| 多模态融合最新创新方法汇总(附ICLR2024必看的22篇文章和源码) | 您所在的位置:网站首页 › 模型融合代码 › 多模态融合最新创新方法汇总(附ICLR2024必看的22篇文章和源码) |
多模态融合最新创新方法汇总(附ICLR2024必看的22篇文章和源码)
|
今天盘点了 ICLR 2024 顶会中有关多模态融合领域的最新研究成果,共22篇,方便同学们更高效地了解最新的融合方法、快速获得论文创新点的启发。 论文主要涉及大模型+多模态融合、自动选择和构建模态、视觉Transformer的3D对象检测、动态多模态融合的深度平衡、基于Transformer的系统融合方法等热门主题。 论文和代码需要的同学看文末 1.Progressive Fusion for Multimodal Integration多模态融合的渐进式融合 简述:多模态信息融合可以提升机器学习模型的性能。通常,模型会分别处理不同模态的数据,然后再将这些信息合并。但这种方法可能会丢失一些信息。另一方面,早期就将不同模态的信息合并的方法又会有特征不一致和样本复杂度高的问题。本文提出了一种叫做“渐进融合”的方法,通过在模型的不同层次之间建立联系,使得深层融合的信息能够被浅层使用,这样既避免了信息丢失,又保持了后融合的优点。作者在多个任务上测试了这个方法,并证明了它的有效性和通用性。
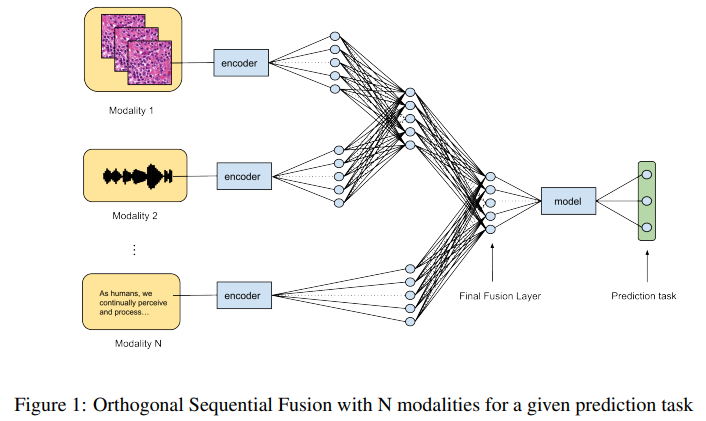
多模态学习中的正交序列融合 简述:多模态学习中,将不同来源的数据整合起来是一大挑战。传统方法通常是一次性融合所有数据,这可能会导致不同数据类型的表示不均匀。本文提出了一种新的融合方法,叫做正交顺序融合(OSF),它按顺序一步步合并数据,并且可以对不同类型的数据进行选择性加权。这种方法还可以增强正交性,也就是提取每种数据类型的独特信息。作者们通过不同的应用展示了这种方法的有效性,并证明了它在准确性上优于其他融合技术。
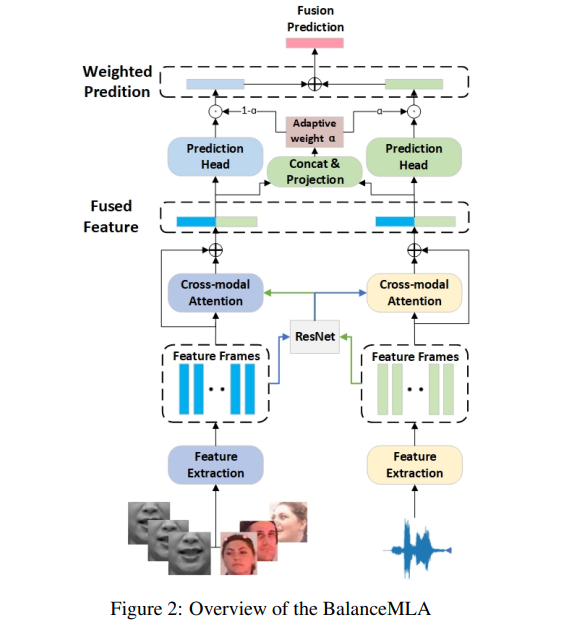
视听融合中多任务学习的集成框架 简述:多模态学习通过结合不同感官信息来提升诸如情感分析等任务的效果。但现有研究指出,不同数据类型间存在贡献不均和学习速率不一致的问题。忽视这些问题会影响整体性能。本文提出了一个名为BalanceMLA的多模态学习框架,旨在动态平衡和优化每种模态的贡献。该框架能独立调整每种模态的目标并控制其学习过程。作者还设计了特征融合和决策融合策略来处理不平衡问题,并引入了针对具体任务的类级加权方案。实验结果表明,该模型在处理模态不平衡方面表现出色,即使在噪声环境下也能保持高效的融合效果和鲁棒性。
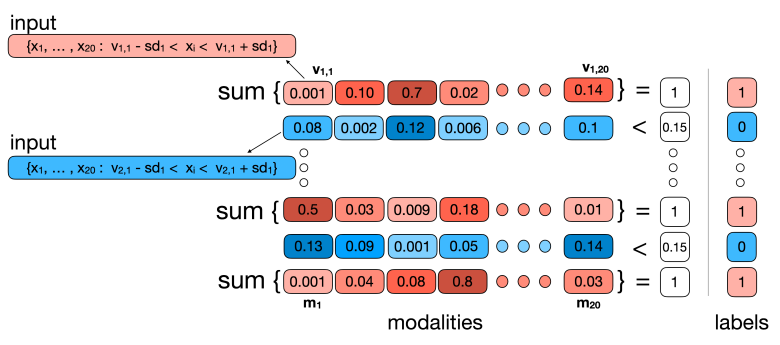
量化半监督多模态学习中的交互 简述:在多模态学习中,理解不同数据类型如何相互作用是一个关键问题。本文研究了在只有部分标记数据的情况下如何量化这种交互作用。作者们提出了一种基于信息论的方法来界定多模态交互的上下界,并展示了这些界限如何准确反映真实的交互程度。最后,他们说明了这些理论结果如何帮助评估模型性能、指导数据收集和选择合适的多模态模型。
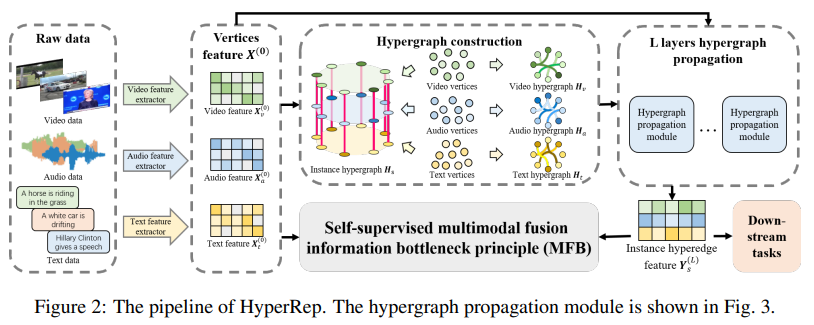
基于Hypergraph的自监督多模态表示学习 简述:本文提出了一种叫做HyperRep的新方法,用于自监督多模态学习。这种方法利用超图来捕捉不同数据类型之间复杂的高阶关系,并结合信息瓶颈原则来提高多模态数据的融合效果。实验结果表明,与其他先进方法相比,HyperRep在多个数据集和任务上都能取得很好的效果。
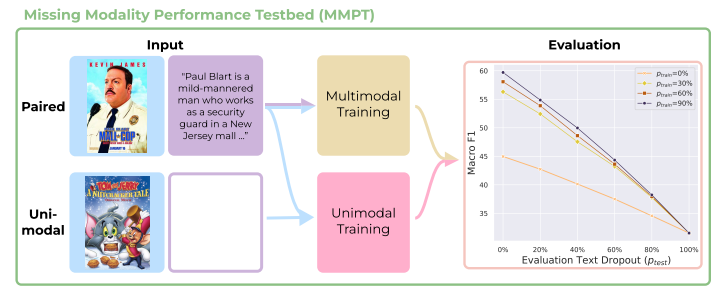
从多任务混合视角看待缺失模态 简述:多模态学习中常见的问题是某些模态数据可能缺失。传统上,这被视为鲁棒性问题,目的是防止因模态丢失导致性能下降。但在实际的科学和工业应用中,单模态输入比多模态输入更常见。本文提出了一个新方法——缺失模态性能测试平台(MMPT),它重新考虑了在缺失模态影响下如何提升模型性能的问题,并将缺失模态与模态竞争联系起来。作者们在多个数据集上验证了这种方法,并展示了如何在缺失模态的情况下达到新的最优性能水平。
可扩展的多模态融合 简述:多模态学习模型很重要,因为它们在很多任务上的表现超过了只使用一种模态的模型。但是,现有的多模态学习方法大多专注于处理最多四种模态(图像、文本、音频、视频),并且当模态数量增加时,它们的计算复杂度会急剧上升。本文提出了一种新的注意力机制——一对多(OvO)注意力,它能够随着模态数量的增加而线性扩展,从而显著降低了计算复杂度。通过实验证明,这种方法在提高性能的同时减少了计算成本。
使用多模态表达的嵌入式问答 简述:人们在交流时会用语言和手势,比如指东西时。但是之前的问答系统只能处理文字问题。本文介绍了8个新任务和一个大数据集EQA-MX,用来训练模型理解包含手势和语言的问题。作者还提出了一个新模型VQ-Fusion,它可以更好地结合视觉和语言信息。实验结果表明这个模型能显著提高问答系统的性能。
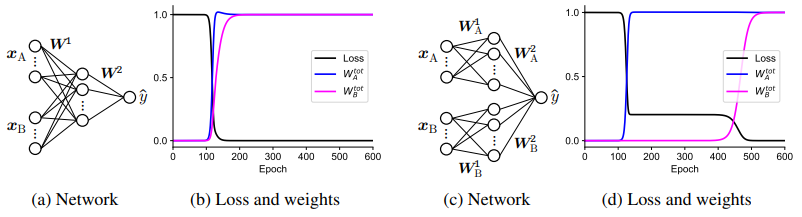
多模态学习中单模态偏差理论 简述:同时训练多模态神经网络是一项具有挑战性的任务,因为网络可能会过度依赖一个模态而忽略其他模态,这种现象被称为单模态偏差。为了解决这个问题,作者开发了一种理论,该理论可以计算出学习过程中单模态阶段的持续时间。作者发现,融合模态的层越深,单模态阶段的时间就越长。此外,该理论还揭示了首先学习的模态不一定是对输出贡献最大的模态。
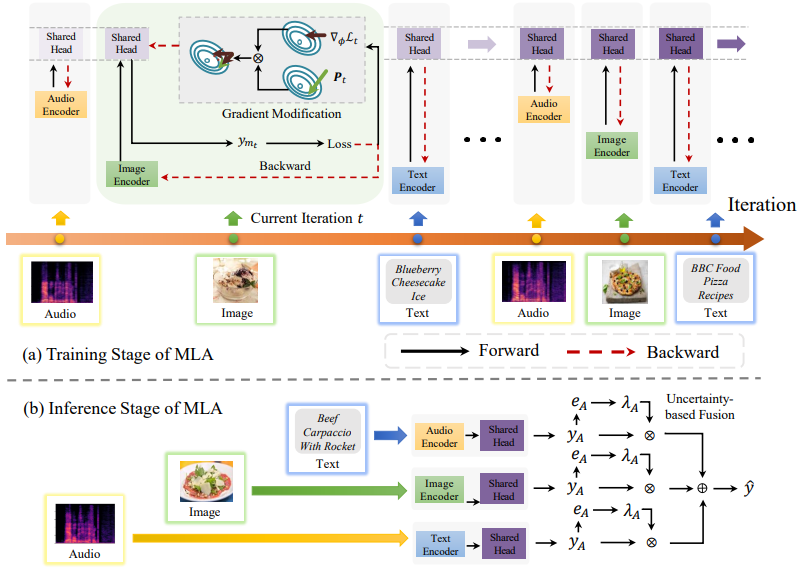
通过交替单模态适应进行多模态表示学习 简述:多模态学习对人工智能很重要,但有时某些模态会比其他模态更有影响力,这会影响结果。本文提出了一种新的方法MLA,通过交替学习单一模态来减少不同模态之间的干扰,并通过共享部分来捕捉不同模态间的互动。这种方法在测试时还能很好地结合多种模态的信息。实验表明,MLA比之前的方法效果更好。
Deep Equilibrium Multimodal Fusion Fusion is Not Enough: Single Modal Attack on Fusion Models for 3D Object Detection Transformer Fusion with Optimal Transport Parameter-Efficient Multi-Task Model Fusion with Partial Linearizeation Jointly Training Large Autoregressive Multimodal Models Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation FusionViT: Hierarchical 3D Object Detection via Lidar-Camera Vision Transformer Fusion Multimodal Patient Representation Learning with Missing Modalities and Labels CLIP the Bias: How Useful is Balancing Data in Multimodal Learning? Optimal and Generalizable Multimodal Representation Learning Framework through Adaptive Graph Construction Simultaneous Dimensionality Reduction: A Data Efficient Approach for Multimodal Representation Learning IMProv: Inpainting-based Multimodal Prompting for Computer Vision Tasks 关注下方《学姐带你玩AI》🚀🚀🚀 回复“ICLR多模态”获取全部论文 码字不易,欢迎大家点赞评论收藏 |



【本文地址】