| 读入 .csv或 Excel 文件,基于 DataFrame 绘制每一列的正态分布图像,以子图的形式放入一个画布 figure 中并进行美化 | 您所在的位置:网站首页 › 正态分布图像怎么做出来的视频 › 读入 .csv或 Excel 文件,基于 DataFrame 绘制每一列的正态分布图像,以子图的形式放入一个画布 figure 中并进行美化 |
读入 .csv或 Excel 文件,基于 DataFrame 绘制每一列的正态分布图像,以子图的形式放入一个画布 figure 中并进行美化
|
目录 一、预处理 1. 引入库 2. 导入数据 编辑 3. 汉字显示 二、自定义函数 三、绘制图像并进行美化 1. 设置画布 1.1 所用函数: 1.2 具体代码: 2. 绘制图像 2.1 部分代码解释 2.2 图像美化 2.3 完整代码及效果图 四、 一些可能会出现的报错 1.绘制其他列图像更改代码时的注意事项(list index out of range) 2. 数据量过大导致报错(Unable to allocate 145. GiB for an array with shape (19450988229,) and data type float64 前不久参加了2022年MathorCup大数据竞赛,选择了 B题:北京移动用户体验影响因素研究,解题过程中,关于问题一数据处理完成后对读入的 DataFrame 每一列绘制正态统计图,写下本文章,记录了部分代码解释和报错问题。 (2022年MathorCup大数据竞赛-赛道B初赛 题目及数据以上传至资源,可直接下载或点击资源描述中的官网下载地址下载) 一、预处理 1. 引入库引入所需要的 Python 库 import pandas as pd import matplotlib.pyplot as plt import numpy as np 2. 导入数据将 .csv 数据文件,读入程序中,保存为 DataFrame 类型(原题附件经过处理之后的数据) (读入 Excel 表格使用:data = pd.read_excel() 函数) tmp = pd.read_csv('...') # 省略号(...)为 .csv 文件路径 print(tmp) # 查看读入数据是否成功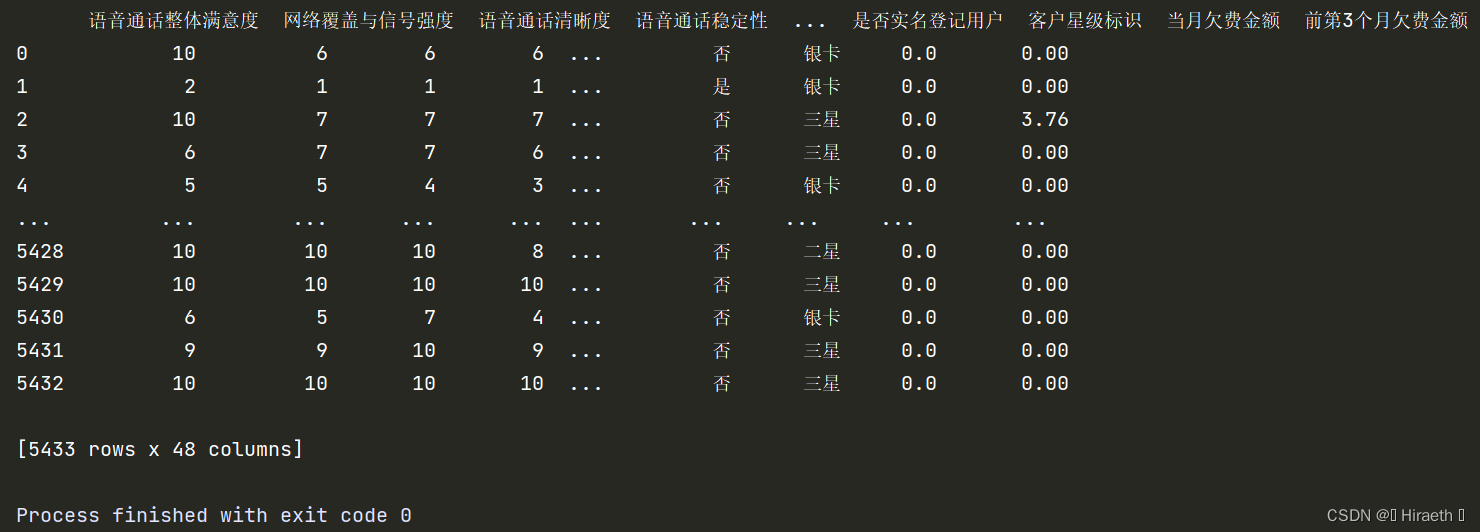
本题中所提供的数据需进行处理后才能进行绘图,本文主要介绍绘图部分,对数据清洗部分省略 3. 汉字显示绘图过程中图像名字涉及汉字,加入下列代码 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False 二、自定义函数为了后续绘图方便,这里首先定义正态分布函数概率密度函数。 正态分布函数概率密度函数数学公式: 注意:left不能大于等于right,bottom不能大于等于top,否则会发生报错 wspace和 hspace则分别表示水平方向上图像间的距离和垂直方向上图像间的距离。这两个参数用于画布有多个子图时。在绘制多个子图时子图与子图之间有时会出现重合的情况,此时使用这两个参数调整间距可解决此问题上子图横坐标和下子图标题重合:调整上下间距 :hspace
右子图纵坐标和左子图重合:调整左右子图间距 :wspace
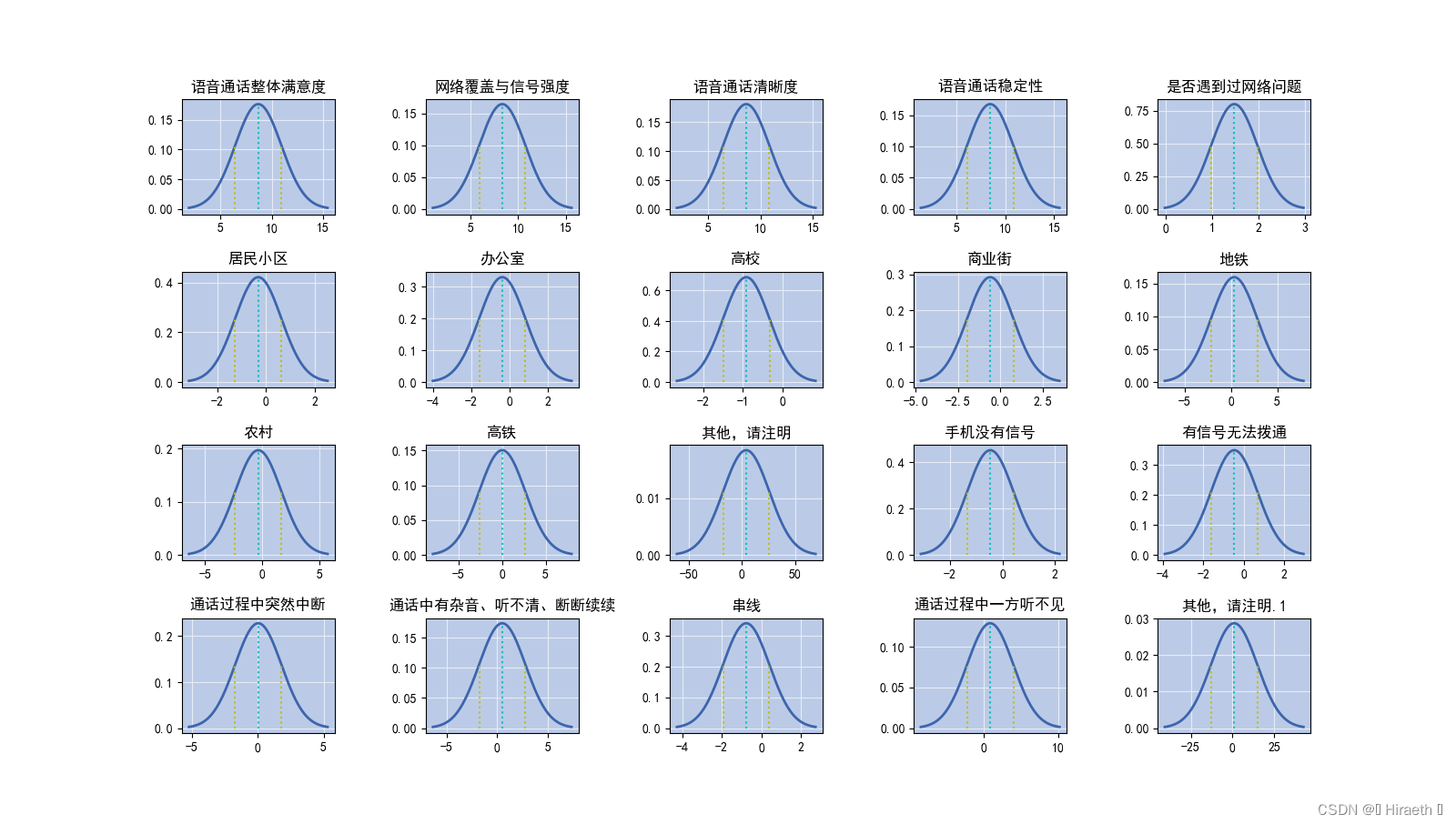
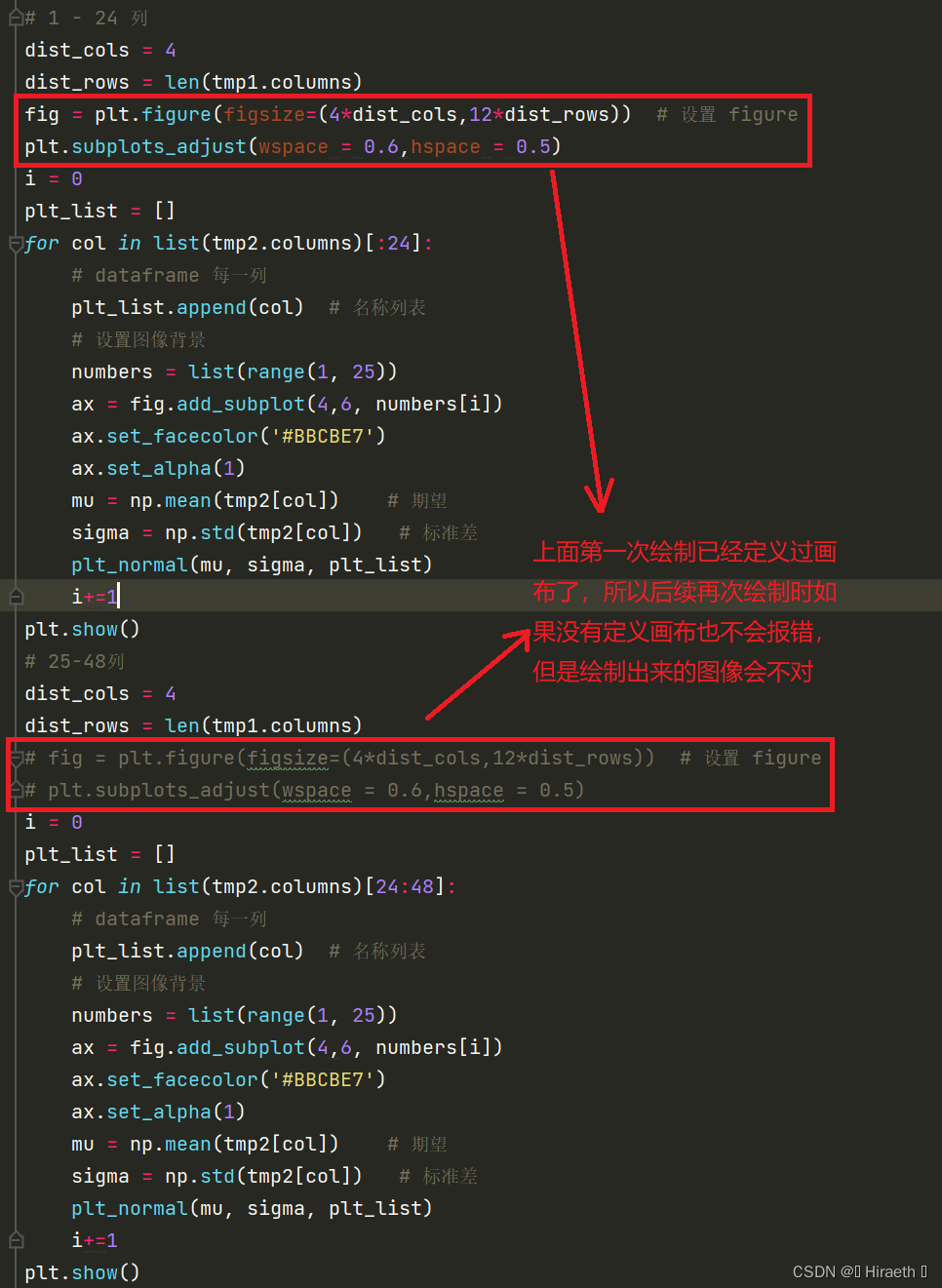
由于要对 DataFrame 每一列进行绘制正态图像,本文采用 for 循环绘制进行每一列的图像 2.1 部分代码解释主题结构: 使用 for 循环一次绘制 20 列的图像(放在一个画布里) i = 0 plt_list = [] for col in list(tmp.columns)[:20]: ########### # 绘图代码 # ########### i+=1 plt.show() 定义一个变量 i ,在循环中进行 +1 操作,用于列表的索引定义一个空列表,在循环中往列表中添加每一列的名称,最后在画图中用 i 进行索引设置为子图的标题循环遍历前 20 列的列索引,依次绘制每一列的正态图如果想让多张图像以子图的形式绘制在一个画布上,plt.show() 要写在 for 循环外面,否则不会显示成功for 循环体内计算绘图部分: 将每次参与循环的数据列索引放入之前定义好的空列表 plt_list 中 : plt_list.append(col) 设置图像子图区域:数据量过大时,一列一列绘图产生的图片过多,可以将画布进行分区,使它们放在一个画布里。这里将每 20 个图像放在了一个 figure 里面 产生一个从 1 开始,最后等于循环次数,也就是绘制子图数量的列表,用于在循环中将图像放在画布不同的位置使用 fig.add_subplot(a,b,c) 对画布进行分区,a,b 代表将画布分成基础绘图代码绘制出的结果并不是很美观,可以根据需要对图像进行美化 设置图像背景颜色: ax.set_facecolor():设置背景颜色,该代码表示颜色使用的是十六进制,也可以使用其他表示颜色的方式ax.set_alpha():用于指定透明度,可以根据自己喜好调整,1 为100% ax.set_facecolor('#BBCBE7') ax.set_alpha(1) 改变网格颜色:将图像背景改变后,默认网格颜色可能会不协调,对网格颜色也可以进行设置 2.3 完整代码及效果图 i = 0 plt_list = [] for col in list(tmp.columns)[:20]: plt_list.append(col) numbers = list(range(1, 21)) ax = fig.add_subplot(4, 5, numbers[i]) ax.set_facecolor('#BBCBE7') ax.set_alpha(1) mu = np.mean(tmp[col]) sigma = np.std(tmp[col]) x = np.arange(mu - 3 * sigma, mu + 3 * sigma, 0.01) y = normal(x, mu, sigma) plt.plot(x, y, '#3D65AD', linewidth=2) plt.title(plt_list[i]) plt.vlines(mu, 0, normal(mu, mu, sigma), colors="c", linestyles="dotted") plt.vlines(mu + sigma, 0, normal(mu + sigma, mu, sigma), colors="y", linestyles="dotted") plt.vlines(mu - sigma, 0, normal(mu - sigma, mu, sigma), colors="y", linestyles="dotted") plt.grid(True, color='#E6ECF6') i+=1 plt.show()
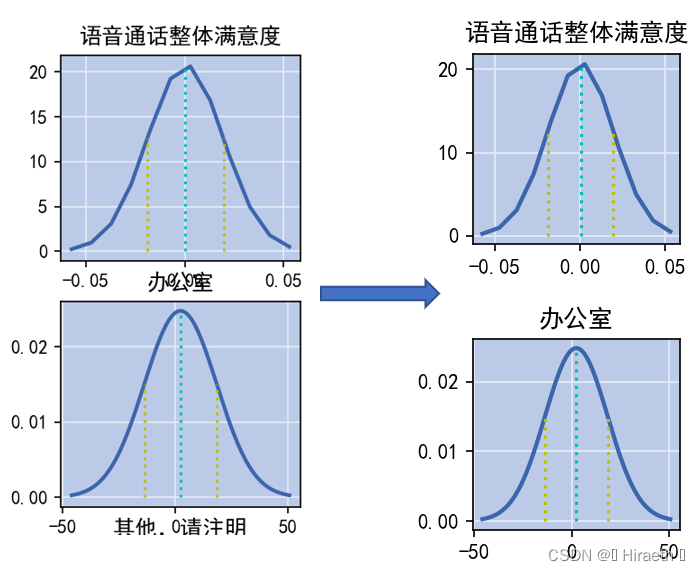
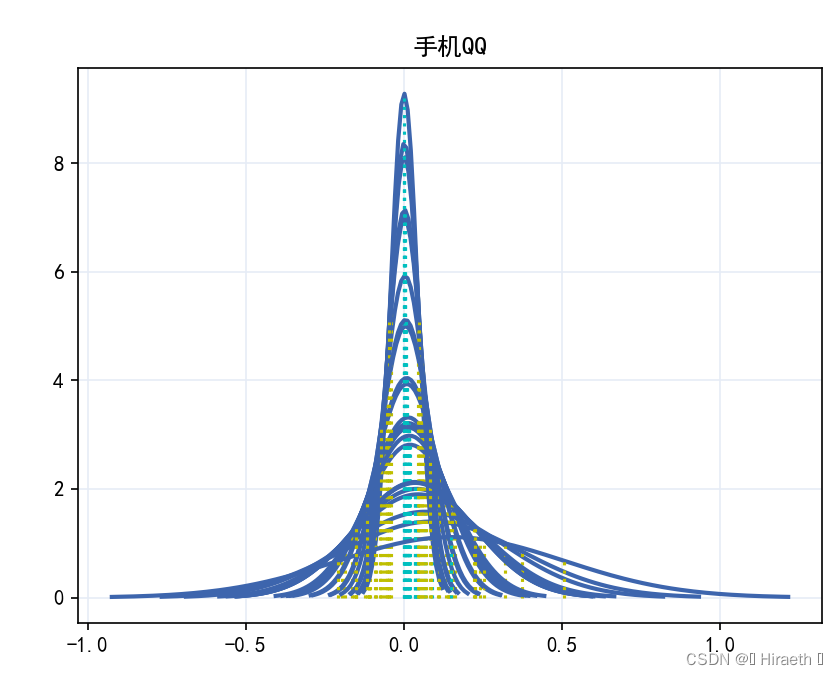
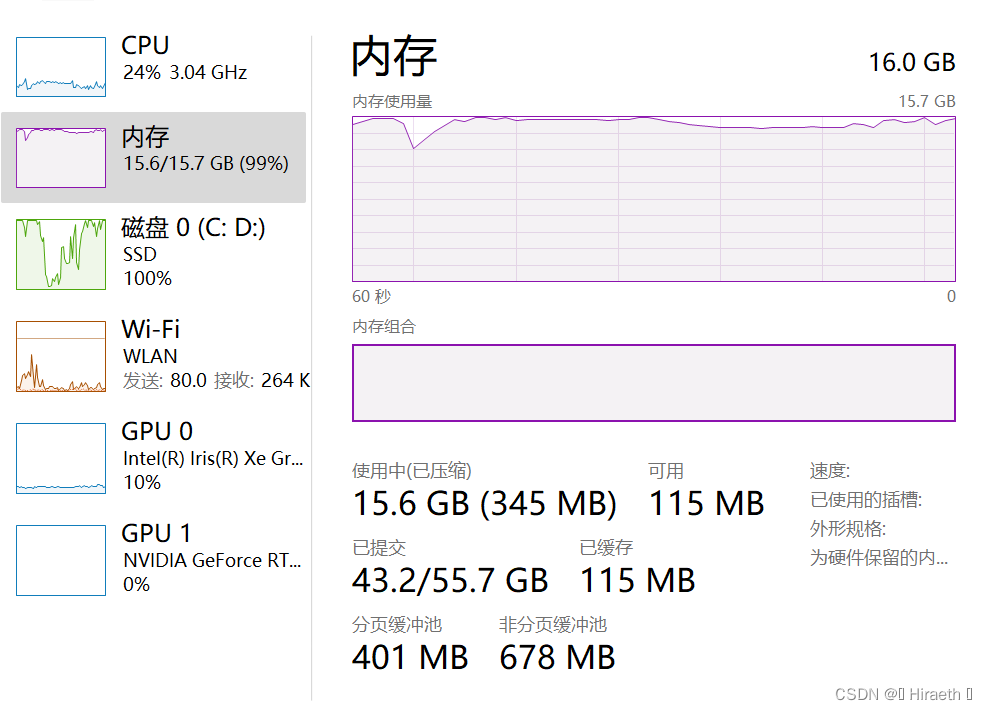
注意:此代码只绘制了前20列,在后续绘制其他列时,不能只重复执行上述代码,必须先再次设置画布(本文1.2处代码),否则多列图像会重叠在一起 ,如下图: 上文中代码是绘制数据前 20 列的,如需绘制其他指定列,只需更改上述主体结构中 for 循环里对列名的切片就行 ,但需注意定义的列表 numbers 中元素数量要等于(或大于,最后超出的几次循环会每个单独一个窗口显示,不会以子图的形式和前面的显示在一个画布中)for 循环循环次数,即list(tmp.columns)[a:b] 中切片出来的数量,否则会出现下面报错: 比如: for col in list(tmp.columns)[20:40]: numbers = list(range(1, 11)) #……该代码循环了第21列至第40列,但是numbers = [1,2,3,4,5,6,7,8,9,10],只有 10 个元素,就会发生报错。 本题无论是表格一还是表格二,数据量都太大,由于本人电脑性能所限,不能一次性绘制完所有图像。这里提醒以下,表格一和表格二中有一些一列中大部分为六位数到八位数的数据 ,经测试本人电脑单独绘制一列数据大部分都为六位数的图像是画不出来的,会出现以下报错,就算把C盘空间拿出来40G分给虚拟内存(更改电脑虚拟内存完后需重启)也不行。这不是绘图代码的问题。 这种数据据量过大有时还会导致电脑卡住,时间过长可以强制结束程序,多半是画不出来了。可以利用 del 将数据量过大的列手动删除: del tmp['GPRS总流量(KB)'], tmp['GPRS-国内漫游-流量(KB)']
|


【本文地址】