| 2.3 连续性随机变量 | 您所在的位置:网站首页 › 正态分布是重要的连续型随机变量判断题 › 2.3 连续性随机变量 |
2.3 连续性随机变量
 思维导图:
思维导图:
我会按照以下步骤学习连续型随机变量: 复习概率论的基础知识,包括概率、期望、方差等概念和公式,以及离散型随机变量的概率分布函数和概率质量函数的概念和性质。 学习连续型随机变量的概念和性质,包括概率密度函数、累积分布函数、期望、方差等基本概念和公式。 学习连续型随机变量的分布,包括均匀分布、正态分布、指数分布、伽马分布、卡方分布等,理解它们的定义、概率密度函数、累积分布函数、期望、方差等基本性质,以及如何在实际问题中应用它们。 学习随机变量函数的分布,包括线性变换、平方变换、指数变换等,理解如何通过变换连续型随机变量的概率密度函数来得到新的随机变量的概率密度函数和累积分布函数。 学习连续型随机变量的独立性和相关性,理解如何通过概率密度函数和累积分布函数的乘积来计算独立随机变量的联合分布,以及如何计算相关随机变量的相关系数和协方差。 学习大数定律和中心极限定理,理解它们的意义、基本思想和应用场景,以及如何通过连续型随机变量的概率密度函数和累积分布函数来证明它们。 在学习的过程中,多做例题和习题,加强对概念和公式的理解和记忆,培养运用概率论知识解决实际问题的能力。 总之,学习连续型随机变量需要掌握一定的数学基础,需要有耐心和恒心,同时也需要多思考、多练习,才能真正理解和掌握。
连续性随机变量的概率密度(probability density function)是用于描述该随机变量可能取到某一值的概率分布的函数。与离散型随机变量不同,连续性随机变量可以取无限个可能的值,因此在某个具体的值处的概率为零。 概率密度函数通常用f(x)表示,它描述了在某个区间内该随机变量取值的可能性大小。具体来说,若X是一个连续型随机变量,其概率密度函数为f(x),则对于任意实数a和b(a=0,即概率密度非负;归一性: 其中为连续性随机变量。 另外,连续性随机变量的概率密度函数有以下性质: 概率密度函数处的值表示处的概率密度,但并不等于概率P(X=x),因为连续性随机变量在任何一个点上的概率为0;连续性随机变量的概率密度函数是非负的、可积的实值函数;概率密度函数的积分可以得到随机变量的累积分布函数F(x),即在实际应用中,需要对连续性随机变量进行求期望、方差等操作。由于连续性随机变量取值范围是连续的,因此需要使用定积分的方法对期望、方差等进行求解。
指数分布的无记忆性(Memorylessness)是指在指数分布中,无论过去发生了多久,下一个事件发生的等待时间仍然遵循相同的指数分布。换句话说,指数分布没有"记忆",过去发生的事件对未来事件的发生时间没有影响。 具体来说,如果一个随机变量X服从参数为λ的指数分布,那么对于任意的非负数s和t(s≥0,t≥0),下面的概率等式成立: P(X > s + t | X > s) = P(X > t) 上述等式的意义是,在已经等待了s个单位时间后,再等待t个单位时间的概率等于直接等待t个单位时间的概率。换句话说,已经经历了一段时间的等待并不会影响未来的等待时间。 这种无记忆性的特性在概率论中很有用,它使得指数分布在建模一些随机现象时非常方便。例如,某些类型的可靠性分析和排队论模型中常常使用指数分布来描述事件之间的等待时间。无记忆性的特性意味着我们可以简化计算,而无需考虑过去的历史信息。 需要注意的是,无记忆性只适用于指数分布,不适用于其他类型的分布。在其他分布中,过去的事件可能会对未来事件的发生时间产生影响。因此,在使用指数分布时,我们必须明确了解和确认问题是否适用于无记忆性的假设。 
2023/5/1 补充 3.正态分布正态分布是概率统计学中非常重要的一个概率分布,也称为高斯分布。正态分布在各个领域都有广泛应用,例如自然科学、社会科学、金融、工程学等。 正态分布的概率密度函数具有一个钟形曲线,对称于均值μ,并且标准差σ越大,曲线越平缓。正态分布的概率密度函数公式如下:
其中,$x$是随机变量的取值,$\mu$是分布的均值,$\sigma$是分布的标准差,$e$是自然常数,$\pi$是圆周率。 正态分布的均值、方差和标准差具有以下性质: - 均值$\mu$决定了曲线的位置,即分布的中心; - 标准差$\sigma$决定了曲线的形状,即分布的分散程度; - 方差$\sigma^2$是标准差的平方,也是衡量分布分散程度的指标。 正态分布的累积分布函数可以用标准正态分布的累积分布函数计算得到,标准正态分布是均值为0,标准差为1的正态分布。正态分布的特点是68%的观测值位于均值的一个标准差范围内,95%的观测值位于均值的两个标准差范围内,99.7%的观测值位于均值的三个标准差范围内。 正态分布在实际应用中非常广泛,例如用于描述量化金融、质量控制、人口统计学、物理学和天文学等方面的数据。 我对正态分布的理解:正态分布是一种连续型概率分布,常用于统计学中建立概率模型和进行统计推断。在正态分布中,随机变量呈钟形曲线分布,均值和标准差是控制曲线形状的两个关键参数。 可以这样理解正态分布:当某个随机变量服从正态分布时,大多数的取值会集中在均值附近,随着取值离均值越远,取值出现的概率逐渐变小,而且分布的形状呈钟形曲线。例如,身高、体重、智力等指标往往服从正态分布。 正态分布有很多重要的性质,其中最为著名的是中心极限定理。中心极限定理指出,对于任意分布的独立随机变量,它们的和的分布趋近于正态分布。因此,正态分布在实际中有广泛的应用,例如用于对样本数据的分析、参数估计和假设检验等。 我总结的正态分布的性质: 正态分布标准化公式
常用的连续分布有: 均匀分布(Uniform distribution):在一个区间内概率密度函数相等,区间外为0,常用的是零一均匀分布和对称均匀分布。 正态分布(Normal distribution):具有对称性,常用于自然现象的描述,例如身高、体重、成绩等。 指数分布(Exponential distribution):用于描述独立随机事件发生时间的间隔,例如无故障时间、等待时间等。 伽马分布(Gamma distribution):由多个指数分布相加而成,常用于描述一段时间内某事件发生的次数,例如一天内接到的电话数、医院病人等待手术的时间等。 威布尔分布(Weibull distribution):广泛应用于可靠性分析、寿命分布等领域。 拉普拉斯分布(Laplace distribution):对于峰值大且具有长尾的分布具有更好的拟合效果,常用于金融、经济等领域。 贝塔分布(Beta distribution):常用于描述两个参数(例如甲、乙两组人数)之间的关系,具有自然数学意义。 F分布(F distribution):主要用于方差分析,常用于判断两个样本方差是否相等。 t分布(t distribution):常用于小样本量情况下的统计推断。 以上是常用的连续分布,不同的分布有不同的特点和适用范围,学习时需要了解其概率密度函数、累积分布函数、期望、方差等基本性质。
连续性随机变量的重点难点和易错点主要有以下几点: 概率密度函数的理解和计算:连续性随机变量的概率密度函数是对其可能取值的密度分布描述,而非概率。在计算概率时需要使用累积分布函数,并注意求解定积分的方法。 概率的性质:连续性随机变量概率密度函数的值在某一点处并不代表该点的概率,而是对某一区间的概率密度进行描述。因此,在计算概率时需要考虑区间的范围。 连续性随机变量的期望和方差的计算:与离散性随机变量相比,连续性随机变量的期望和方差的计算需要使用积分的方法,需要注意积分范围和积分方法。 连续性随机变量的分布函数:分布函数是描述随机变量在某一值以下的概率的函数,对于连续性随机变量,可以通过对概率密度函数进行积分得到分布函数。需要注意分布函数的性质和计算方法。 常用的连续分布函数的理解和应用:在应用连续性随机变量时,需要掌握一些常用的连续分布函数的概率密度函数和分布函数,例如均匀分布、正态分布等,需要注意其参数的含义和应用场景。 总之,掌握连续性随机变量的概率密度函数、分布函数、期望和方差的计算方法以及常用的连续分布函数的应用是理解和应用连续性随机变量的关键。需要注意数学计算的准确性和细节问题。
|






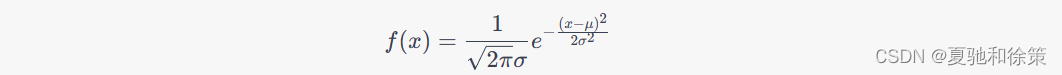





【本文地址】