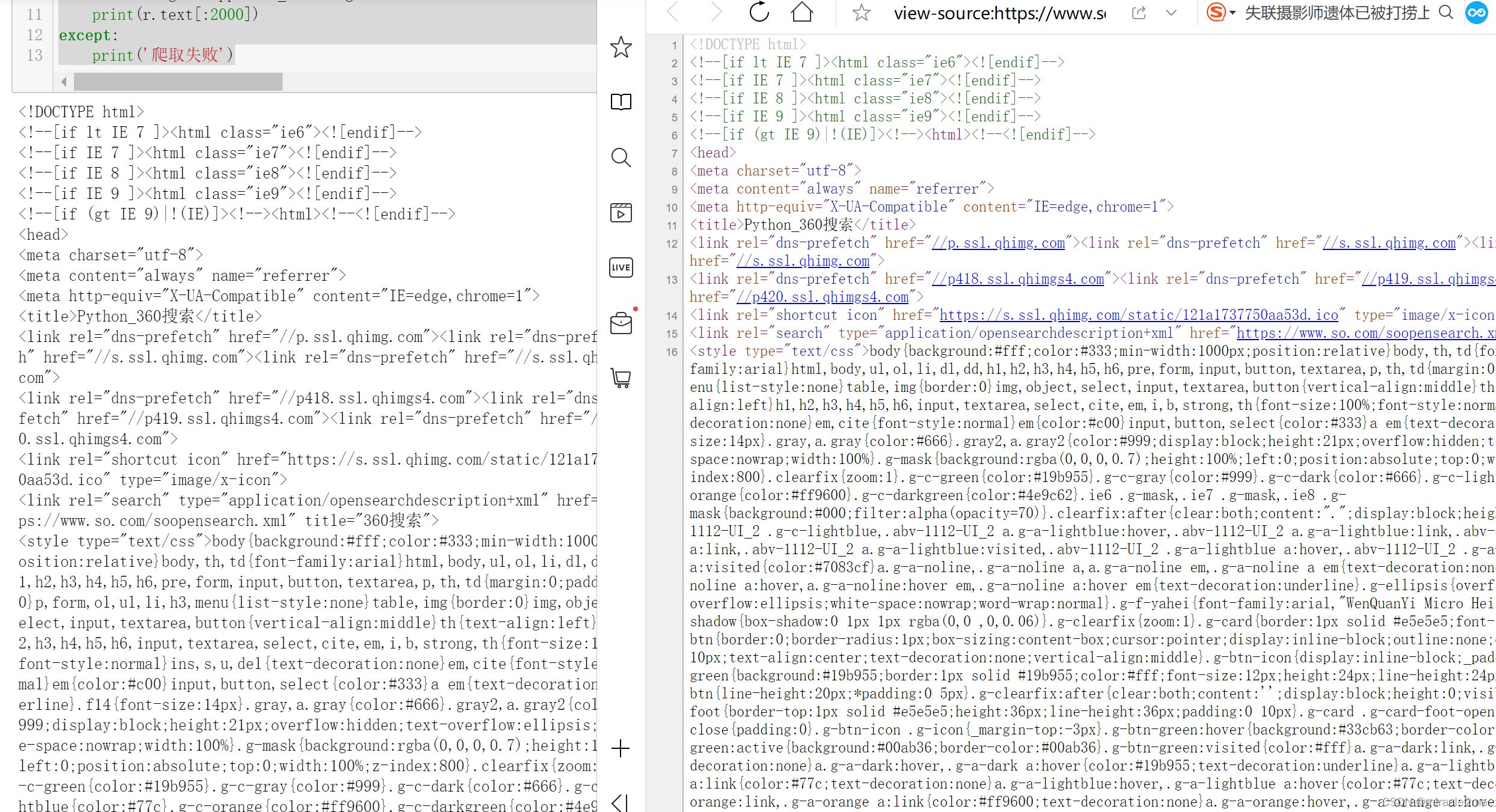
上图左边是使用爬虫爬取的网页文本,右边是网页源代码文件,结果一致,爬取成功。 360搜索代码 # 360搜索全代码 # 全代码 url ='http://www.so.com/s' keyword ='Python' kv = {'q':keyword} try: headers ={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3878.400 QQBrowser/10.8.4518.400'} r= requests.get(url,headers = headers,params = kv) r.raise_for_status() r.encoding= r.apparent_encoding print(r.text[:2000]) except: print('爬取失败') 360关键词爬取结果
上图左为爬虫爬取结果,右为网页源代码,结果一致,爬取成功。 5.总结本案例在实战案例二基础上增加了'params'参数的应用。params传入的是一个键值对,键名各平台可能有差异,如百度搜索传入键值对形式是{'wd':keyword},360搜索键值对形式为{'q':keyword}。 |



【本文地址】
公司简介
联系我们