| 【时间序列】如何去掉时间序列数据中的季节性 | 您所在的位置:网站首页 › 泳装分季节吗 › 【时间序列】如何去掉时间序列数据中的季节性 |
【时间序列】如何去掉时间序列数据中的季节性
|
目录
1 概述2 时间序列中的季节成分3 机器学习的好处4 季节性的类型4 消除季节性5 每日最低温度数据6 差分6.1 每日数据的差分6.2 月平均数据的差分
7 通过建模来进行修正7.1 拟合曲线7.2 移动平均
1 概述
时间序列数据可能包含一些季节性的成分。 这是一个随时间重复的循环,按照月度或者年度。这种重复的循环可能会对我们想要建模预测的信号产生干扰,反之会给我们的模型带来一个非常强的信号。 在这个教程中,我们会学会如何用python 鉴别和修正时间序列中的季节性因素。 完成这个教程,你会知道: 季节性因素的定义和它通过机器学习方法进行预测提供的机会。如何用不同方法来创建季节调整后的每日数据。如何直接对季节成分建模并从在观测中明确减去季节成分。 2 时间序列中的季节成分时间序列数据中包含季节性变化。季节性变化,或者说季节因素,会随时间进行重复。 3 机器学习的好处理解时间序列中的季节成分能够提高我们使用机器学习建模的表现。 主要在两个方面: 更清晰的信号:鉴别和修正时间序列中的季节性成分能够得到输入和输出变量之间更清晰的关系。更多的信息:额外的关于季节成分能够提供新的信息来提高模型的表现。对季节性成分建模,或者去掉时间序列中的季节性成分,都能在我们的试验中起到作用。 4 季节性的类型有多种季节性的类型,比如: 每日时间(Time of Day)每日(Daily)每周(Weekly)每月(Monthly)每年(Yearly)因此,确定时间序列问题中是否存在季节性因素是主观的。 确定是否存在季节性方面的最简单方法是绘制和查看数据,可能采用不同的比例(日、周、年等)并添加趋势线。 4 消除季节性一旦确定了季节性,我们就可以进行建模了。 季节性模型可以从时间序列中删除。此过程称为“季节性调整”(Seasonal Adjustment)或“反季节化”(Deseasonalizing)。 去除了季节性成分的时间序列称为季节性平稳。具有明显季节性成分的时间序列称为非平稳时间序列(non-stationary)。 在时间序列分析领域中,有许多复杂的方法可以研究时间序列中的季节性并从中提取季节性。由于我们主要对预测建模和时间序列预测感兴趣,因此我们仅限于可以在历史数据上开发并在对新数据进行预测时可用的方法。 在本教程中,我们将研究两种对具有强加性季节性成分的经典气象类型日温度问题进行季节调整的方法。接下来,让我们看一下将在本教程中使用的数据集。 5 每日最低温度数据导入数据,并进行可视化。 import pandas as pd import matplotlib.pyplot as plt data_path = 'D:\\jupyter files\\data_practice_python\\' series = pd.read_csv(data_path + 'daily-min-temperatures.csv', header=0, index_col=0) series.plot(figsize=(8, 6)) plt.show()
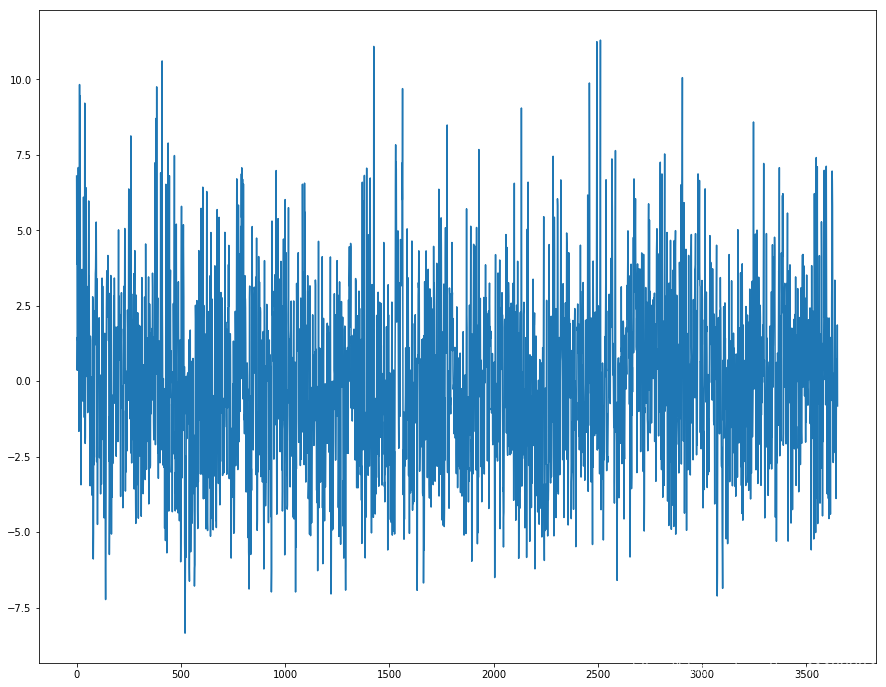
最简单的修正季节性成分的方法是差分(Differencing)。 6.1 每日数据的差分如果在周的级别上存在季节性,那么我们可以通过(今日的数据 - 上周数据)来消除季节性。 对于“每日最低温度”数据集,看起来我们每年都有一个季节性组成部分,显示从夏季到冬季的变化。 我们可以将两年的同一日期的数据相减,从而来对季节性进行修正。我们需要对2月29这个特殊的日期进行处理。 X = series.values diff = list() days_in_year = 365 for i in range(days_in_year, len(X)): value = X[i] - X[i - days_in_year] diff.append(value) fig, ax = plt.subplots(figsize=(15, 12)) ax.plot(diff) plt.show()这是差分之后的结果。 对于第二种方法,我们可以通过将数据集重新采样到每月平均最低温度开始。 注意这里需要加上这一句,因为如果后面使用resample 来对时间进行聚合,那么DataFrame 的Index 的格式必须是datetime-like index。 series.index = pd.to_datetime(series.index)可以看到Index 格式的变化。 series.index [output]: DatetimeIndex(['1981-01-01', '1981-01-02', '1981-01-03', '1981-01-04', '1981-01-05', '1981-01-06', '1981-01-07', '1981-01-08', '1981-01-09', '1981-01-10', ... '1990-12-22', '1990-12-23', '1990-12-24', '1990-12-25', '1990-12-26', '1990-12-27', '1990-12-28', '1990-12-29', '1990-12-30', '1990-12-31'], dtype='datetime64[ns]', name='Date', length=3650, freq=None) monthly_mean = series.resample('M').mean() print(monthly_mean.head(13)) monthly_mean.plot() plt.show() [output]: Temp Date 1981-01-31 17.712903 1981-02-28 17.678571 1981-03-31 13.500000 1981-04-30 12.356667 1981-05-31 9.490323 1981-06-30 7.306667 1981-07-31 7.577419 1981-08-31 7.238710 1981-09-30 10.143333 1981-10-31 10.087097 1981-11-30 11.890000 1981-12-31 13.680645 1982-01-31 16.567742
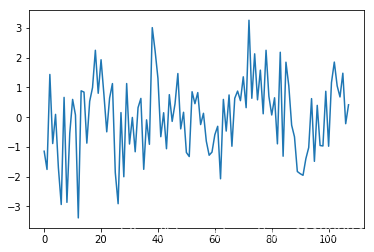
我们可以在月度数据上测试相同的差异方法,并确认经季节性调整的数据集确实确实消除了年周期。 diff = list() months_in_year = 12 for i in range(months_in_year, len(monthly_mean)): value = monthly_mean.Temp.iloc[i] - monthly_mean.Temp.iloc[i - months_in_year] diff.append(value) plt.plot(diff) plt.show()
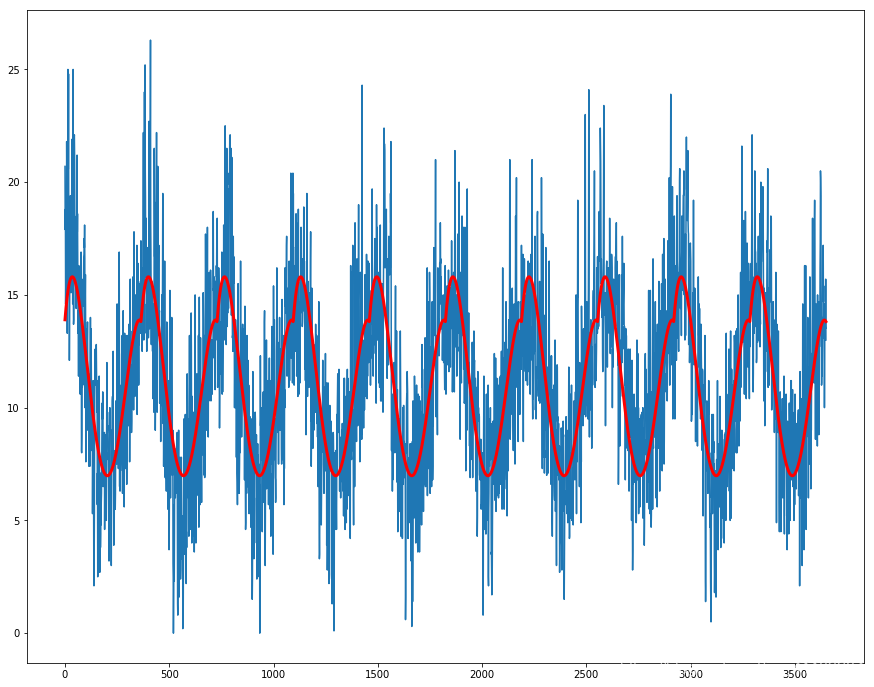
同理,我们也可以使用周平均数据来进行修正。此外,温度数据可能再多个维度上有季节效应,因此我们可以考虑不同的维度。 7 通过建模来进行修正我们可以直接对季节成分进行建模,然后在观察数据中减去建模预测的成分。 给定时间序列中的季节性分量可能是在通常固定的时间段和振幅范围内的正弦波。使用曲线拟合方法可以很容易地将其近似。可以使用正弦波的时间索引作为输入或x 轴,将观测值作为输出或y轴来构建数据集。一旦拟合,该模型就可以用于计算任何时间指数的季节性分量。 对于温度数据,时间索引将是一年中的一天。然后,我们可以为任何历史观测值或将来的任何新观测值估算一年中某天的季节性分量,还可以将该曲线用作通过监督学习算法进行建模的新输入。 7.1 拟合曲线首先,将曲线拟合到“最低每日温度”数据集。NumPy 库提供了polyfit() 函数,该函数可用于将所选顺序的多项式拟合到数据集。 准备好数据集后,我们可以通过调用polyfit() 函数来创建拟合,该函数传递x轴值(一年中的整数),y轴值(温度观测值)和多项式的阶数。顺序控制项的数量,进而控制用于拟合数据的曲线的复杂性。 理想情况下,我们需要最简单的曲线来描述数据集的季节性。对于一致的正弦波状季节性,四阶或五阶多项式就足够了。 结果模型采用以下形式: y = b 1 x 4 + b 2 x 3 + b 3 x 2 + b 4 x 1 + b 1 x 4 + b 5 y = b_{1} x^4 + b_{2} x^3 + b_{3} x^2 + b_{4} x^1 + b_{1} x^4 + b_{5} y=b1x4+b2x3+b3x2+b4x1+b1x4+b5 其中y是拟合值,x 是时间索引(一年中的某天),b1 到b5 是通过曲线拟合优化算法找到的系数。 拟合后,我们将有一组代表模型的系数。然后,我们可以使用此模型为一个观测值,一年观测值或整个数据集计算曲线。 X = [i%365 for i in range(0, len(series))] y = series.Temp.tolist() degree = 4 coef = np.polyfit(X, y, degree) print('Coefficients: %s' % coef) # create curve curve = list() for i in range(len(X)): value = coef[-1] for d in range(degree): value += X[i]**(degree-d) * coef[d] curve.append(value) # plot curve over original data fig, ax = plt.subplots(figsize = (15, 12)) ax.plot(series.values) ax.plot(curve, color='red', linewidth=3) plt.show()
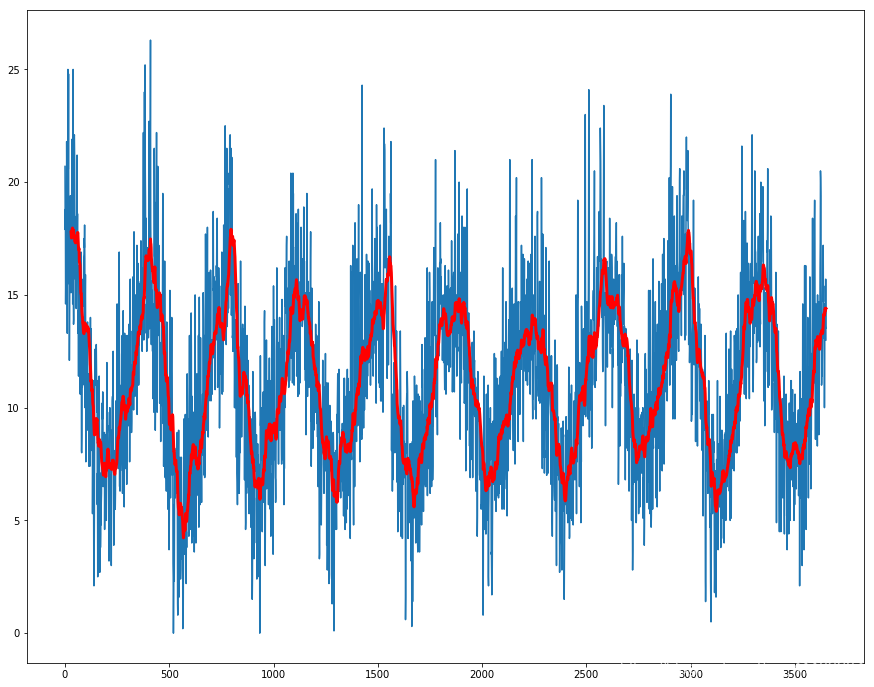
运行示例将创建数据集,拟合曲线,预测数据集中每一天的值,然后在原始数据集(蓝色)的顶部绘制所得的季节性模型(红色)。 该模型的局限性在于它没有考虑leap日,而是增加了较小的偏移噪声,可以通过对该方法进行更新轻松地对其进行校正。例如,我们可以在创建季节性模型时从数据集中删除两个2月29日的观测值。该曲线似乎非常适合数据集中的季节性结构。现在,我们可以使用此模型创建数据集的季节性调整版本。 7.2 移动平均我们也可以使用移动平均来进行简单的建模。 moving_ave = series.rolling(30).mean() # plot curve over original data fig, ax = plt.subplots(figsize = (15, 12)) ax.plot(series.values) ax.plot(moving_ave.values, color='red', linewidth=3) plt.show()
下面列出了完整的示例。 X = [i%365 for i in range(0, len(series))] y = series.Temp.tolist() degree = 4 coef = np.polyfit(X, y, degree) print('Coefficients: %s' % coef) # create curve curve = list() for i in range(len(X)): value = coef[-1] for d in range(degree): value += X[i]**(degree-d) * coef[d] curve.append(value) # plot curve over original data fig, ax = plt.subplots(figsize = (15, 12)) ax.plot(series.values) ax.plot(curve, color='red', linewidth=3) plt.show()
|
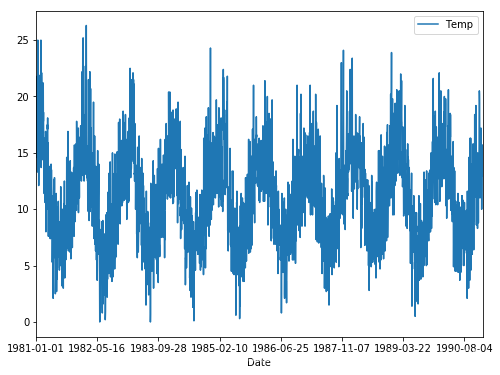
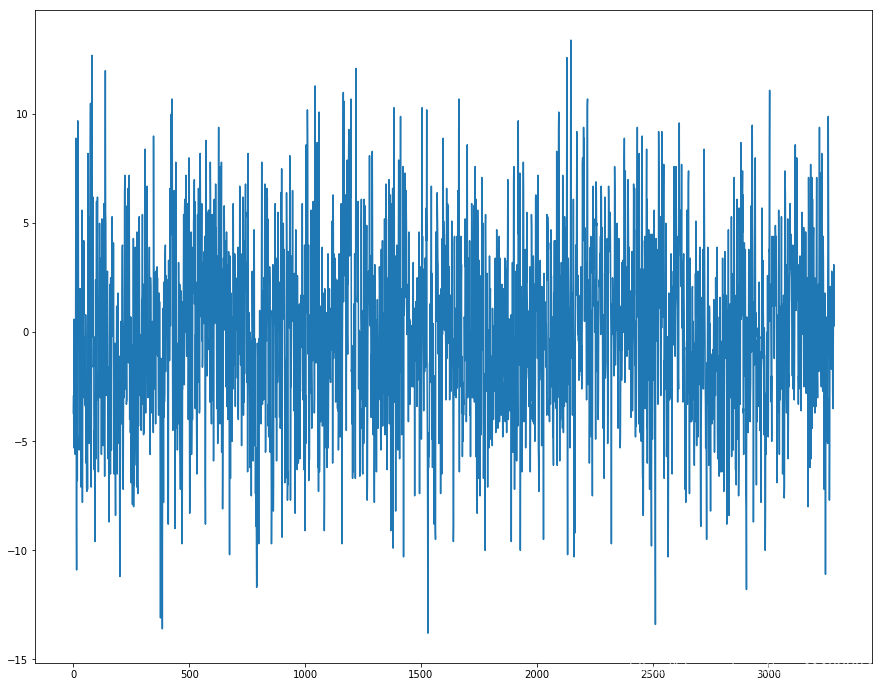 我们的数据集中有两个闰年(leap year)——1984年和1988年。没有明确处理它们;这意味着从1984年3月开始的偏移量有一天是错误的,而从1988年3月以后,偏移量有2天是错误的。
我们的数据集中有两个闰年(leap year)——1984年和1988年。没有明确处理它们;这意味着从1984年3月开始的偏移量有一天是错误的,而从1988年3月以后,偏移量有2天是错误的。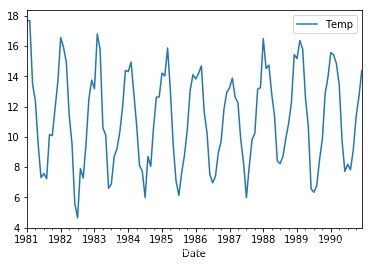 对于日数据的修正。我们可以使用每月的平均数据来对每日的数据进行调整。使用月度平均来进行修正,相比于使用日数据进行修正要更加稳定。对于像闰年2月29 日的数据展示出鲁棒性。
对于日数据的修正。我们可以使用每月的平均数据来对每日的数据进行调整。使用月度平均来进行修正,相比于使用日数据进行修正要更加稳定。对于像闰年2月29 日的数据展示出鲁棒性。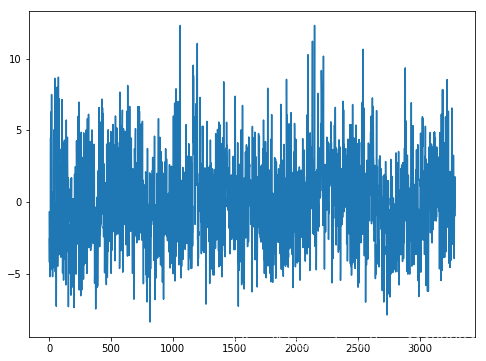
 参考资料: https://machinelearningmastery.com/time-series-seasonality-with-python/
参考资料: https://machinelearningmastery.com/time-series-seasonality-with-python/【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |