| Pandas的基础操作:常用函数(求均值,方差,求和,众数,统计元素个数等)/分组运算groupby操作/透视表 | 您所在的位置:网站首页 › 求平均数常用的两种方法 › Pandas的基础操作:常用函数(求均值,方差,求和,众数,统计元素个数等)/分组运算groupby操作/透视表 |
Pandas的基础操作:常用函数(求均值,方差,求和,众数,统计元素个数等)/分组运算groupby操作/透视表
|
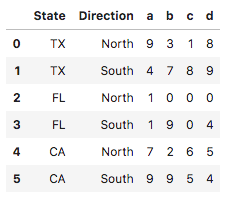
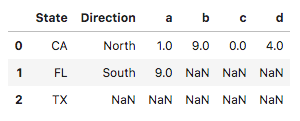
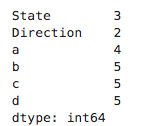
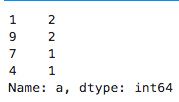
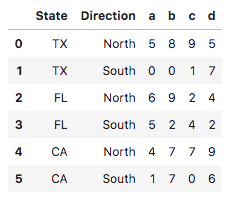
刚刚使用Python进行数据分析,分享一些概念和想法,希望可以大家一起讨论,如果理解或者表达有不准确的地方,请多多指点,不吝赐教,非常感谢~~ 本文将介绍Pandas操作的最后一个部分,前两篇分别是: 《Pandas的基础操作:介绍/创建/查看数据/赋值/常用函数》:https://blog.csdn.net/weixin_42969619/article/details/96863875 《Pandas的基础操作:合并数据.merge()函数的使用》:https://blog.csdn.net/weixin_42969619/article/details/97132359 《Pandas的基础操作:排序/设置行索引》:https://blog.csdn.net/weixin_42969619/article/details/97113118 **在之前的文章里介绍了一些pandas常用函数的接口,略有修改,表格如下: 常用接口参数返回值说明1data.mean()axis=0/1默认值为0Series求列平均值2data.std()axis=0/1默认值为0Series求每列的标准差3data.var()axis=0/1默认值为0Series求每列的方差4data.median()axis=0/1默认值为0Series求每列的中位数5data.min()axis=0/1默认值为0Series求每列的最小值6data.max()axis=0/1默认值为0Series求每列的最大值7data.sum()axis=0/1默认值为0DataFrame/Series对每列求和8data.cumsum()axis=0/1默认值为0DataFrame/Series对每行进行累加9data.count()axis=0/1默认值为0DataFrame/Series按列统计非空元素个数10data.nunique()axis=0/1默认值为0int/Series统计Series中不同值的个数/统计DataFrame中每列中几个不同值11data_series.mode()Series常用在返回对Series中出现最多的元素12data_series.unique()ndarray只能用在统计Series中存在的不重复元素13data_series.value_counts()Series只能用在统计Series中每个元素出现的次数以下列数据作为例子: # np.random.seed(1) index = pd.MultiIndex.from_product([['TX', 'FL', 'CA'], ['North', 'South']], names=['State', 'Direction']) data = pd.DataFrame(index=index, data=np.random.randint(0, 10, (6,4)), columns=list('abcd')) data.reset_index(inplace=True) data
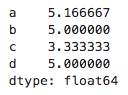
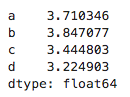
仍然上面的代码作为例子:(但是由于没有设置随机数种子,所以以下面的数据作为参考)
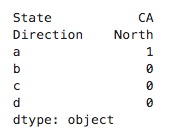
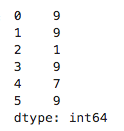
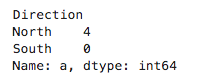
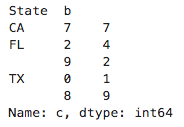
data.a.min()的结果是0 多层分组运算: data.groupby(["State","b"]).c.sum()
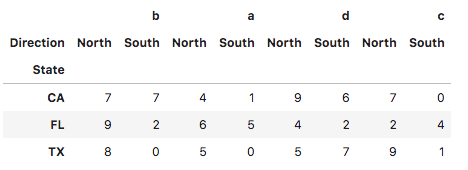
data.c.sum()的结果是23 11. 数据透视表命令格式如下: data.pivot( columns='ColumnToPivot', index='ColumnToBeRows', values='ColumnToBeValues')应用场景:虽然数据可以同多“多层”的index展示,但是还是不够直观,这时可以使用透视表 使用上面的数据作为参考:
pivot命令的输出是一个新的DataFrame,但索引往往是“怪异的”,所以我们通常会.reset_index() |


【本文地址】
公司简介
联系我们