| 【概率论面试整理】 | 您所在的位置:网站首页 › 概率论知识要点 › 【概率论面试整理】 |
【概率论面试整理】
|
转载:https://blog.csdn.net/qian2213762498/article/details/80480888 文章目录 方差极大似然估计法和机器学习随机梯度下降法概率题 [参考1](https://www.cnblogs.com/yxzfscg/p/4752878.html) [参考2](https://blog.csdn.net/rudyalwayhere/article/details/7349957) 什么是大数定律(LAMDA)先通俗讲再举例大数定律通俗一点来讲,就是样本数量很大的时候,样本均值和数学期望充分接近,也就是说当我们大量重复某一相同的实验的时候,其最后的实验结果可能会稳定在某一数值附近。就像抛硬币一样,当我们不断地抛,抛个上千次,甚至上万次,我们会发现,正面或者反面向上的次数都会接近一半,也就是这上万次的样本均值会越来越接近50%这个真实均值,随机事件的频率近似于它的概率。 中心极限定理是说当样本数量无穷大的时候,样本均值的分布呈现正态分布(边说边比划正态曲线) 大数定律和中心极限定理的区别: 前者更关注的是样本均值,后者关注的是样本均值的分布,比如说掷色子吧,假设一轮掷色子n次,重复了m轮,当n足够大,大数定律指出这n次的均值等于随机变量的数学期望,而中心极限定理指出这m轮的均值分布符合围绕数学期望的正态分布。 以上说明了任意概率分布作独立叠加将还原成正态分布。 抛硬币: 全概率是用原因推结果,贝叶斯是用结果推原因。 ++++++++++++++++++++++++++++++++++++++++ 全概率公式:
P
(
A
)
=
P
(
B
1
)
P
(
A
∣
B
1
)
+
P
(
B
2
)
P
(
A
∣
B
2
)
+
P
(
B
3
)
P
(
A
∣
B
3
)
+
⋯
P(A)=P(B1) P(A|B1)+P(B2)P(A|B2)+P(B3)P(A|B3)+⋯
P(A)=P(B1)P(A∣B1)+P(B2)P(A∣B2)+P(B3)P(A∣B3)+⋯ 把
B
i
B_i
Bi看作是事件
A
A
A发生的一种“可能途径”,
P
(
A
∣
B
1
)
P(A|B1)
P(A∣B1)则是通过这种途径得到
A
A
A的可能性,而途径的选择是随机的,因此可以把
P
(
A
)
P(A)
P(A)看作不同途径概率的和。 +++++++++++++++++++++++++++++++++++++++++ 贝叶斯 利用贝叶斯定理,我们可以通过条件概率P(Y|X)P(Y|X)计算出P(X|Y)P(X|Y),从某种意义上说,就是“交换”条件 p ( X 1 X 2 , . . . , X n ) = p ( X 1 ) ∗ p ( X 2 ∣ X 1 ) ∗ . . . ∗ p ( X n ∣ X 1 , X 2 , . . . X n − 1 ) p(X_1X_2,...,X_n) = p(X_1)*p(X_2|X_1)*...*p(X_n|X_1,X_2,...X_{n-1}) p(X1X2,...,Xn)=p(X1)∗p(X2∣X1)∗...∗p(Xn∣X1,X2,...Xn−1) 链式法则通常用于计算多个随机变量的联合概率,特别是在变量之间相互为(条件)独立时会非常有用。注意,在使用链式法则时,我们可以选择展开随机变量的顺序;选择正确的顺序通常可以让概率的计算变得更加简单。 什么是概率分布概率分布是描述一个随机变量的不同取值范围及其概率的函数,函数中有一些参数可以调整这一分布的范围和取值概率,有了这个函数,就可以计算n次实验后某事件发生的概率。 连续和离散分布离散分布:随机变量的取值是一些离散的点,例如抛硬币,它的期望可以通过直接累积相加得到也就是 ∑ x P ( x ) \sum xP(x) ∑xP(x) 连续分布:随机变量的取值是连续且无穷的,例如01之间任取一个数,他的期望可以通过积分求得也就是 ∫ x P ( x ) d x \int xP(x)dx ∫xP(x)dx 正态分布正态分布又称高斯分布,它是连续型随机变量的分布,它主要由两个参数 u u u和 σ 2 σ^2 σ2,也就是期望和方差,遵从正态分布的随机变量满足这样一个规律:取值离 u u u越近的概率越大,同时 σ σ σ描述了分布的胖瘦,它越大,曲线越矮胖,越小,曲线越高瘦。 t分布t分布主要用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 方差 方差的概念概率论中方差用来度量随机变量X的取值相对于其均值的偏离程度。统计中的样本方差是每个样本值与全体样本值的平均数之差的平方值的平均数。 S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 S^2 = \frac{1}{n-1}\sum_{i=1}^n(X_i-\overline X)^2 S2=n−11∑i=1n(Xi−X)2 方差的计算方法
协方差是用来度量两个随机变量的相关性。 C o v ( X , Y ) = E ( X − E ( X ) ) ∗ E ( Y − E ( Y ) ) = E ( X Y ) − E ( X ) ∗ E ( Y ) Cov(X,Y) = E(X-E(X))*E(Y-E(Y)) = E(XY)-E(X)*E(Y) Cov(X,Y)=E(X−E(X))∗E(Y−E(Y))=E(XY)−E(X)∗E(Y) 独立和不相关 方差与相关系数相关描述的是随机变量之间线性相关而方差或者说独立性描述的是值相关,所以随机变量之间独立则一定不相关但是不相关不一定独立。 极大似然估计法和机器学习随机梯度下降法 什么是事件的独立性某一事件发生的概率完全不受到其他事件的影响。 用公式表示就是 P ( A , B ) = P ( A ) ∗ P ( B ) P(A,B)=P(A)*P(B) P(A,B)=P(A)∗P(B) 什么是随机变量随机变量并不是一个真正的变量。它更像是将样本空间的结果映射到真值的函数,让我们可以将事件空间的形式概念抽象出来。 什么是数学期望随机变量的均值(不同于样本均值),大数定律指出如果样本足够的话,样本均值才会无限接近期望。 什么是马尔科夫链马尔可夫链描述的是随机变量的一个状态序列,在这个状态序列里未来信息只与当前信息有关,而与过去的信息无关。它有两个很重要的假设: t+1时刻的状态的概率分布只与t时刻有关t到t+1时刻状态转移与t值无关一个马尔可夫模型可以看作是状态空间(也就是所有可能状态) + 状态转移矩阵(也就是一个条件概率分布) + 初始概率分布(就是初始化状态)。 概率题 参考1 参考2 一条长度为l的线段,随机在其上选2个点,将线段分为3段,问这3个子段能组成一个三角形的概率是多少? 你有两个罐子以及50个红色弹球和50个蓝色弹球,随机选出一个罐子然后从里面随机选出一个弹球,怎么给出红色弹球最大的选中机会?在你的计划里,得到红球的几率是多少? 你有两个罐子以及50个红色弹球和50个蓝色弹球,随机选出一个罐子然后从里面随机选出一个弹球,怎么给出红色弹球最大的选中机会?在你的计划里,得到红球的几率是多少?
在一个罐子中抽到红球的最大概率是1,也就是罐子里全都是红球,而另一个罐子里是剩余红球和全部的蓝球,能得到当罐子一的红球越少,罐子二中的红球所占的比例就越大,抽中的概率也就越大,所以最好的分配方案是一个罐子有一个红球,另一个罐子有49红50蓝,这样总概率是 1 2 ∗ + 1 2 ∗ 49 99 = 74.7 % \frac{1}{2}*+\frac{1}{2}*\frac{49}{99}=74.7\% 21∗+21∗9949=74.7%。 一副扑克牌54张,现分成3等份每份18张,问大小王出现在同一份中的概率是多少?先求总的分配方案: M = C 54 18 ∗ C 36 18 ∗ C 18 18 M=C_{54}^{18}*C_{36}^{18}*C_{18}^{18} M=C5418∗C3618∗C1818 再求大小王在一份的分配方案: N = C 3 1 ∗ C 52 16 ∗ C 36 18 ∗ C 18 18 N=C_3^1*C_{52}^{16}*C_{36}^{18}*C_{18}^{18} N=C31∗C5216∗C3618∗C1818种。 因此所求概率为 P = N / M = 17 / 53 P=N /M=17/53 P=N/M=17/53。 给你一个骰子,你扔到几,机器将会给你相应的金钱。比如,你扔到6,机器会返回你6块钱,你扔到1,机器会返回你1块钱。请问,你愿意最多花多少钱玩一次?就是求一下数学期望,因为假设你玩无穷次,根据大数定律,实际上你的收益就是随机变量的数学期望,他等于 1 ∗ 1 6 + 2 ∗ 1 6 + … = 3.5 1*\frac{1}{6}+2*\frac{1}{6}+…=3.5 1∗61+2∗61+…=3.5,你不能花比这更多的钱,否则会赔本。 有一对夫妇,先后生了两个孩子,其中一个孩子是女孩,问另一个孩子是男孩的概率是多大?答案是2/3.两个孩子的性别有以下四种可能:(男男)(男女)(女男)(女女),其中一个是女孩,就排除了(男男),还剩三种情况。其中另一个是男孩的占了两种,2/3. 之所以答案不是1/2是因为女孩到底是第一个生的还是第二个生的是不确定的。 有一苹果,两个人抛硬币来决定谁吃这个苹果,先抛到正面者吃。问先抛这吃到苹果的概率是多少?第一次抛硬币后两人的先后顺序就确定了,假设A先于B,那么A只能在1357.。。等奇数次抛硬币,现在我们吧问题分成两个部分,实际上第三次以后赢和第一次以后赢他面临的处境一样,他在第一次赢的概率是1/2,在第三次以后赢的概率是1/21/2p,所以有p=1/2+1/4*p,解出来的p就是先抛赢的概率 X是随机变量,X在[0,1]之间, E [ X ] = u , 1 ; c E[X]=u,1;c E[X]=u,1>c。 请证明 P ( X ; c u ) ; = ( 1 − u ) / ( 1 − c u ) P(X ; cu);=(1-u)/(1-cu) P(X |


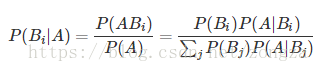 这里贝叶斯可以看作求某种途径占所有途径的比例 。 +++++++++++++++++++++++++++++++++++++++++ 贝叶斯用在机器学习中: 比如性别分类,在身高体重等因素已知的情况下判断男性或者女性,这里假设身高体重都是正态分布。
这里贝叶斯可以看作求某种途径占所有途径的比例 。 +++++++++++++++++++++++++++++++++++++++++ 贝叶斯用在机器学习中: 比如性别分类,在身高体重等因素已知的情况下判断男性或者女性,这里假设身高体重都是正态分布。 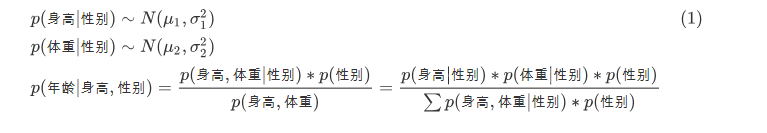 还比如用朴素贝叶斯进行垃圾邮件过滤: 这里有一个条件独立假设: 假设
x
,
y
x,y
x,y条件独立于
z
z
z,则
p
(
x
,
y
∣
z
)
=
p
(
x
∣
z
)
∗
p
(
y
∣
z
)
p(x,y|z)=p(x|z)*p(y|z)
p(x,y∣z)=p(x∣z)∗p(y∣z)。
还比如用朴素贝叶斯进行垃圾邮件过滤: 这里有一个条件独立假设: 假设
x
,
y
x,y
x,y条件独立于
z
z
z,则
p
(
x
,
y
∣
z
)
=
p
(
x
∣
z
)
∗
p
(
y
∣
z
)
p(x,y|z)=p(x|z)*p(y|z)
p(x,y∣z)=p(x∣z)∗p(y∣z)。
 方差中n-1的含义: 是为了保证计算出来的方差没有偏差。 如果写一个程序计算方差,那么计算一次内存访问几次? 这里就不考虑缺页了,假设数据全都在一页中且页已经调入内存 首先求样本均值需要一个for循环n次 其次计算方差也需要一个for循环求差值,差值的平方,差值的平方的和 所以一共2n次。
方差中n-1的含义: 是为了保证计算出来的方差没有偏差。 如果写一个程序计算方差,那么计算一次内存访问几次? 这里就不考虑缺页了,假设数据全都在一页中且页已经调入内存 首先求样本均值需要一个for循环n次 其次计算方差也需要一个for循环求差值,差值的平方,差值的平方的和 所以一共2n次。【本文地址】