| 减治法(Decrease and Conquer) | 您所在的位置:网站首页 › 求出平均值的好处是什么 › 减治法(Decrease and Conquer) |
减治法(Decrease and Conquer)
|
减治法
减治法是一种一般性的算法设计技术,它利用了一个问题给定实例的解和同样问题较小实例的解之间的关系。一旦建立了这样一种关系,我们既可以自顶至下(递归)也可以自底至上地运用它(非递归)。 减治法有3种主要的变种: 减一个常量,常常是减1(例如插入排序)。减一个常因子,常常是减去因子2(例如折半查找)。减可变规模(例如欧几里得算法). 插入排序插入排序是减(减1)治法技术在排序问题上的直接应用。无论平均还是最坏,时间复杂度都是 O(n2) ,但在平均情况下效率大约比最差情况快两倍。 该算法一个较为出众的优势在于,对于几乎有序的数组,它的性能是很好的,最佳情况是O(n)。 例如,在用快速排序对数组排序的时候,当子数组的规模变得小于某些预定义的值时,我们可以停止该算法的迭代。此时,数组已经基本有序了,可以用插入排序来完成接下来的工作。一般会减少10%的运行时间。 代码示例看这里。 深度优先查找(DFS)和广度优先查找(BFS)深度优先查找(DFS)和广度优先查找(BFS)是两种主要的图遍历算法。 两种算法都有着相同的时间效率:对于邻接矩阵表示法来说是 O(|V|2) ;对于邻接链表表示法来说是 O(|V|+|E|) 。 DFS重要的基本应用包括检查图的连通性和无环性。因为DFS在访问了所有和初始顶点有路径相连的顶点之后就会停下来,所以可以检查图的连通性,看看是否所有的顶点都被访问过了。检查无环性则是检查是否有访问过的节点再次被到达。BFS可以用来求两个给定顶点间边的数量最少的路径。代码示例看DFS代码和BFS代码。两者的比较看这里。 相关题目 我们可以用一个代表起点的顶点、一个代表终点的顶点、若干个代表死胡同和通道的顶点来对迷宫建模,迷宫中的通道不止一条,我们必须求出连接起点和终点的迷宫道路。 a. 为下面的迷宫构造一个图。 解答: 解答: b. 如果你发现自己身处一个迷宫中,你会选用DFS遍历还是BFS遍历?
拓扑排序 b. 如果你发现自己身处一个迷宫中,你会选用DFS遍历还是BFS遍历?
拓扑排序
一个有向图是一个对边指定了方向的图。拓扑排序要求按照这种次序列出它的顶点,使得对于图中的每一条边来说,边的起始顶点总是排在边的结束顶点之前。当且仅当有向图是一个无环有向图(不包含回路的有向图)的时候,该问题有解,也就是说,它不包含有向的回路。 解决拓扑排序问题有两种算法。第一种算法基于深度优先查找;第二种算法基于减一技术的直接应用,源删除算法。 DFS算法:执行一次DFS遍历,并记住顶点变成死端(即退出遍历栈)的顺序。将该次序反过来就得到了拓扑排序的一个解。
n个元素集合
A={a1,…,an}
的所有
2n
个子集和长度为n的所有
2n
个比特串之间有一一对应关系。建立这样一种对应关系的最简单方法是为每一个子集制定一个比特串,如果
ai
属于该子集,
bi=1
;如果
ai
不属于该子集,
bi=0
。 例如,对于n=3的情况: 生成的排列次序仍然是很不自然的。 如果是挤压序,所有包含aj的子集必须紧排在所有包含{a1,…, aj−1 }的子集后面。 如果是二进制反射格雷码,每一个比特串和它的直接前趋之间仅仅相差一个比特位。 以 A={a1,a2,a3,a4} 比较
写一个生成所有 2n 个长度为n的比特串的递归算法。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include #include #include #include using namespace std; void bit_string_recursive(int n, vector& output, string& cur) { // generate recursively all the bit strings of a given length // input: a positive integer n // output: all bit strings of length n as contents of output if (n == 0) { output.push_back(cur); }else { cur.push_back('0'); bit_string_recursive(n-1, output, cur); cur.pop_back(); cur.push_back('1'); bit_string_recursive(n-1, output, cur); cur.pop_back(); } } int main() { vector output; string cur; bit_string_recursive(3, output, cur); copy(output.begin(), output.end(), ostream_iterator(cout, " ")); cout output.push_back(cur); k = n - 1; while (k >= 0 && cur.at(k) == '1') {--k;} if (k >= 0) { cur[k] = '1'; for (int i = k+1; i < n; ++i) { cur[i] = '0'; } } } } int main() { vector output; bit_string_nonrecursive(3, output); copy(output.begin(), output.end(), ostream_iterator(cout, " ")); cout output.push_back("0"); output.push_back("1"); }else { gray_code(n-1, output); vector copy1(output); vector copy2(output); for_each(copy1.begin(), copy1.end(), [](string& n){n = "0" + n;}); for_each(copy2.begin(), copy2.end(), [](string& n){n = "1" + n;}); copy(copy2.rbegin(), copy2.rend(), back_inserter(copy1)); output = copy1; } } int main() { vector output; gray_code(3, output); copy(output.begin(), output.end(), ostream_iterator(cout, " ")); cout output.push_back(cur); }else { // j < input.size() - k + 1是为了给剩下的几位留出足够的元素。 for (int j = i; j < input.size() - k + 1; ++j) { cur[k-1] = input[j]; choose_k_of_n(input, j+1, k-1, output, cur); } } } int main() { char temp[5] = {'A', 'B', 'C', 'D', 'E'}; vector input(temp, temp+5); vector output; string cur; cur.resize(4); choose_k_of_n(input, 0, 4, output, cur); copy(output.begin(), output.end(), ostream_iterator(cout, " ")); cout weight += coins[i]; } return weight; } //--------------------------------------------------- void find_fake_coin_by_divided_by_3(const vector& coins, int start, int end) { if (start == end-1) // the coin is fake { cout // discard all of them and continue with the coins of the third pile find_fake_coin_by_divided_by_3(coins, div2, end); }else if (weight1 < weight2) // else continue with the lighter of the first two piles { find_fake_coin_by_divided_by_3(coins, start, div1); }else { find_fake_coin_by_divided_by_3(coins, div1, div2); } } } //--------------------------------------------------- int main() { vector coins(10, 5); coins[7] = 3; find_fake_coin_by_divided_by_3(coins, 0, coins.size()); cout if (n % 2 == 1) plus += m; n >>= 1; m return russe_recursive(n/2, 2*m);} else if (n == 1) {return m;} else {return russe_recursive((n-1)/2, 2*m) + m;} } //--------------------------------------------------- int main() { cout swap(array[left], array[right]); ++left; --right; } } left = min(left, end); right = max(right, start); swap(array[start], array[right]); int partition = right; if (partition > k) { return find_kth_smallest_element(array, start, partition-1, k);} else if (partition < k) {return find_kth_smallest_element(array, partition+1, end, k-partition);} else {return array[partition];} } //--------------------------------------------------- int main() { int temp[5] = {40,30,50,10,20}; vector array(temp, temp+5); cout return interpolation_search(datas, inter+1, end, val); }else if (datas[inter] > val) { return interpolation_search(datas, start, inter-1, val); }else { return inter; } } //--------------------------------------------------- int main() { int temp[10] = {1,2,3,4,5,6,7,8,9,10}; vector datas(temp, temp+10); cout public: void pick(vector& piles, int allowed_pick); void single_pick(vector& piles, int allowed_pick); void multi_pick(vector& piles, int allowed_pick); }; //--------------------------------------------------- void Robot::pick( vector& piles, int allowed_pick ) { int no_zero_pile_num(0); for (auto p = piles.begin(); p != piles.end(); ++p) { if (*p){++no_zero_pile_num;} } if (no_zero_pile_num > 1) { multi_pick(piles, allowed_pick); }else { single_pick(piles, allowed_pick); } } //--------------------------------------------------- void Robot::single_pick( vector& piles, int allowed_pick ) { for (int i = 0; i < piles.size(); ++i) { if(!piles[i]) {continue;} int minus(piles[i] % (allowed_pick+1)); // 每次拿走n mod (m+1)个 string helpmsg = minus ? "CalulateSingleRobot(堆,石子): " : "RandomSingleRobot(堆,石子): "; minus = max(1, minus); piles[i] -= minus; cout sum ^= *p; // 计算多堆的二进制数位和是否为0 } if (sum != 0) // 不为0时是胜局,进行计算 { int index(0); // index是从右向左数,第几位不为0 while (!(sum&(1 if (piles[i] & (1 int pile = rand()%piles.size(); int num = rand()%allowed_pick; piles[pile-1] -= min(piles[pile-1], num); cout int pile(0),num(0); auto check = [&]()->bool{ if (pile > piles.size()|| pile == 0 || num > allowed_pick || num > piles[pile-1]) { cout > num; if (!check()) { pick(piles, allowed_pick); }else { piles[pile-1] -= num; } cout cout num && num != -1) { piles.push_back(num); } cout m_allowed_pick; } //--------------------------------------------------- void Game::print_all_piles( const vector& piles ) { cout m_player_first = true; }else { m_player_first = false; } } //--------------------------------------------------- void Game::main_loop() { while (true) { if (m_player_first) { player.pick(piles, m_allowed_pick); print_all_piles(piles); if (!pile_valid()) {m_player_win = true; break;} robot.pick(piles, m_allowed_pick); print_all_piles(piles); if (!pile_valid()) {m_player_win = false; break;} }else { robot.pick(piles, m_allowed_pick); print_all_piles(piles); if (!pile_valid()) {m_player_win = false; break;} player.pick(piles, m_allowed_pick); print_all_piles(piles); if (!pile_valid()) {m_player_win = true; break;} } } } //--------------------------------------------------- bool Game::pile_valid() { int pile_count(0); for_each(piles.begin(), piles.end(), [&](int p){if (p) pile_count+=p;}); if (pile_count == 0) {return false;} return true; } //--------------------------------------------------- void Game::finish() { if (m_player_win){cout game.start(); game.main_loop(); game.finish(); } system("Pause"); } 相关题目另类单堆拈游戏规定谁拿走最后一个棋子就输了。该游戏的其他条件都不变,即该堆棋子有n个,每次每个玩家最多拿走m个,最少拿走1个。请指出游戏的胜局和败局是是怎样的? 答案:败局是n mod (m+1) = 1,胜利的策略是每次拿走(n-1) mod (m+1)的棋子。 坏巧克力。两个玩家轮流掰一块
m×n
格的巧克力,其中一块
1×1
的小块是坏的。每次掰只能顺着方格的边界,沿直线一掰到底。每掰一次,掰的人把两块中不含坏巧克力的那块吃掉,谁碰到最后那块坏巧克力就算输了。这个游戏中,先走还是后走好? 答案:相当于多堆拈游戏,每边到达坏巧克力块的距离就是一堆,然后二进制数位和计算。 翻薄饼。有n张大小互不相同的薄饼,一张叠在另一张上面。允许大家把一个翻板插到一个薄饼下面,然后可以把板上面的这叠薄饼翻个身。我们的目标是根据薄饼的大小重新安排它们的位置,最大的饼要放在最下面。 答案:找到最大的,翻到顶,然后全部翻过来。重复。 [1] 算法设计与分析基础(第2版) |





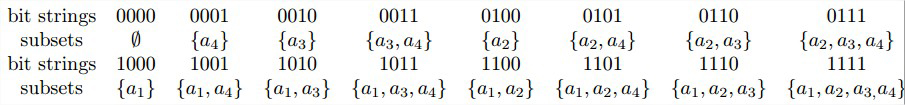

【本文地址】