| 深度学习 | 您所在的位置:网站首页 › 激活函数的性质和作用是什么 › 深度学习 |
深度学习
|
前两篇的优化主要是针对梯度的存在的问题,如鞍点,局部最优,梯度悬崖这些问题的优化,本节将详细探讨梯度消失问题,梯度消失问题在BP的网络里详细的介绍过(兴趣有请的查看我的这篇文章),然后主要精力介绍RuLU激活函数,本篇还是根据国外的文章进行翻译,然后再此基础上补充,这样使大家更容易理解,好,那就开始了: 分布,该死的分布,还有统计学不同于之前的机器学习方法,神经网络并不依赖关于输入数据的任何概率学或统计学假定。然而,为了确保神经网络学习良好,最重要的因素之一是传入神经网络层的数据需要具有特定的性质。 数据分布应该是零中心化(zero centered)的,也就是说,分布的均值应该在零附近。不具有这一性质的数据可能导致梯度消失和训练动。 最好分布的英文正态的,可能否则导致网络过拟合输入侧空间的某个区域。 在训练过程中,不同批和不同网络层的激活分布,应该保持一定程度上的一致。如果不具备这一性质,那么我们说分布出现了内部协方差偏移(Internal Covariate shift),这可能拖慢训练进程。 这篇文章将讨论如何使用激活函数应对前两个问题。文末将给出一些选择激活函数的建议。 梯度消失
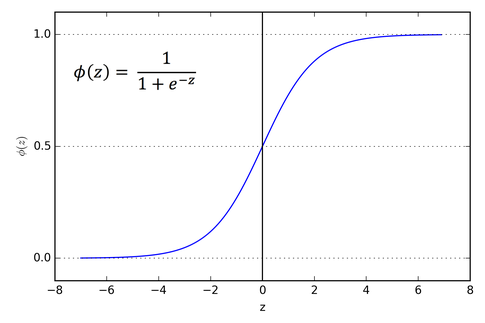
梯度消失问题在神经网络层数相对较多的时会遇到,,梯度消失原因是链式求导,导致梯度逐层递减,我们BP第一节推倒公式时就是通过链式求导把各层连接起来的,但是因为激活函数是SIGMOD函数,取值在1和-1之间,因此每次求导都会比原来小,当层次较多时,就会导致求导结果也就是梯度接近于0。具体如下所示:
上图对应的神经网络的定义为,且 ,则表达式可为:
又因为,因此最大值才为0.25,随着网络的加深,,总体的值越小,因此会发生梯度消失问题,一般解决方法是需要从激活函数或者网络层次着手,如激活函数考虑RELU函数代替SIGMOD函数。 与梯度消失相反的现象称为梯度爆炸,即反向传播中,每层都是大于1,导致最后累乘会很大,梯度爆炸容易解决,一般设定阈值就可以解决。 让我们做一个简单的试验。随机取样50个0到1之间的数,然后将它们相乘。 import random from functools import reduce li = [random.uniform(0,1) for x in range(50) print(reduce(lambda x,y: x*y, li)) 你可以自己试验一下。我试了很多次,从来没能得到一个数量级大于10-18的数。如果这个值是神经元一个梯度的表达式中的一个因子,那么梯度几乎就等于零。这意味着,在较深的架构中,较深的神经元基本不学习,即使学习,和较浅的网络层中的神经元相比,学习的速率极低。 现象这个就是梯度消失问题,较深的神经元中的梯度变为零,或者说,消失了。这就导致神经网络中较深的层学习极为缓慢,或者,在最糟的情况下,根本不学习。 饱和神经元饱和神经元会导致梯度消失问题进一步恶化。假设,传入带sigmoid激活的神经元的激活前数值ωTx+ b非常大或非常小。那么,由于sigmoid在两端处的梯度几乎是0,任何梯度更新基本上都无法导致权重ω和偏置b发生变化,神经元的权重变动需要很多步才会发生。也就是说,即使梯度原本不低,由于饱和神经元的存在,最终梯度仍会趋向于零。如下图
在普通深度网络设定下,RELU激活函数的引入是缓解梯度消失问题的首个尝试(LSTM的引入也是为了应对这一问题,不过它的应用场景是循环模型)。
当x> 0时,ReLU的梯度为1,x |
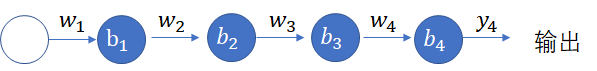


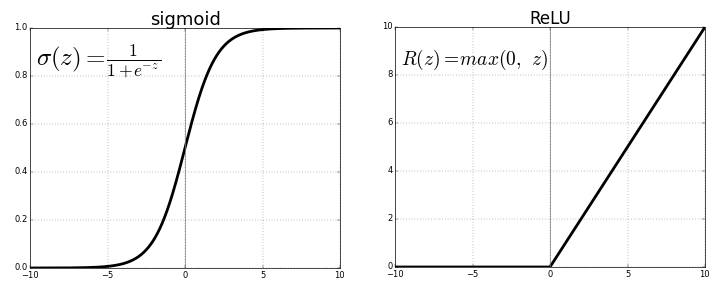
【本文地址】