| Python Selenium.WebDriver 对Cookies的处理及应用『模拟登录』 | 您所在的位置:网站首页 › 火狐怎么导入cookie › Python Selenium.WebDriver 对Cookies的处理及应用『模拟登录』 |
Python Selenium.WebDriver 对Cookies的处理及应用『模拟登录』
|
Python Selenium.WebDriver 对Cookies的处理及用途『模拟登录』
文章目录
Python Selenium.WebDriver 对Cookies的处理及用途『模拟登录』一、Cookie的介绍🍉二、Cookie在浏览器中的形式结构三、Selenium对Cookie的操作🥗四、利用Selenium进行模拟登录并使用Cookies五、获取的Cookies配合requests使用六、获取的Cookies配合爬虫框架Scrapy使用💦「难点」七、补充🍹参考资料💟相关博客😏
一、Cookie的介绍🍉
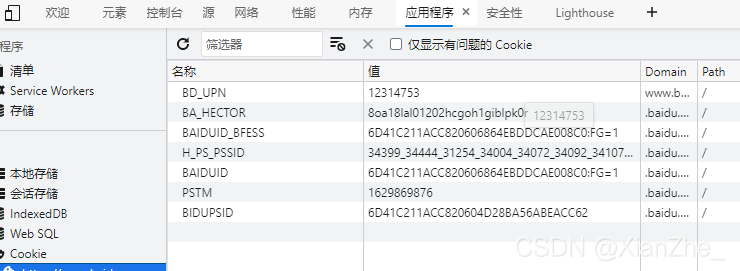
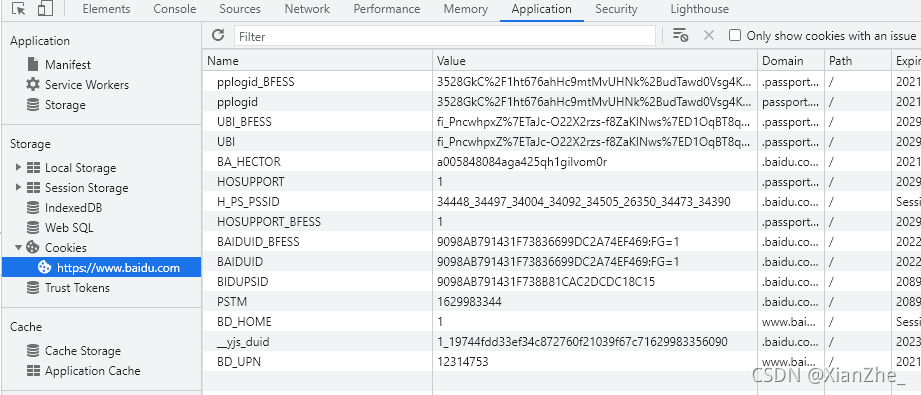
Cookie(复数形态:Cookies),又称“小甜饼”,为小型文本文件。某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密),Cookie保存在客户端中,按在客户端中的存储位置,可分为 内存Cookie和硬盘Cookie 内存 Cookie 由浏览器维护,浏览器关闭即消失,存在时间短暂。硬盘Cookie保存在硬盘里,除非用户手动清理或到了过期时间,硬盘Cookie不会清除,存在时间较长。所以,按存在时间,可分为非持久Cookie和持久Cookie Cookie的典型应用场景 网上购物: 当用户选购第一项商品,网站在向用户发送网页的时候,还发送了一段Cookie会记录着那项商品的信息,当用户访问另一个网页时,浏览器会把Cookie发送给服务器,这样服务器就能知道用户之前选购了什么,用户继续选购商品,服务器就会在原来那段Cookie里追加新的商品信息。结账的时候,服务器读取发送来的Cookie即可。网站账户登陆: 网页登陆是大部分人都遇到过的,网站往往会请求用户输入账户和密码以登陆网页,在登陆之后下次再去浏览网页时,网站会自动记住我们的密码,不需要再去进行重复性的账号密码输入即可保持登陆状态,或则用户可以勾选 「下次自动登陆」。 这是在第一次登陆时,服务器发送了包含登录凭据(用户名加密码的某种加密形式)的Cookie到用户的硬盘上进行保存,之后再登录时,如果该Cookie尚未到期,浏览器会发送该Cookie,服务器验证凭据,验证通过即可免去再登陆就可保持登陆状态 二、Cookie在浏览器中的形式结构Cookie对于爬虫来说是比较常用到的,一般随着爬虫请求发送,是实现反反爬的参数之一 我使用的是 Edge 浏览器,但 Chrome 浏览器其实也差不多一样。以百度首页为例,打开调试工具(F12),点击Application(应用程序),选择 Storage 下的 Cookies 选项,找到当前网页即可看到所有的 Cookie 可以发现的是,Cookie在浏览器中是一条一条存在的,每条Cookie都是一个键值对的结构 Selenium 能够实现操作浏览器的Cookie,因为本身就是其调用浏览器运行,能操作的内容有对Cookie的读取、新增和删除 1)、读取Cookie 读取Cookie有两种方法,分别是 driver.get_cookies() 和 driver.get_cookie(name) 从方法名上来看一个带s一个不带s,功能上看带s的是获取所有的Cookie对象,不带s的是获取指定的单条Cookie driver.get_cookies() 能够获取所有的Cookie,并以 列表 形式返回所有Cookie 演示代码:👇 from selenium import webdriver browser = webdriver.Edge(executable_path=r"msedgedriver.exe") browser.get("https://www.baidu.com/") print(browser.get_cookies()) [{'domain': '.baidu.com', 'expiry': 1629821019, 'httpOnly': False, 'name': 'BA_HECTOR', 'path': '/', 'secure': False, 'value': '8s818la521202160bp1gia2ic0r'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '34437_34441_31254_33848_34072_34092_34106_26350_34416_34390'}, {'domain': '.baidu.com', 'expiry': 1661353419, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': 'EDB65890D2F1E97267AD56A70D8F24E8:FG=1'}, {'domain': '.baidu.com', 'expiry': 3777301066, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': 'EDB65890D2F1E972DC3D6A6A8114E431'}, {'domain': '.baidu.com', 'expiry': 3777301066, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1629817419'}, {'domain': 'www.baidu.com', 'expiry': 1630681419, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'}]driver.get_cookie(name) 根据名称获取单个Cookie 源码: 对于.get_cookie(name)方法,咱们可以先去扩展一下去看源码,无非就是先用.get_cookies()方法获取所有的Cookie,再通过循环判断提取目标Cookie def get_cookie(self, name): """ Get a single cookie by name. Returns the cookie if found, None if not. :Usage: driver.get_cookie('my_cookie') """ if self.w3c: try: return self.execute(Command.GET_COOKIE, {'name': name})['value'] except NoSuchCookieException: return None else: cookies = self.get_cookies() for cookie in cookies: if cookie['name'] == name: return cookie return None演示代码:👇 获取百度首页名为BD_HOME的Cookie内容,并将其输出 from selenium import webdriver browser = webdriver.Edge(executable_path=r"msedgedriver.exe") browser.get("https://www.baidu.com/") print(browser.get_cookie("BD_HOME")) {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'}2)、新增Cookie 新增Cookie只有一个方法,那就是driver.add_cookie(cookie_dict),根据 二、Cookie在浏览器中的形式结构 可以得知Cookie是一个键值对数据,传入的Cookie对象中必须包含name和value两个属性,缺少其中任何一个都会添加失败。除此之外还有四个可选属性,分别为path,domain,secure,expiry 源码: 让咱们先来看看源码,源码中就有对 属性值的描述注释,还是值得去看的 def add_cookie(self, cookie_dict): """ Adds a cookie to your current session. :Args: - cookie_dict: A dictionary object, with required keys - "name" and "value"; optional keys - "path", "domain", "secure", "expiry" Usage: driver.add_cookie({'name' : 'foo', 'value' : 'bar'}) driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/'}) driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/', 'secure':True}) """ self.execute(Command.ADD_COOKIE, {'cookie': cookie_dict})演示代码:👇 向其百度首页添加一个名为 MyCookie 的Cookie,其值为 this is my cookie! from selenium import webdriver browser = webdriver.Edge(executable_path=r"msedgedriver.exe") browser.get("https://www.baidu.com/") browser.add_cookie({"name": "MyCookie", "value": "this is my cookie!"})在打开的浏览器窗口,打开调试工具就能看到添加的Cookie 3)、删除Cookie 删除Cookie与读取Cookie类似,也有两个方法,分别是driver.delete_all_cookies() 和 driver.delete_cookie(name),一个是全部删除,一个是删除其中一个,用法也于读取Cookie一样 driver.delete_all_cookies() 删除全部的Cookie 演示代码:👇 from selenium import webdriver browser = webdriver.Edge(executable_path=r"msedgedriver.exe") browser.get("https://www.baidu.com/") browser.delete_all_cookies()可以看到的是,百度首页在浏览器中的Cookie已经全部被清空了 driver.delete_cookie(name) 删除指定名称的Cookie 演示代码:👇 删除百度首页名为BD_HOME的Cookie内容 from selenium import webdriver browser = webdriver.Edge(executable_path=r"msedgedriver.exe") browser.get("https://www.baidu.com/") browser.delete_cookie("BD_HOME")可以看到名为BD_HOME的Cookie已经在浏览器中找不到了 在 爬虫领域 或 自动化测试中,总有一些网站只有登录后才能访问,或则某些数据只有在登录后才会出现。由于用户登陆后的身份信息通常会存放在Cookie中,因此可以将登录后的Cookie保存,再将此Cookie添加到网页中来模拟已登录状态。能有效避免在登录页面中进行多次操作,即一次登录后即可保留登录状态 实现的步骤很简单,1. 只需要将当前页面中的Cookie全部清空,2. 然后直接添加 已经在登录状态下 或 拥有身份信息 的Cookie在网页中,3. 最后别忘记刷新一下网页driver.refresh,就可以实现页面保留登录状态的效果 步骤示例:👇 # 删除所有的Cookies driver.delete_all_cookies() # 逐个添加Cookie,可以使用循环 driver.add_cookie(cookie_dict) driver.add_cookie(cookie_dict) ... driver.refresh()实际演示:👇🏻 还是以百度首页为例,实现流程: 先使用 Selenium.WebDriverWait 动作行为模拟网站登录将登录后的Cookies获取并保存到本地(以Json格式)下次打开网页使用Cookie进行网页登录需要注意的是,此代码为简单的百度首页登录,并未实现图片验证等自动验证功能,更多为参考意义,具体以实际为主 1)、让咱先来看看对百度首页的模拟登录 这里我使用的是Xpath定位 driver.find_element_by_xpath(xpath),当然也是可以使用其他的定位方式,如ID定位driver.find_element_by_id(id_) 由于存在百度首页登录时会出现验证的情况,代码并未对此进行自动验证处理,这时候就需要手动验证了 def handle_login(username, pwd, isverify=False): """ 百度首页登录处理方法 :param username: 用户名 :param pwd: 用户密码 :param isverify: 是否存在网页验证 """ # 点击右上角登录按钮 self.find_by_xpath(r"//a[@id='s-top-loginbtn']").click() time.sleep(1) # 点击用户名登录按钮 self.find_by_xpath(r"//p[@id='TANGRAM__PSP_11__footerULoginBtn']").click() # 向输入框输入账户名 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__userName']").send_keys(username) # 向输入框输入密码 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__password']").send_keys(pwd) # 点击登录按钮 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__submit']").click() # 手动图形验证等待 input("请手动进行图形验证,完毕后输入任意内容继续运行") if isverify: # 点击发送验证码按钮 self.find_by_xpath(r"//input[@id='TANGRAM__29__button_send_mobile']").click() # 等待用户输入手动验证码 vcode = input("请输入六位数验证码:") self.find_by_xpath(r"//input[@id='TANGRAM__29__input_vcode']").send_keys(vcode) # 点击确定按钮 self.find_by_xpath(r"//input[@id='TANGRAM__29__button_submit']").click()2)、Cookies处理 需要可持久化存储Cookie,以及对Cookie进行读取并判断是否存在 简单写两个函数 def save_cookies(data, encoding="utf-8"): """ 百度首页Cookies保存方法 :param data: 所保存数据 :param encoding: 文件编码,默认utf-8 """ with open(self.f_path, "w", encoding=encoding) as f_w: json.dump(data, f_w) def load_cookies(encoding="utf-8"): """ 百度首页Cookies读取方法 :param encoding: 文件编码,默认utf-8 """ if os.path.isfile(self.f_path): with open(self.f_path, "r", encoding=encoding) as f_r: user_status = json.load(f_r) return user_status3)、使用Cookie进行网页登录 根据刚开始的步骤示例,修改网页中的Cookies是很简单的 先将网页中原有的Cookies全部删除,然后通过循环一个个将保存的登录Cookie全部添加进网页 def cookies_login(cookies: list): """ 百度首页Cookies登录方法 :param cookies: 网页所需要添加的Cookie """ self.browser.delete_all_cookies() for c in cookies: self.browser.add_cookie(c) self.browser.refresh()4)、将上述流程总结写成一个对象 import os import json import time from selenium import webdriver class BaiduLogin: def __init__(self, url, executable_path, f_path): """ 对象初始化 :param url: 百度首页地址 :param executable_path: 浏览器驱动路径 :param f_path: Cookies文件保存路径 """ self.url = url self.browser = self.start_browser(executable_path) self.f_path = f_path @staticmethod def start_browser(executable_path): return webdriver.Edge(executable_path=executable_path) def start_url(self): self.browser.get(self.url) def find_by_xpath(self, xpath): return self.browser.find_element_by_xpath(xpath) def baidu_login(self, *args): self.start_url() if cookies := self.load_cookies(): self.__cookies_login(cookies) else: self.__handle_login(*args, **kwargs) def __handle_login(self, username, pwd, isverify=False): """ 百度首页登录处理方法 :param username: 用户名 :param pwd: 用户密码 :param isverify: 是否存在网页验证 """ # 点击右上角登录按钮 self.find_by_xpath(r"//a[@id='s-top-loginbtn']").click() time.sleep(1) # 点击用户名登录按钮 self.find_by_xpath(r"//p[@id='TANGRAM__PSP_11__footerULoginBtn']").click() # 向输入框输入账户名 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__userName']").send_keys(username) # 向输入框输入密码 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__password']").send_keys(pwd) # 点击登录按钮 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__submit']").click() # 手动图形验证等待 input("请手动进行图形验证,完毕后输入任意内容继续运行") if isverify: time.sleep(1) # 点击发送验证码按钮 self.find_by_xpath(r"//input[@id='TANGRAM__29__button_send_mobile']").click() # 等待用户输入手动验证码 vcode = input("请输入六位数验证码:") self.find_by_xpath(r"//input[@id='TANGRAM__29__input_vcode']").send_keys(vcode) # 点击确定按钮 self.find_by_xpath(r"//input[@id='TANGRAM__29__button_submit']").click() self.save_cookies(self.browser.get_cookies()) def __cookies_login(self, cookies: list): """ 百度首页Cookies登录方法 :param cookies: 网页所需要添加的Cookie """ self.browser.delete_all_cookies() for c in cookies: self.browser.add_cookie(c) self.browser.refresh() def save_cookies(self, data, encoding="utf-8"): """ 百度首页Cookies保存方法 :param data: 所保存数据 :param encoding: 文件编码,默认utf-8 """ with open(self.f_path, "w", encoding=encoding) as f_w: json.dump(data, f_w) def load_cookies(self, encoding="utf-8"): """ 百度首页Cookies读取方法 :param encoding: 文件编码,默认utf-8 """ if os.path.isfile(self.f_path): with open(self.f_path, "r", encoding=encoding) as f_r: user_status = json.load(f_r) return user_status def quit(self): # 关闭浏览器 self.browser.quit()调用:👇 target_driver = "msedgedriver.exe" url, cookie_fname = r"https://www.baidu.com/", "百度登录Cookies.json" login = BaiduLogin(url, target_driver, cookie_fname) login.baidu_login("用户名", "用户密码") 五、获取的Cookies配合requests使用在使用requests请求之前,我们得先知道对于requests来说是怎么使用Cookie 以百度首页为例,打开调试工具(F12),点击Network(网络\抓包工具),如果空白的话就按Ctrl + R 快捷键刷新网页读取,找到位于第一个的请求www.baidu.com,选择Headers(标头)后在下方就能看到咱们对于https://www.baidu.com/这个链接的Request Headers(请求头),在里面就能找到Cookie属性 但信心的朋友会发现在这里的cookie格式与我们在Application(应用程序),选择 Storage 下的 Cookies 选项看到的完全不一样,但其实都是同一些cookies数据,将两者放在一起进行仔细比较还是能发现共同点的 对于请求头来说,需要的只有name和value,这也是为什么在 三、Selenium对Cookie的操作 新增Cookie中讲到 传入的Cookie对象中必须包含name和value两个属性,两者以=号拼接,每一个cookie以;进行分割
在requests来说,使用Cookie常用的有两种方式: 通过请求头方式直接将Cookies给传入在 requests.get 或 requests.post 方法中传入cookies参数为了便于演示,会将requests返回的页面源码保存到html文件中进行展示 1)、通过请求头方式 在使用请求头方式时,想要事先将Cookies处理成与 图 5.1 中那样的格式,通过循环就能搞定,这没什么难度 预处理Cookies格式: def cookie_handle(cookies: list): """ cookies 标头格式化处理函数 :param cookies: selenium获取的cookies """ cookies = [f"{i['name']}={i['value']}" for i in cookies] return "; ".join(cookies)使用requests发送请求: import os import json import requests def cookies_load(path, encoding="utf-8"): if os.path.isfile(path): with open(path, "r", encoding=encoding) as f_r: cookies = json.load(f_r) return cookies def cookie_handle(cookies: list): """ cookies 标头格式化处理函数 :param cookies: selenium获取的cookies """ cookies = [f"{i['name']}={i['value']}" for i in cookies] return "; ".join(cookies) def get_and_save(url, path, encoding="utf-8", **kwargs): """ 使用requests对网址发送请求,并将请求结果存储 :param url: 网址 :param path: 存储文件路径 :param encoding: 文件编码,默认utf-8 """ response = requests.get(url, **kwargs) if response.ok: response.encoding = encoding with open(path, "w", encoding=encoding) as f_w: f_w.write(response.text) url = r"https://www.baidu.com/" headers = { "User-Agent": (r"请使用自己的" r"UA识别码"), "Cookie": cookie_handle(cookies_load("百度登录Cookies.json")) } get_and_save(url, "baidu.html", headers=headers)2)、使用cookies参数 值得注意的是,传入的cookies是一个字典,那么就需要对已有的cookies数据进行处理,将其转化成requests能够识别的字典数据类型 预处理Cookies格式: def cookie_handle(cookies: list): """ cookies 转化为字典函数 :param cookies: selenium获取的cookies """ dic = {} for i in cookies: dic[i["name"]] = i["value"] return dic使用requests发送请求: import os import json import requests def cookies_load(path, encoding="utf-8"): if os.path.isfile(path): with open(path, "r", encoding=encoding) as f_r: cookies = json.load(f_r) return cookies def cookie_handle(cookies: list): """ cookies 转化为字典函数 :param cookies: selenium获取的cookies """ dic = {} for i in cookies: dic[i["name"]] = i["value"] return dic def get_and_save(url, path, encoding="utf-8", **kwargs): """ 使用requests对网址发送请求,并将请求结果存储 :param url: 网址 :param path: 存储文件路径 :param encoding: 文件编码,默认utf-8 """ response = requests.get(url, **kwargs) if response.ok: response.encoding = encoding with open(path, "w", encoding=encoding) as f_w: f_w.write(response.text) url = r"https://www.baidu.com/" headers = { "User-Agent": (r"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " r"Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.84"), } get_and_save(url, "baidu.html", headers=headers, cookies=cookie_handle(cookies_load("百度登录Cookies.json")))3)、效果:👇 可以看到成功的把登陆的页面返回并将其保存为了 html 文件,超链接基本上也还在
其实很简单,只是将之前代码部分修改即可,去掉了存储Cookies部分,有兴趣的可以自行添加尝试 这里使用cookies参数方式添加cookies数据 import time import requests from selenium import webdriver class BaiduLogin: def __init__(self, url, executable_path): """ 对象初始化 :param url: 百度首页地址 :param executable_path: 浏览器驱动路径 """ self.url = url self.browser = self.start_browser(executable_path) @staticmethod def start_browser(executable_path): return webdriver.Edge(executable_path=executable_path) def start_url(self): self.browser.get(self.url) def find_by_xpath(self, xpath): return self.browser.find_element_by_xpath(xpath) def get_and_save(self, path, encoding="utf-8", **kwargs): """ 使用requests对网址发送请求,并将请求结果存储 :param path: 存储文件路径 :param encoding: 文件编码,默认utf-8 """ cookies = self.cookie_handle(self.browser.get_cookies()) response = requests.get(self.url, cookies=cookies, **kwargs) if response.ok: response.encoding = encoding with open(path, "w", encoding=encoding) as f_w: f_w.write(response.text) @staticmethod def cookie_handle(cookies: list): """ cookies 转化为字典函数 :param cookies: selenium获取的cookies """ dic = {} for i in cookies: dic[i["name"]] = i["value"] return dic def handle_login(self, username, pwd, isverify=False): """ 百度首页登录处理方法 :param username: 用户名 :param pwd: 用户密码 :param isverify: 是否存在网页验证 """ # 点击右上角登录按钮 self.find_by_xpath(r"//a[@id='s-top-loginbtn']").click() time.sleep(1) # 点击用户名登录按钮 self.find_by_xpath(r"//p[@id='TANGRAM__PSP_11__footerULoginBtn']").click() # 向输入框输入账户名 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__userName']").send_keys(username) # 向输入框输入密码 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__password']").send_keys(pwd) # 点击登录按钮 self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__submit']").click() # 手动图形验证等待 input("请手动进行图形验证,完毕后输入任意内容继续运行") if isverify: time.sleep(1) # 点击发送验证码按钮 self.find_by_xpath(r"//input[@id='TANGRAM__29__button_send_mobile']").click() # 等待用户输入手动验证码 vcode = input("请输入六位数验证码:") self.find_by_xpath(r"//input[@id='TANGRAM__29__input_vcode']").send_keys(vcode) # 点击确定按钮 self.find_by_xpath(r"//input[@id='TANGRAM__29__button_submit']").click() def quit(self): # 关闭浏览器 self.browser.quit()调用:👇 target_driver = "msedgedriver.exe" url = r"https://www.baidu.com/" headers = { "User-Agent": (r"请使用自己的" r"UA识别码"), } login = BaiduLogin(url, target_driver) login.start_url() login.handle_login("用户名", "用户密码") login.get_and_save("baidu.html", headers=headers) 六、获取的Cookies配合爬虫框架Scrapy使用💦「难点」在讲解 Scrapy 是如何使用 Cookies 之前,需要先明白在 Settings 文件里面控制 Cookies 开关的属性 COOKIES_ENABLED。注意这个真的很重要,若设置不当将会影响到 Cookies 能否被正确读取 属性状态描述COOKIES_ENABLED 为 True 时「默认」启用 CookiesMiddleware 中间件,自动添加响应CookiesCOOKIES_ENABLED 为 False 时关闭 CookiesMiddleware 中间件,response 设置的 cookie 失效COOKIES_ENABLED 被注释时「使用默认值」与为 True 时效果相同(一)、源码展示:🍗 1)、关于settings的默认配置 在 scrapy.settings.default_settings 目录下就能看到,其中 COOKIES_ENABLED 的默认值就是 True,DOWNLOADER_MIDDLEWARES_BASE 初始下载中间件为下方所示 2)、关于 Cookies 的中间件 CookiesMiddleware 在 from scrapy.downloadermiddlewares.cookies import CookiesMiddleware 目录下就能看到 因为代码量比较大,为方便文件读取管理,这里将路径常量放置在主代码开头 BASE_DIR = os.path.dirname(os.path.dirname(__file__)) HTML_DIR = os.path.join(BASE_DIR, "Html")来看看模拟登录获取 Cookies 的 Selenium 代码,将会在后面的 Scrapy 中使用 在打开这个百度贴吧这个登录页面的时候,可能存在一直加载网页的情况,注意这影响很大,如果处于一直在加载网页的情况下,会造成后续的代码一直等待其加载完成才会执行在这里编写了一个不等待页面加载直接继续运行方法,在实例化对象时可以使用 no_wait_page 参数控制,此方法原理就是修改页面加载策略大体上代码和之前在 四、利用Selenium进行模拟登录并使用Cookies 和 五、获取的Cookies配合requests使用 所用的是一样的,主要的接口是 get_cookies 方法 class BaiduTieba: def __init__(self, url, executable_path, f_path, t_driver="Chrome", no_wait_page=True): """ 对象初始化 :param executable_path: 浏览器驱动路径 :param f_path: Cookies文件保存路径 :param t_driver: 目标浏览器 :param no_wait_page: 是否开启不等待网页加载继续运行,默认为开启 """ self.t_driver = t_driver self.f_path = f_path self.index_url = url if no_wait_page: self.__no_wait_page() self.browser = self.__start_browser(executable_path) def __start_browser(self, executable_path): if hasattr(webdriver, self.t_driver): return getattr(webdriver, self.t_driver)(executable_path=executable_path) raise ValueError(f"不存在{self.t_driver}浏览器") def __no_wait_page(self): """ 不等待页面加载直接继续运行方法,需要在启动浏览器前调用 :return: """ t_driver = self.t_driver.upper() if hasattr(DesiredCapabilities, t_driver): desired_capabilities = getattr(DesiredCapabilities, t_driver) desired_capabilities["pageLoadStrategy"] = "none" else: raise ValueError(f"不存在{self.t_driver}方法") def start_url(self, url, wait=False, sec=3): """ 浏览器发起请求方法 :param url: 网址 :param wait: 是否等待 :param sec: 等待时长 """ self.browser.get(url) if wait: time.sleep(sec) def find_by_xpath(self, xpath): return self.browser.find_element_by_xpath(xpath) def find_by_id(self, e_id): return self.browser.find_element_by_id(e_id) @staticmethod def send(element, text): """ 向输入框中输入内容 :param element: 需要操作的元素 :param text: 输入的内容 """ element.send_keys(text) def _login(self, username: str, password: str, isverify=False): """ 百度首页登录处理方法 :param username: 用户名 :param password: 用户密码 :param isverify: 是否存在网页验证 """ self.start_url(self.index_url, wait=True) # 点击账户密码登陆按钮 self.find_by_id("TANGRAM__PSP_4__footerULoginBtn").click() # 输入账户名 self.send(self.find_by_id("TANGRAM__PSP_4__userName"), username) # 输入账户密码 self.send(self.find_by_id("TANGRAM__PSP_4__password"), password) # 点击登陆按钮 self.find_by_id("TANGRAM__PSP_4__submit").click() # 手动图形验证等待 input("请手动进行图形验证,完毕后[或无图形验证直接]输入任意内容继续运行") if isverify: time.sleep(1) # 点击发送验证码按钮 self.find_by_id(r"TANGRAM__19__button_send_mobile").click() # 等待用户输入手动验证码 vcode = input("请输入六位数验证码:") self.find_by_id(r"TANGRAM__19__input_vcode").send_keys(vcode) # 点击确定按钮 self.find_by_id(r"TANGRAM__19__button_submit").click() self.start_url(self.index_url, wait=True) def get_cookies(self, *args, **kwargs): """ 获取Cookies方法 :return: Cookies参数 """ if cookies := self.load_cookies(): return cookies else: self._login(*args, **kwargs) cookies = self.browser.get_cookies() self.save_cookies(cookies) return cookies def save_cookies(self, data, encoding="utf-8"): """ 百度贴吧Cookies保存方法 :param data: 所保存数据 :param encoding: 文件编码,默认utf-8 """ with open(self.f_path, "w", encoding=encoding) as f_w: json.dump(data, f_w) def load_cookies(self, encoding="utf-8"): """ 百度贴吧Cookies读取方法 :param encoding: 文件编码,默认utf-8 """ if os.path.isfile(self.f_path): with open(self.f_path, "r", encoding=encoding) as f_r: user_status = json.load(f_r) return user_status为了便于展示结果,并不过多使用Scrapy的功能,列如管道存储。采用与配合 requests 使用时的相同方式 将网页源码保存成Html文件进行讲解 其实 Scrapy 使用 Cookies 的方式与 requests 类似,也存在 请求头 和 cookies 参数的这两种方式,以爬取百度贴吧的数据为例,我将演示如何通过 Selenium 模拟登录先获取到 Cookies,再将获取到的 Cookies 放入 Scrapy 中进行爬取 通过请求头方式 在生成爬虫文件夹下的爬虫文件中,主要观察 start_requests 方法,在发起请求时 scrapy.Request(headers=headers) cookies 数据放在请求头 headers 参数里 特别注意的是,当将 cookies 放入请求头里进行请求时,settings.COOKIES_ENABLED 此选项一定要设置为 False,使请求头中的 cookies 能够生效 详情请对照 六、获取的Cookies配合爬虫框架Scrapy使用 开头的表 class TiebaSpider(scrapy.Spider): name = 'tieba' # allowed_domains = ['https://www.bilibili.com/'] start_urls = [] index_url = r"https://tieba.baidu.com/index.html" target_driver = os.path.join(BASE_DIR, r"webdrives/chromedriver.exe") tieba_cookies_path = os.path.join(BASE_DIR, r"百度贴吧登录Cookies.json") headers = { "User-Agent": (r"请使用自己的" r"UA识别码") } @staticmethod def cookie_handle(cookies: list): """ cookies 标头格式化处理函数 :param cookies: selenium获取的cookies """ cookies = [f"{i['name']}={i['value']}" for i in cookies] return "; ".join(cookies) def get_cookies(self, *args, **kwargs): baidu = BaiduTieba(self.index_url, self.target_driver, self.tieba_cookies_path) return baidu.get_cookies(*args, **kwargs) def start_requests(self): # 百度贴吧网址模板 template_url = "https://tieba.baidu.com/f?kw={0}&ie=utf-8&pn={1}" # 定义贴吧名称以及需要爬取多少页 tieba_name, pages = "图拉丁", 5 # 获取cookies并对其进行格式化处理 cookies = self.cookie_handle(self.get_cookies("18122990667", "38652706c")) self.headers.update({"Cookie": cookies}) for i in range(pages): # 当前页 c_page = i + 1 # 贴吧以每50分一页 i *= 50 url = template_url.format(tieba_name, i) yield scrapy.Request( url, callback=self.parse, headers=self.headers, meta={"c_page": c_page, "c_name": tieba_name} ) def parse(self, response): """ 解析响应内容,并将其保存为html文件 :param response: 请求响应 """ c_page, c_name = response.meta.get("c_page"), response.meta.get("c_name") # 拼接文件路径 file_path = os.path.join(HTML_DIR, f"百度贴吧_{c_name}_{c_page}页.html") # 判断保存文件夹是否存在,否则创建 if not os.path.isdir(HTML_DIR): os.mkdir(HTML_DIR) # 保存文件 with open(file_path, "wb") as f: f.write(response.body)使用cookies参数 在生成爬虫文件夹下的爬虫文件中,主要观察 start_requests 方法,在发起请求时 scrapy.Request(headers=headers, cookies=cookies) 使用到了 Cookies 参数 特别注意的是,当使用 Cookies 参数时,settings.COOKIES_ENABLED 此选项一定要设置为 True,在默认注释状态下即为 True,即不需要做出更改。scrapy 会将请求响应 Cookies 与我们添加的 Cookies 进行合并 详情请对照 六、获取的Cookies配合爬虫框架Scrapy使用 开头的表 class TiebaSpider(scrapy.Spider): name = 'tieba' # allowed_domains = ['https://www.bilibili.com/'] start_urls = [] index_url = r"https://tieba.baidu.com/index.html" target_driver = os.path.join(BASE_DIR, r"webdrives/chromedriver.exe") tieba_cookies_path = os.path.join(BASE_DIR, r"百度贴吧登录Cookies.json") headers = { "User-Agent": (r"请使用自己的" r"UA识别码") } @staticmethod def cookie_handle(cookies: list): """ cookies 转化为字典函数 :param cookies: selenium获取的cookies """ dic = {} for i in cookies: dic[i["name"]] = i["value"] return dic def get_cookies(self, *args, **kwargs): baidu = BaiduTieba(self.index_url, self.target_driver, self.tieba_cookies_path) return baidu.get_cookies(*args, **kwargs) def start_requests(self): # 百度贴吧网址模板 template_url = "https://tieba.baidu.com/f?kw={0}&ie=utf-8&pn={1}" # 定义贴吧名称以及需要爬取多少页 tieba_name, pages = "图拉丁", 5 # 获取cookies并对其进行格式化处理 cookies = self.cookie_handle(self.get_cookies("18122990667", "38652706c")) for i in range(pages): # 当前页 c_page = i + 1 # 贴吧以每50分一页 i *= 50 url = template_url.format(tieba_name, i) yield scrapy.Request( url, callback=self.parse, headers=self.headers, cookies=cookies, meta={"c_page": c_page, "c_name": tieba_name} ) def parse(self, response): """ 解析响应内容,并将其保存为html文件 :param response: 请求响应 """ c_page, c_name = response.meta.get("c_page"), response.meta.get("c_name") # 拼接文件路径 file_path = os.path.join(HTML_DIR, f"百度贴吧_{c_name}_{c_page}页.html") # 判断保存文件夹是否存在,否则创建 if not os.path.isdir(HTML_DIR): os.mkdir(HTML_DIR) # 保存文件 with open(file_path, "wb") as f: f.write(response.body)(三)、效果展示:🌕 1)、保存的Html文件目录 存放根目录下的 Html 文件夹里 2)、页面展示: 可以看到页面已经成功加载了,但细心点的同学会发现,为什么右上角没有显示账号,那么是否已经返回了登录成功的页面? 因为在上述的内容中并没有编写判断Cookies是否失效的方法,失效最明显的体现就是,添加所保存的Cookies后账号是否还能登录成功。如果登录失败请自行删除保存的 Cookies json文件即可重新登录Cookies 文章是在 2021年08月29日 发布的,并在第二期 C站英豪榜之Python技术征文|超全选题版 中荣幸获奖。说来惭愧,当时在参与活动时并没有将本文中的 Cookies配合爬虫框架Scrapy 部分写完,原以为能够在活动结算前写完,当因太忙,直到 2021年10月12日 才将本文完结,在这里和大家道个歉,很抱歉拖了这么久😌,谢谢大家对我的鼓励以及支持🧡,也感谢 CSDN 官方🌺 参考资料💟 书籍: 异步图书 《Selenium 自动化测试完全指南 基于Python》 这是一本2021年5月新出的书,各方面写的很全,对于学习爬虫或则自动化测试的同学一定不要错过 官方手册 Selenium with Python中文翻译文档Requests: 让 HTTP 服务人类 维基百科中文版: Cookie 浏览器驱动: edge 浏览器驱动chrome 浏览器驱动由衷感谢💖 相关博客😏 《Python Selenium.WebDriverWait 清除输入框再输入『详解』》《Python Selenium.WebDriverWait 判断元素是否存在》 |






 4)、结合之前Selenium百度模拟登录使用🎮
4)、结合之前Selenium百度模拟登录使用🎮
 (二)、Scrapy 如何使用 Cookies:🐔
(二)、Scrapy 如何使用 Cookies:🐔
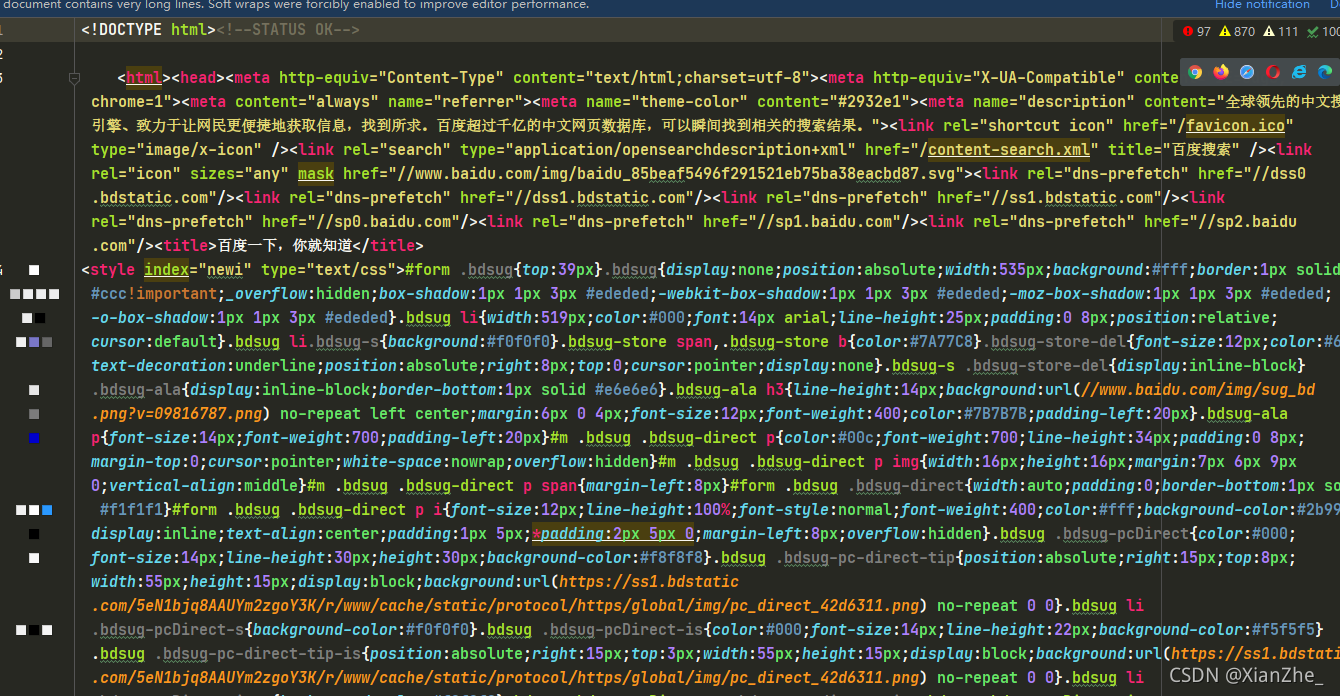
 让咱来看看页面源码,注意看第28行到39行,其实这些就是我们账号的信息,在 PageData 中 user 对象下的 name 属性就是咱的用户名 其实已成功的返回了登录后的页面响应,账号信息都在页面源码内,而没有加载出来应该是页面脚本动态加载问题
让咱来看看页面源码,注意看第28行到39行,其实这些就是我们账号的信息,在 PageData 中 user 对象下的 name 属性就是咱的用户名 其实已成功的返回了登录后的页面响应,账号信息都在页面源码内,而没有加载出来应该是页面脚本动态加载问题  页面源码开头一览
页面源码开头一览 
【本文地址】