| MySQL知识简单整理(上) | 您所在的位置:网站首页 › 求平均值函数的名称为 › MySQL知识简单整理(上) |
MySQL知识简单整理(上)
一、条件查询
 (一).字符串=某个值的查询。考察条件筛选的能力 比如:
select device_id,university
from user_profile
where university = "北京大学"
(二).其中的列大于数值 > ,可以算是运算判断,包括 24
(三).考between,mysql中,是两边包含的
(一).字符串=某个值的查询。考察条件筛选的能力 比如:
select device_id,university
from user_profile
where university = "北京大学"
(二).其中的列大于数值 > ,可以算是运算判断,包括 24
(三).考between,mysql中,是两边包含的
3.1 select device_id,gender,age from user_profile where age between 20 and 23;3.2注意where age >=20 and age=20 and age >= < 1 AND 班名 LIKE '电子%’ 例22.查询11212P和11214D班所有男生的学号、姓名、性别和班号 SELECT 学号,姓名,性别,班号 FROM 学生表 WHERE (班号= ‘ 11212P ’ OR 班号= ‘ 11214D ’) AND 性别=‘男’也可写为: SELECT 学号,姓名,性别,班号 FROM 学生表 WHERE 班号 IN( ‘ 11212P ’ , ‘ 11214D ’) AND 性别=‘男’ (七).模糊查询 。字符匹配,字段名 like '匹配内容'。一般形式为:列名 [NOT ] LIKE匹配串中可包含如下四种通配符: _:匹配任意一个字符; %:匹配0个或多个字符; [ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达 ); [^ ]:^尖冒号 代表 非,取反的意思;不匹配[ ]中的任意一个字符。 tips:面试常问的一个问题:你了解哪些数据库优化技术? SQL语句优化也属于数据库优化一部分,而我们的like模糊查询会引起全表扫描,速度比较慢,应该尽量避免使用like关键字进行模糊查询。 例23.查询学生表中姓‘张’的学生的详细信息 SELECT * FROM 学生表 WHERE 姓名 LIKE ‘张%’例24.查询姓“张”且名字是3个字的学生姓名。 SELECT * FROM 学生表 WHERE 姓名 LIKE '张__’如果把姓名列的类型改为nchar(20),在SQL Server 2012中执行没有结果。原因是姓名列的类型是char(20),当姓名少于20个汉字时,系统在存储这些数据时自动在后边补空格,空格作为一个字符,也参加LIKE的比较。可以用rtrim()去掉右空格 SELECT * FROM 学生表 WHERE rtrim(姓名) LIKE '张__'例25.查询学生表中姓‘张’、姓‘李’和姓‘刘’的学生的情况。 SELECT * FROM 学生表 WHERE 姓名 LIKE '[张李刘]%’例26.查询学生表表中名字的第2个字为“小”或“大”的学生的姓名和学号。 SELECT 姓名,学号 FROM 学生表 WHERE 姓名 LIKE '_[小大]%'例27.查询学生表中所有不姓“刘”的学生。 SELECT 姓名 FROM 学生 WHERE 姓名 NOT LIKE '刘%’例28.从学生表表中查询学号的最后一位不是2、3、5的学生信息。 SELECT * FROM 学生表 WHERE 学号 LIKE '%[^235]' 二、高级查询 (一)使用聚合函数汇总数据SQL提供的统计函数有: COUNT(【Shift+8】):统计表中元组个数; COUNT([DISTINCT] ):统计本列列值个数; SUM( ):计算列值总和; AVG( ):计算列值平均值; MAX( ):求列值最大值; MIN( ): 求列值最小值。 上述函数中除COUNT(【Shift+8】)外,其他函数在计算过程中均忽略NULL值。 统计函数不能出现在WHERE子句中。 例如,查询成绩最高的学生的学号,如下写法是错误的: SELECT 学号 FROM 成绩表 WHERE 成绩 = MAX(成绩) 例29.统计学生总人数。 SELECT COUNT(*) FROM 学生表例30.统计选修了课程的学生的人数。 SELECT COUNT (DISTINCT 学号) FROM 成绩表例31.计算学号为“11214D24”的学生的考试总成绩之和。 SELECT SUM(成绩) FROM 成绩表 WHERE 学号 = ‘11214D24 '例32.计算“M01F011”课程的学生的考试平均成绩 SELECT AVG(成绩) FROM 成绩表 WHERE 课程号 = ‘M01F011 ‘例33.查询选修了“M01F011” 课程的最高分和最低分 SELECT MAX(成绩) 最高分, MIN(成绩) 最低分 FROM 成绩表 WHERE 课程号 = ‘M01F011 '补充: ROUND() 函数 ROUND 函数用于把数值字段舍入为指定的小数位数。 SQL ROUND() 语法 round(哪个值,小数点保留几位)。sql里面不区分单、双引号的 (二)关于group by, 对查询结果进行分组计算作用:可以控制计算的级别:对全表还是对一组。 目的:细化计算函数的作用对象。 分组语句的一般形式: [GROUP BY ] [HAVING ] GROUP BY子句中的分组依据列必须是表中存在的列名,不能使用AS子句指派的结果集列的别名,having是可以直接使用别名。但是好像Mysql新版是支持group by、 have 后面直接用别名的? 带有GROUP BY 子句的SELECT语句的查询列表中只能出现分组依据列或统计函数,因为分组后每个组只返回一行结果。 例题:题目:现在运营想要对每个学校**不同性别的用户活跃情况和发帖数量进**行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。 SELECT gender,university,COUNT(*)user_num,AVG(active_days_within_30)avg_active_days, AVG(question_cnt)avg_quesition_cnt FROM user_profile GROUP BY gender,university例34.统计每门课程的选课人数,列出课程号和人数。 SELECT 课程号, COUNT(课程号) AS 选课人数 FROM 成绩表 GROUP BY 课程号该语句首先对查询结果按课程号的值分组,所有具有相同课程号值的元组归为一组,然后再对每一组使用COUNT函数进行计算,求得每组的学生人数。 例35.查询每名学生的选课门数和平均成绩。 SELECT 学号, COUNT(*) 选课门数, AVG(成绩) 平均成绩 FROM 成绩表 GROUP BY 学号面试题拓展:分组SQL语句中,select和from和where和group by 和 having 这几部分的执行顺序是怎么样的? sql语句书写顺序不能颠倒:select···from···where···group by···having···order by···limit··· 答:一般执行顺序是from···where···group by···having···select···order by···limit···; 正确的排序应该是这样的: 先是from(组装来自不同数据源的数据,需要从哪个数据表检索数据), 再到 where(基于指定的条件,对数据进行筛选过滤) , 再到group by(将筛选后的数据划分为多个分组) , 再到having(对上面已经分组的数据进行过滤的条件 ),它的功能有点像WHERE子句,但它用于组而不是单个记录, 最后select(查看结果集中的哪个列,或列的计算结果) order by :按照什么样的顺序来查看返回的数据 。 首先是要确定数据从哪张表来,然后按where条件对数据进行筛选过滤,再然后才能进行group by分组(分组条件可以有多个,按字段顺序依次分组),分组之后由having对结果集进行过滤之后把数据呈现出来。 补充:select 列a,聚合函数(聚合函数规范) from 表名 where 过滤条件 group by 列a 1.group by 字句也和where条件语句结合在一起使用。当结合在一起时,where在前,group by 在后。即先对select xx from xx的记录集合用where进行筛选,然后再使用group by 对筛选后的结果进行分组。 2.使用having字句对分组后的结果进行筛选,语法和where差不多:having 条件表达式 需要注意having和where的用法区别: 1.having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。 2.where肯定在group by 之前,即也在having之前。 3.where后的条件表达式里不允许使用聚合函数,而having可以。 HAVING通常与GROUP BY子句一起使用 当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是: 1.执行where xx对全表数据做筛选,返回第1个结果集。 2.针对第1个结果集使用group by分组,返回第2个结果集。 4.针对第2个结集执行having xx进行筛选,返回第3个结果集。 3.针对第3个结果集中的每1组数据执行select xx,有几组就执行几次,返回第4个结果集。 5.针对第4个结果集排序。 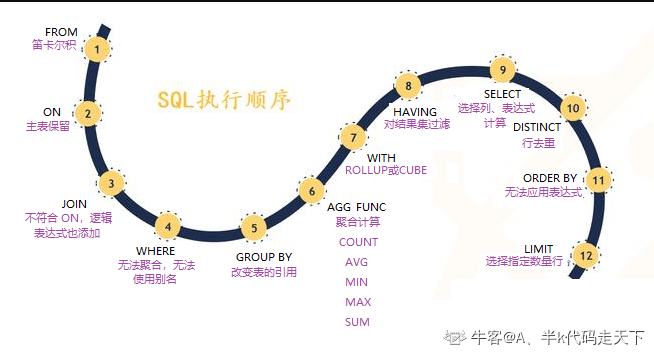
distinct和group by区别 distinct distinct 只能放在查询字段的最前面,不能放在查询字段的中间或者后面。 distinct 对后面所有的字段均起作用,即 去重是查询的所有字段完全重复的数据,而不是只对 distinct 后面连接的单个字段重复的数据。 要查询多个字段,但只针对一个字段去重,使用distinct去重的话是无法实现的。 group by 一般与聚类函数使用(如count()/sum()等),也可单独使用。 group by 也对后面所有的字段均起作用,即 去重是查询的所有字段完全重复的数据,而不是只对 group by后面连接的单个字段重复的数据 三、多表查询 - 多表连接若一个查询同时涉及两个或两个以上的表,则称之为连接查询。 连接查询是关系数据库中最主要的查询。 连接查询包括内连接、外连接和交叉连接等。 连接查询中用于连接两个表的条件称为连接条件或连接谓词。 一般格式为: 
内连接 内连接语法如下: SELECT … FROM 表名 [INNER] JOIN 被连接表 ON 连接条件例39.查询每个学生及其班级的详细信息 SELECT * FROM 学生表 INNER JOIN 班级表 ON 学生表.班号=班级表.班号结果中有重复的列:班号。 例40.去掉例39中的重复列。 SELECT 学号, 姓名,班级表.班号, 班名 FROM 学生表 JOIN 班级表 ON 学生表.班号=班级表.班号例41.查询重修学生的修课情况,要求列出学生的名字、所修课的课程号和成绩。 SELECT 姓名, 课程号, 成绩 FROM 学生表 JOIN 成绩表 ON 学生表.学号 = 成绩表.学号 WHERE 状态 = '重修'执行连接操作的过程 首先取表1中的第1个元组,然后从头开始扫描表2,逐一查找满足连接条件的元组, 找到后就将表1中的第1个元组与该元组拼接起来,形成结果表中的一个元组。 表2全部查找完毕后,再取表1中的第2个元组,然后再从头开始扫描表2, … 重复这个过程,直到表1中的全部元组都处理完毕为止。注:如果为表指定了别名,则查询语句中其他所有用到表名的地方都要使用别名 |
【本文地址】