| Python爬虫:输入单词获取百度翻译的翻译结果 | 您所在的位置:网站首页 › 爬出窗户英文翻译 › Python爬虫:输入单词获取百度翻译的翻译结果 |
Python爬虫:输入单词获取百度翻译的翻译结果
|
目录 一、分析 二、步骤 三、改进 四、代码 一、分析在学习 UA 伪装过后,我仍只知道如何通过 Python 爬虫访问某个网页,但如果我想获取百度翻译网站上某些具体内容又该如何操作呢? 先打开百度翻译页面,只有某一块这才是我想要的内容,我想通过输入单词获得对应的翻译结果,该怎么做呢
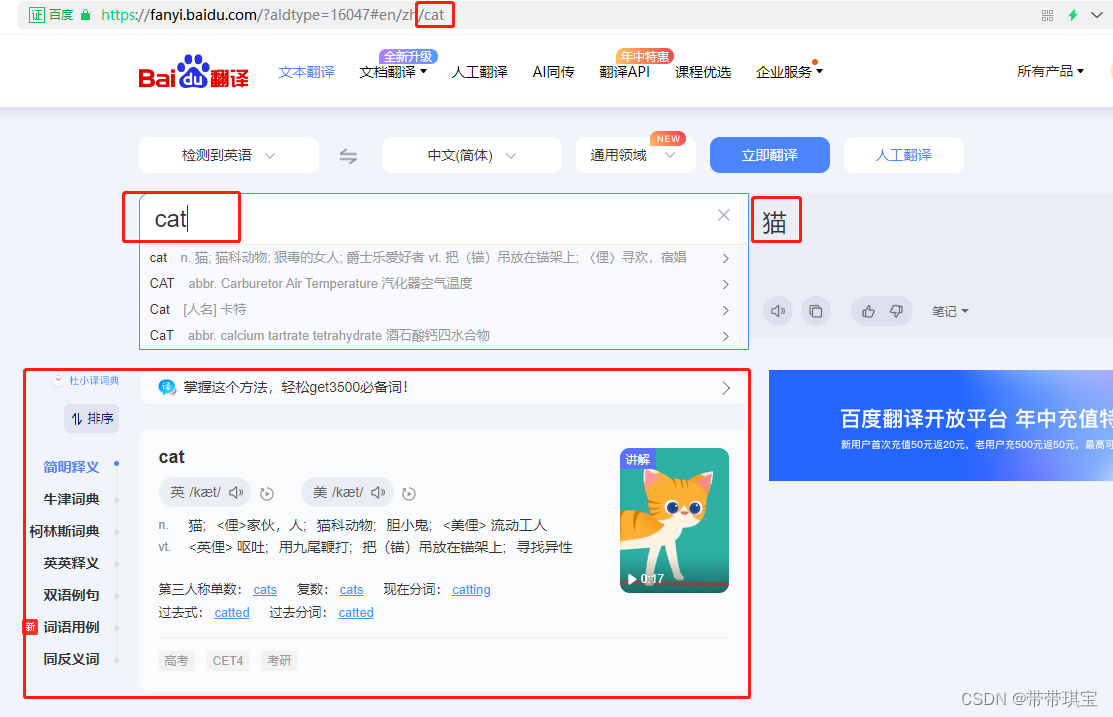
观察发现,在输入cat之后,URL 最后结尾会多一个 cat 单词,而当前页面会进行一个局部的刷新:
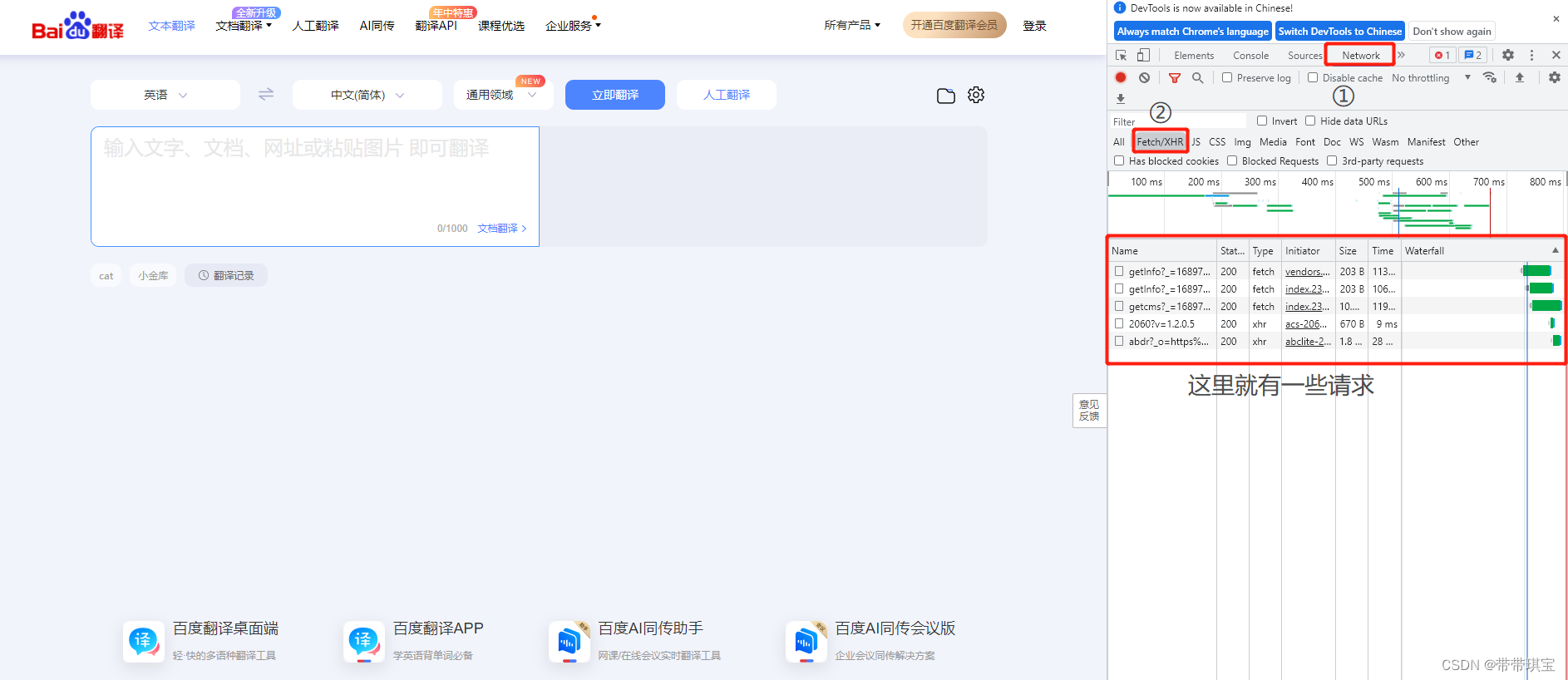
页面局部刷新的形式由 JavaScript 框架中的 Ajax 实现,也就是说在文本框当中录入单词后,网页会自动发送 Ajax 请求,我们只要捕获到 Ajax 请求,就相当于捕获到了更新的内容,即对应的翻译结果 打开抓包工具定位 Network 中的 XHR选项卡当中,这里有 Ajax 请求对应数据包
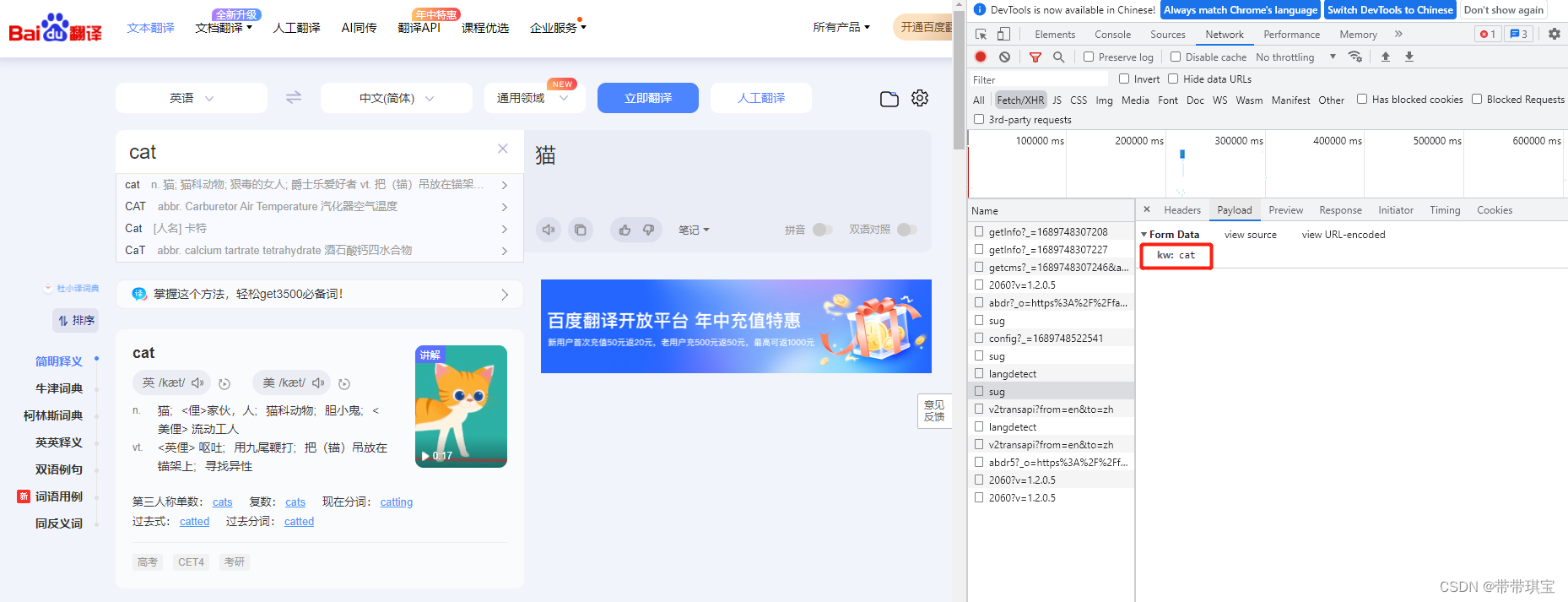
在文本框中键入单词 cat,有几个名为 sug 的 post 请求,其携带参数为c、ca、cat
通过数据包分析,每录入一个字符,就会为对应字符发起一个 Ajax 请求,在 Response-Headers 中的 Content-Type 可以看见,我们对该 URL 发起 Post 请求后,服务端响应回来的数据类型是 json 类型,在 Response 选项卡中可以直接查看服务器端响应回来的json数据
综上,我们需要想办法利用 requests 发起 post 请求,并处理参数,然后获得响应数据 json 串 1.获取请求的 URL,并进行UA伪装 UA伪装是必须使用的,80%门户网站都会使用UA检测 import requests post_url='https://fanyi.baidu.com/sug' header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'}2.参数处理(发起请求的URL有参数才需要处理),然后发送请求 post 里面的 data 对应的数据就是请求所携带的参数,这里只有一组参数,即 kw:cat data={'kw':'cat'} response=requests.post(post_url,data,headers=header)3.获取响应数据 .text() 返回的是一个字符串形式的 json 串,若确认响应数据是 json 类型,才可以使用 .json() 返回,该方法返回的是 obj 类型,此处返回一个字典对象,在响应头信息当中的 Content-Type 可以确认响应数据类型是否为 json dic_obj=response.json() print(dic_obj) print(type(dic_obj)) {'errno': 0, 'data': [{'k': 'cat', 'v': 'n. 猫; 猫科动物; 狠毒的女人; 爵士乐爱好者 vt. 把(锚)吊放在锚架上; 〈俚〉寻欢,宿娼'}, {'k': 'CAT', 'v': 'abbr. Carburetor Air Temperature 汽化器空气温度'}, {'k': 'Cat', 'v': '[人名] 卡特'}, {'k': 'CaT', 'v': 'abbr. calcium tartrate tetrahydrate 酒石酸钙四水合物'}, {'k': 'cata', 'v': '[机] 渺位; 依照'}]}返回的字典对象就是 cat 的翻译结果 4.持久化存储 直接把字典对象存到 json 当中,json.dump() 用于将 python 对象转换成 json 格式存储到文件中,是将dict类型的数据转成str类型,并写入到 json 文件。参数 obj:传入的对象(此处是字典对象),fp:将生成的文本文件存储的地方,是个文件描述符 fp=open('./dog.json','w',encoding='utf-8') json.dump(dic_obj,fp=fp,ensure_ascii=False) # 中文不能使用Ascii进行编码 三、改进前面得到的都是 cat 翻译的结果,现在想办法将其设置成动态的,再调整一下存储的文件名 word=input('enter the word:') data={'kw':word} fp=open(word+'.json','w',encoding='utf-8')实验成功
|


【本文地址】