| 盘点3种Python爬虫中文乱码的处理方法 | 您所在的位置:网站首页 › 浏览器编码设置简体中文就是乱码怎么办 › 盘点3种Python爬虫中文乱码的处理方法 |
盘点3种Python爬虫中文乱码的处理方法
|
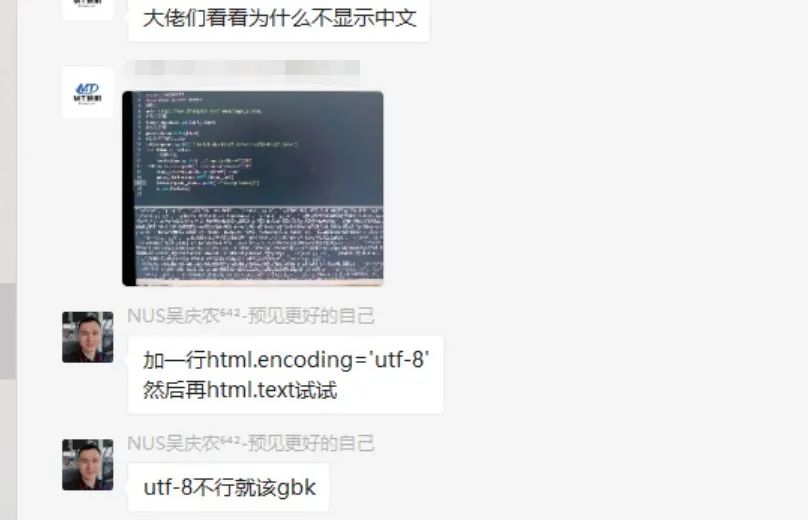
前几天有同学在Python交流群里问了一道关于使用Python网络爬虫过程中出现中文乱码的问题,如下图所示:
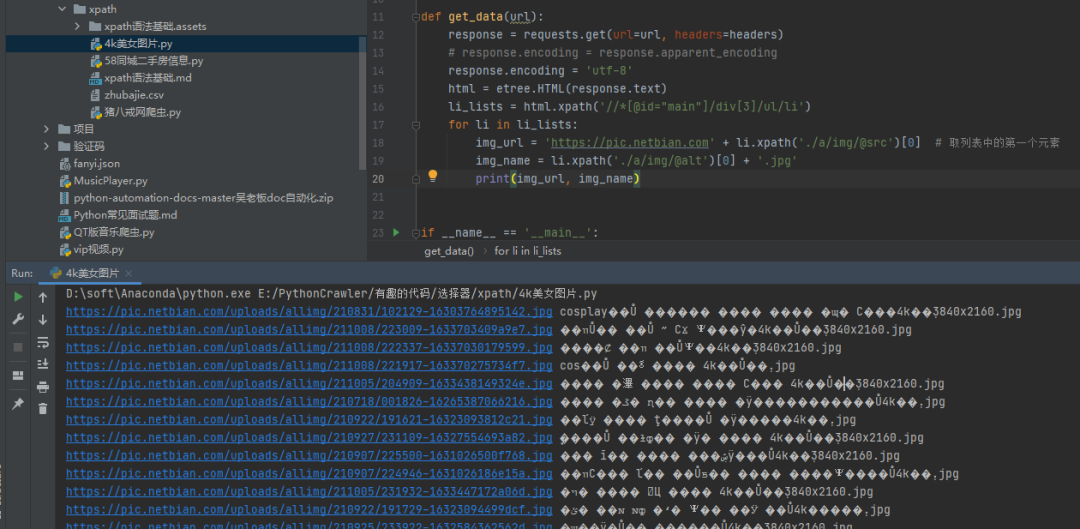
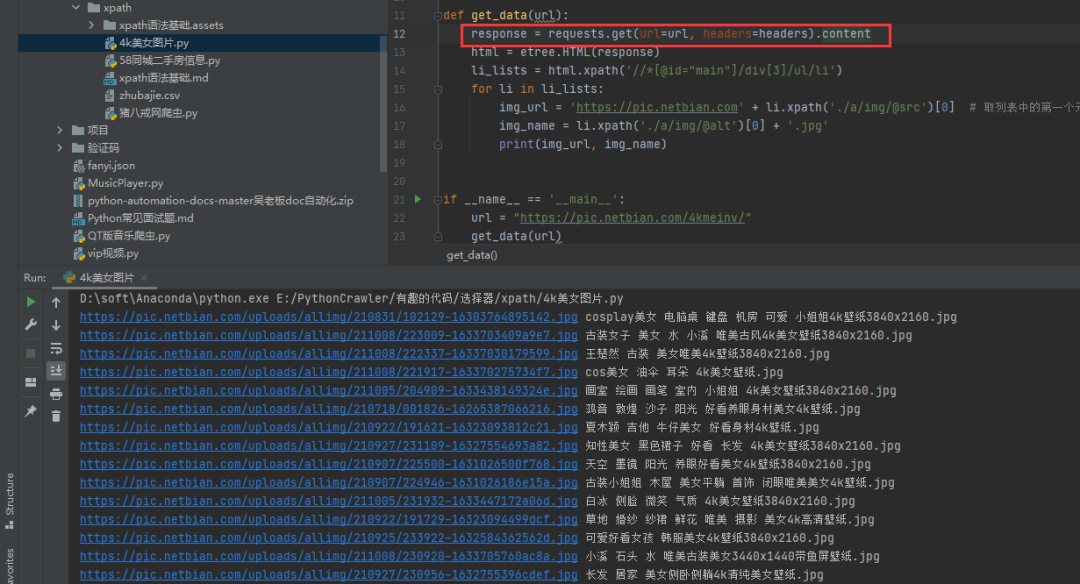
看上去确实头大,对于爬虫初学者来说,这个乱码摆在自己面前,犹如拦路虎一般难顶。不过别慌,这里就给大家整理了三种方法,专门用于针对中文乱码的,希望大家以后再遇到中文乱码的问题时,可以由此得到灵感。 一、思路其实解决问题的关键点就是在于一点,就是将乱码的部分进行处理,而处理的方案主要可以从两个方面进行出发。其一是针对整体网页进行提前编码,其二是针对局部具体中文乱码的部分进行编码处理。这里例举3种方法,肯定还有其他的方法的,也欢迎大家在评论区讨论。 二、分析其实关于中文乱码的表现形式有很多,但是常见的两种如下: 1、当出现网页编码为gbk,获取到的内容在控制台打印类似如下情况的时候: ÃÀÅ® µçÄÔ×À ¼üÅÌ »ú·¿ ¿É°® С½ã½ã4k±ÚÖ½2、当出现网页编码为gbk,获取到的内容在控制台打印类似如下情况的时候: �װŮ�� ��Ů ˮ СϪ Ψ��虽然看上去控制台输出正常,没有报错: Process finished with exit code 0但是输出的中文内容,却不是普通人能看得懂的。 这种情况下的话,就可以通过使用本文给出的三种方法进行解决,屡试不爽。 三、具体实现1)方法一:将requests.get().text改为requests.get().content 我们可以看到通过text()方法获取到的源码,之后进行打印输出的话,确实是会存在乱码的,如下图所示。
此时可以考虑将请求变为.content,得到的内容就是正常的了。
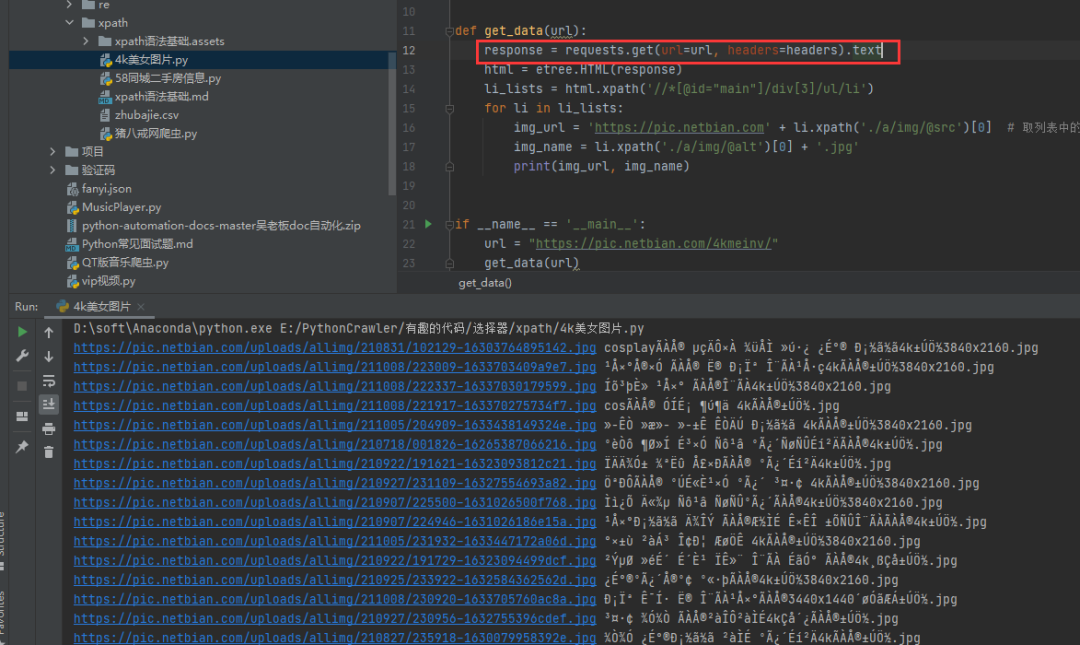
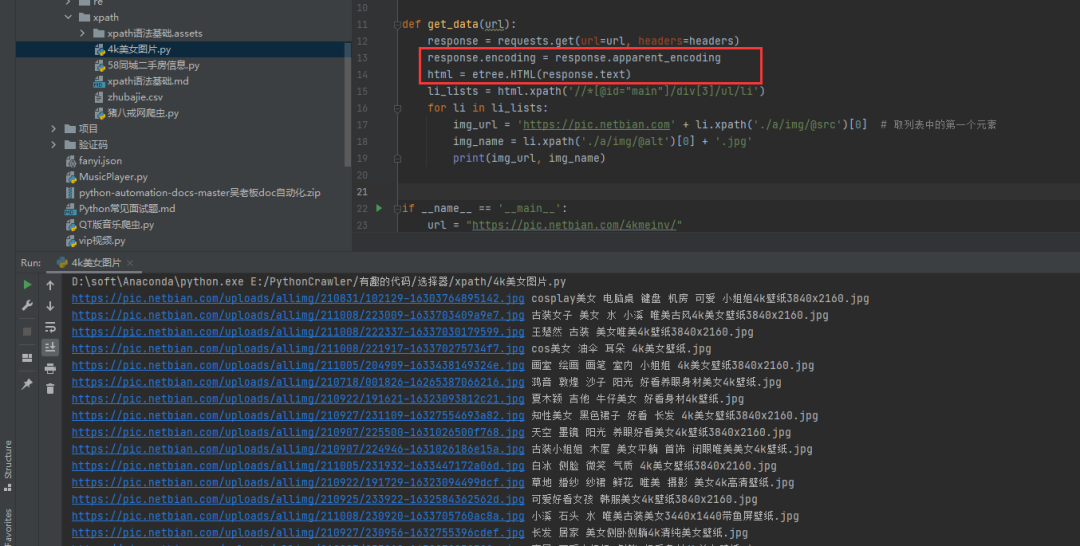
2)方法二:手动指定网页编码**** # 手动设定响应数据的编码格式 response.encoding = response.apparent_encoding
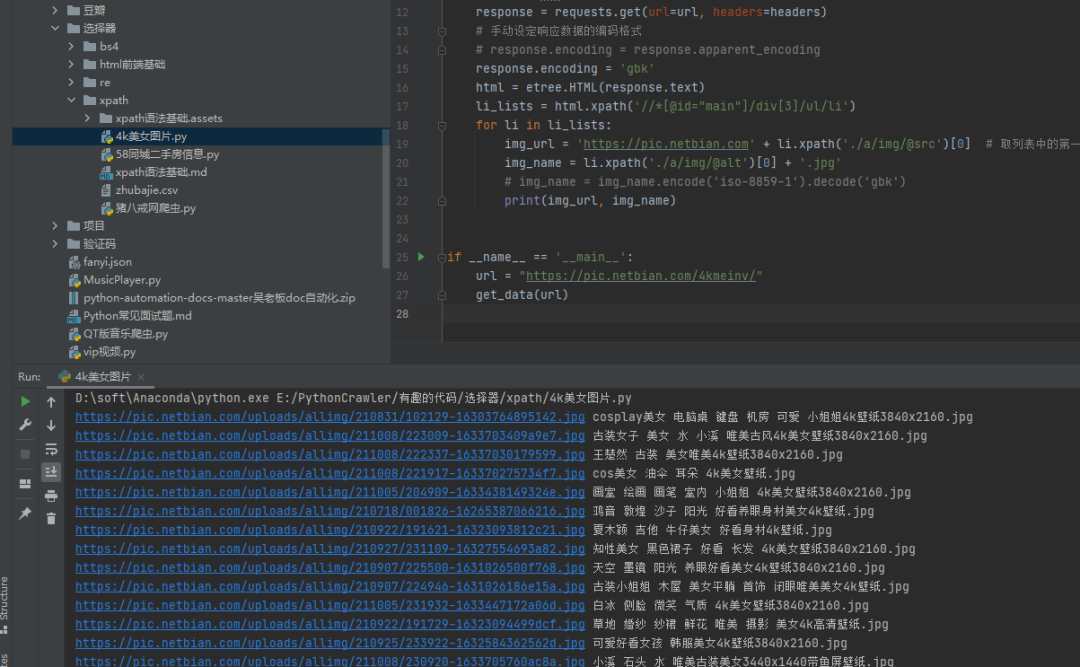
这个方法稍微复杂一些,但是比较好理解,对于初学者来说,还是比较好接受的。 如果觉得上面的方法很难记住,你也可以尝试直接指定gbk编码(或者UTF8)进行处理,如下图所示:
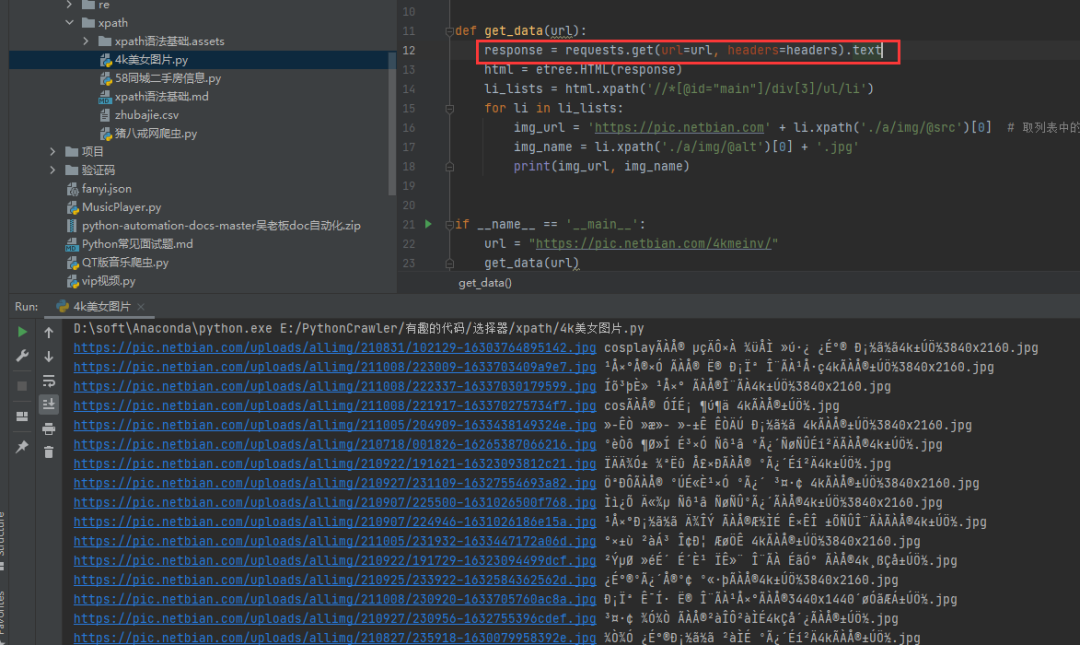
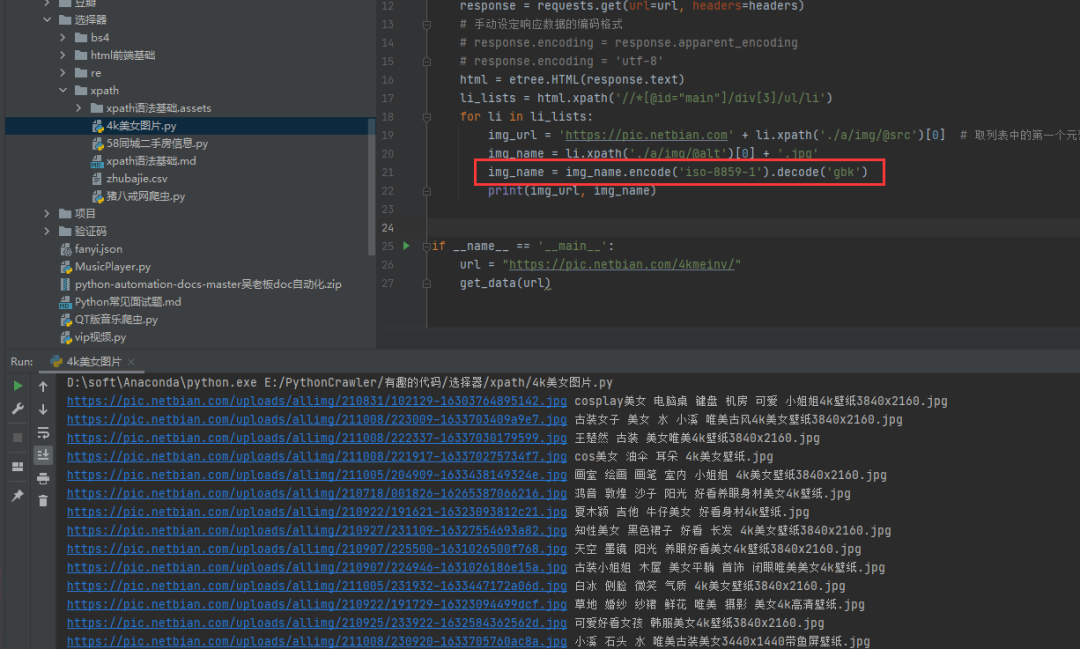
上面介绍的两种方法都是针对网页进行整体编码,效果显著,接下来的第三种方法就是针对中文局部乱码部分使用通用编码方法进行处理。 3)方法三:使用通用的编码方法 img_name.encode('iso-8859-1').decode('gbk')使用通用的编码方法,对中文出现乱码的地方进行编码设定即可。还是当前的这个例子,针对img_name进行编码设定,指定编码并进行解码,如下图所示。
如此一来,中文乱码的问题就迎刃而解了。 四、总结本文针对Python网络爬虫过程中的中文乱码问题,给出了3种乱码解决方法,顺利解决了问题。你还知道有哪些乱码的情况和处理方法,欢迎在评论区中留言。 感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。 一、Python所有方向的学习路线 Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具 工具都帮大家整理好了,安装就可直接上手! 三、最新Python学习笔记 当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集 观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例 纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典

 若有侵权,请联系删除 若有侵权,请联系删除
|








【本文地址】