| 应对数据不平衡和过拟合的分类模型优化策略 | 您所在的位置:网站首页 › 欠拟合与过拟合的例子 › 应对数据不平衡和过拟合的分类模型优化策略 |
应对数据不平衡和过拟合的分类模型优化策略
|
不平衡分类
数据类别不平衡问题是指数据集中各类别样本数量不对等的情况。 基于抽样的方法在处理这类问题时,可以采用基于抽样的方法来解决。以下是几种常见的基于抽样的方法:
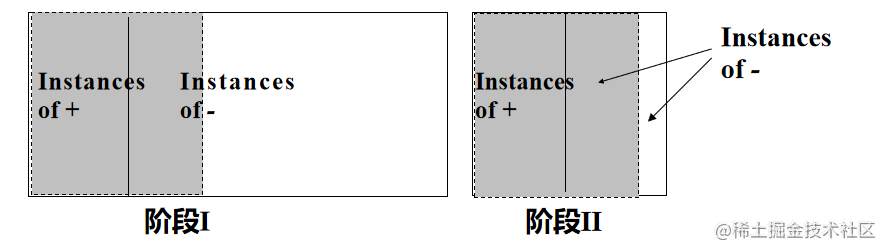
两阶段学习是一种解决不平衡分类问题的方法,包括特征学习阶段和分类器学习阶段。 在特征学习阶段,通过学习一组规则,尽可能覆盖正类(数量较少的类别)。这些规则可以捕捉到正类的特征和模式。 在分类器学习阶段,使用特征学习阶段得到的规则,结合正类和部分负类样本,再学习一组规则。通过这样的方式,可以更好地区分不同类别,并提高分类器的性能。 特征学习阶段分类器学习阶段 以基于规则的分类法为例:阶段I:学习一组规则,尽可能覆盖正类(少的那一类)阶段II:使用阶段I覆盖的正类和负类样本+部分其它负类样本,学习一组规则
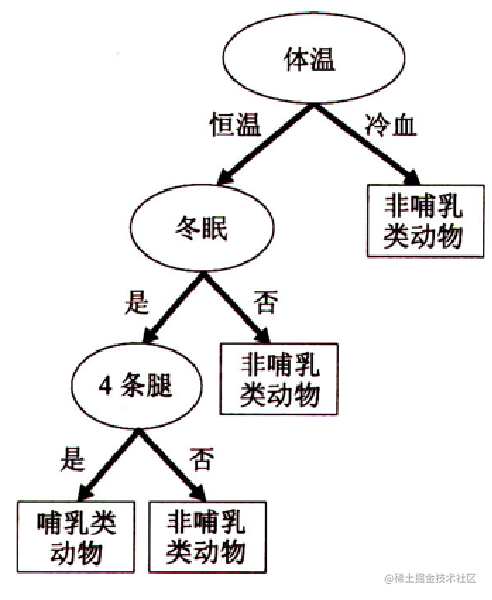
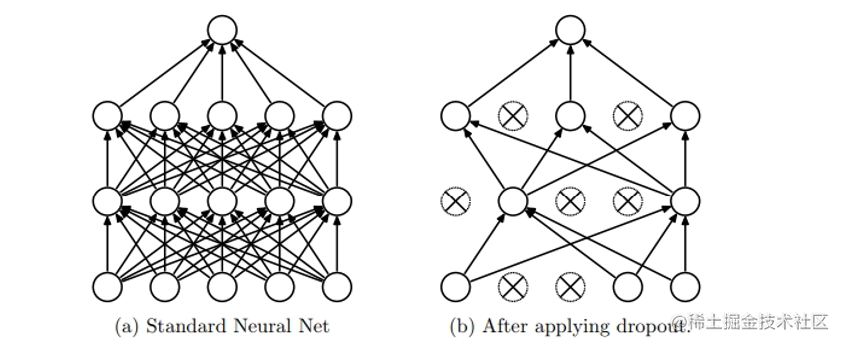
过拟合和欠拟合是在训练分类模型时常遇到的问题。 过拟合是指模型在训练数据上表现得过于优秀,但在未知数据上的表现较差。这种情况下,模型过于复杂,过分拟合了训练数据的噪声和细节,导致泛化能力下降。 欠拟合是指模型无法很好地拟合训练数据,不能捕捉到数据的真实结构。这种情况下,模型过于简单,无法充分学习数据的特征和模式。 为了解决过拟合问题,可以采取以下方法: 正则化方法:在损失函数中引入参数向量的L1或L2范数(L1正则化或L2正则化),限制模型的复杂度。Dropout:在神经网络中引入随机丢弃部分神经元的机制,减少神经网络的复杂性。为了解决欠拟合问题,可以采取以下方法: 增加模型的复杂度:增加模型的层数、神经元数等,使其能够更好地拟合训练数据。特征工程:对原始特征进行变换、组合等操作,增加模型对数据的表达能力。通过使用合适的方法来解决过拟合和欠拟合问题,可以提高分类模型的性能和泛化能力。 模型过分拟合和拟合不足分类模型的误差大致分为两种: 训练误差:是在训练记录上误分类样本比例泛化误差:是模型在未知记录上的期望误差一个好的分类模型不仅要能够很好的拟合训练数据,而且对未知样本也要能准确分类。换句话说,一个好的分类模型必须具有低训练误差和低泛化误差。当训练数据拟合太好的模型(较低训练误差),其泛化误差可能比具有较高训练误差的模型高,这种情况成为模型过分拟合。当进行训练时引用了较多噪点数据时就会发生过拟合,此时训练误差较小,但可能泛化误差较大. 建模过程: 以决策树算法为例 当决策树很小时,训练和检验误差都很大,这种情况称为模型拟合不足。出现拟合不足的原因是模型尚未学习到数据的真实结构。随着决策树中结点数的增加,模型的训练误差和泛化误差都会随之下降。当树的规模变得太大时,即使训练误差还在继续降低,但泛化误差开始增大,导致模型过分拟合。
导致过拟合的原因: 训练集规模太大训练集中存在大量噪音数据训练集规模太小,训练模型过于复杂 解决过拟合的方法一:减少泛化误差奥卡姆剃刀,拉丁文的意思是简约之法则。 奥卡姆剃刀定律被广泛运用在多个学科的逻辑定律,它的简单表述:如无必要,勿增实体 根据奥卡姆剃刀原则引入惩罚项,使较简单的模型比复杂的模型更可取 正则化方法:在原有损失函数的基础上添加参数向量的L1或L2范数(L1正则化或L2正则化)。神经网络中,引入dropout丢弃机制。
使用确认集 该方法中,不是用训练集估计泛化误差,而是把原始的训练数据集分为两个较小的子集,一个子集用于训练,而另一个称为确认集,用于估计泛化误差。该方法为评估模型在未知样本上的性能提供了较好办法。
|


 当树的规模变得太大时,即使训练误差还在继续降低,但泛化误差开始增大,导致模型过分拟合。
当树的规模变得太大时,即使训练误差还在继续降低,但泛化误差开始增大,导致模型过分拟合。 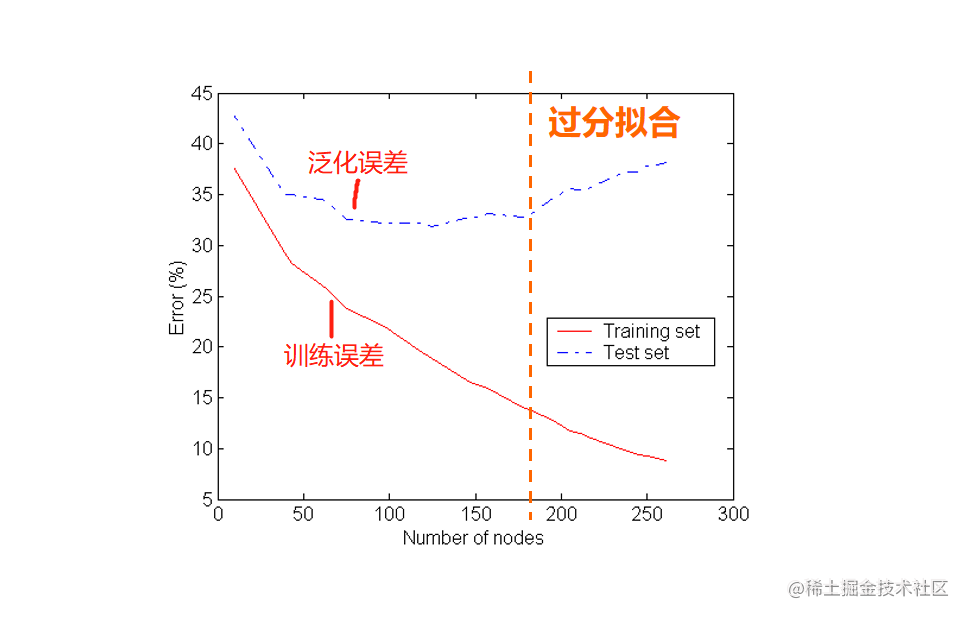 训练误差可以通过训练集来计算,泛化误差可以通过泛化误差来计算.
训练误差可以通过训练集来计算,泛化误差可以通过泛化误差来计算.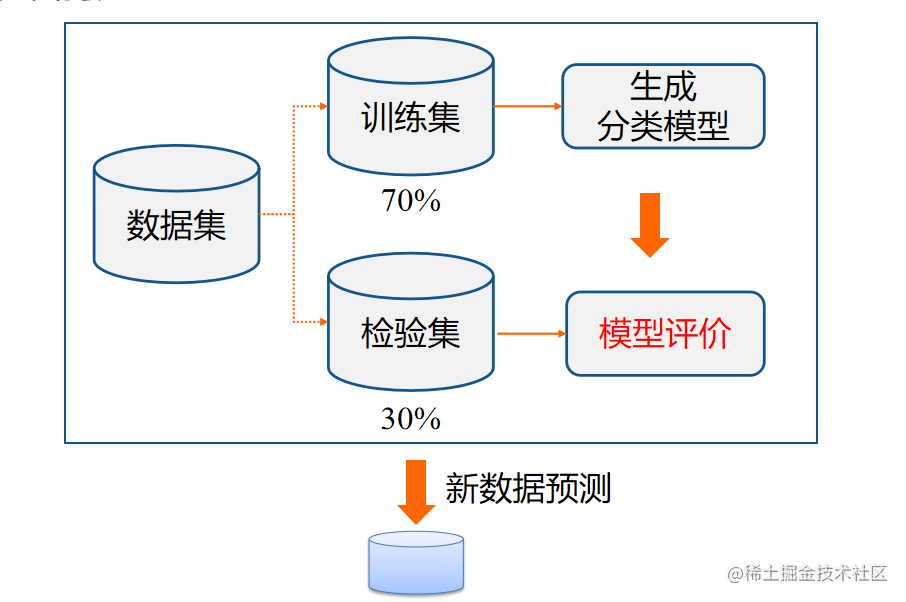
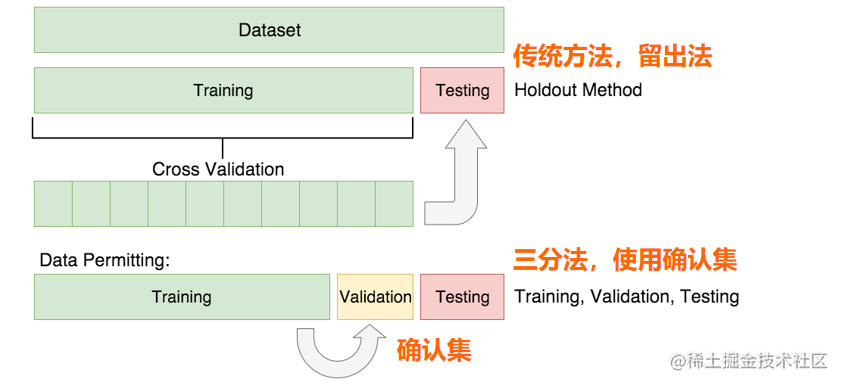 具体实现 保持法:
具体实现 保持法:【本文地址】
公司简介
联系我们