| 统计学(一): Z 分数 & 正态分布 (附 Python 实现代码) | 您所在的位置:网站首页 › 概率统计z分布表 › 统计学(一): Z 分数 & 正态分布 (附 Python 实现代码) |
统计学(一): Z 分数 & 正态分布 (附 Python 实现代码)
|
笔者的第一本心理学启蒙教材《西奥蒂尼社会心理学》;揭开了自我、环境、群体之间看不见的影响力。“ 行为背后的目的到底是什么?” “ 目的背后的人和环境发挥了怎样的作用?” 是社会心理学探究的两大核心问题。笔者从心理学网站中抽取了有一组关于说服者态度强硬指数的数据,为了探究受试者态度强硬的程度与说服结果的关系,我们首先需要知道他们的强硬指数的 “ 段位 ”,即他们超过了群体中百分之几的人,又或者说群体中有百分之几的人在 TA 后/前面。不过为了让你对 z 分数有一个更加深刻的认识,请确保你已经掌握了如下的基础概念和简单的术语,它们在统计学实验和文献中会经常出现。 z 分数是将个体分数,个体所在样本或总体的平均值和标准差串在一起的一个概念,它是对普通数据进行转换的结果,可以更好地描述数据在分布中的位置,进而得出原始分数在数据集合中的百分等级,这样便能让一个统计学外行人也能完全听懂;计算公式为 Z = (X - M)/SD,用来描述某分数在其分布中高于(或低于,如果它为负)平均数的标准差数目;总的来说,可以确定该分数所在的位置(“段位”) 我们现在随机抽取一位同学,计算 TA 强硬指数的“段位” 查表法:如下为z 分数表 源代码 def z_score(data, individual): """ 传入这个样本的所有数据 & 希望探究的个体的数据, 打印其对应的 Z 分数 """ # 求解平均值和方差, 并求解 z 分数 mean = data.mean() std = data.std() z = (individual - mean) / std return {'原始分数': individual, 'Mean': round(mean,3), 'Standard deviation': round(std,3), 'Z score': z}粗略估计法则则可参照下图的范围区间(该图非常常用,需要牢记) 细心一点的朋友应该会发现,其实上面两个方法(精确查表和粗略看分布图)的方法都是基于正态曲线来说的。其实数据的分布情况并不会给 Z 分数的可信度造成很大影响。Z 分数有时候被称作标准分布,因为 Z 分数相对于平均数和标准差有着标准值,而且它提供了测量任意变量的标准尺度(话虽如此,又是只有当 Z 分数的分布为正态时,术语标准分数才能使用,后面会继续更博) 为什么自然界中正态曲线如此常见? 常见的连续分布的形式 注意:数据分析中,一般情况下,右偏不严重的 – 当正态分布用;右偏严重的 – 当对数正态用;做描述性统计分析的时候,中心水平通常用均值或者中位数来表示。如何在两者中抉择呢?偏度一般:均值;偏度比较大时,使用中位数。为什么不一直使用中位数?对老百姓来说不好理解 说服者态度强硬指数的分布情况 如何一步到位的画出复杂精美的图片可以参考这篇博文 Python 数据可视化:seaborn displot 正态分布曲线拟合图代码注释超详解(放入自写库,一行代码搞定复杂细节绘图) 模拟问答谈谈你对平均数,方差和标准差的理解吧,他们之间的关系 z 分数是什么,计算公式?有什么意义? z 分数与百分位数有什么异同?计算公式与 numpy 中的 percentile 函数可当成是一体吗 percentile(百分位数)更接近顺序变量,Z-score(标准分数)是连续变量。分布正态时两者无差别,偏态时用百分位数更好,不过还是要看具体情况。 总而言之,了解 Z 分数,是入门统计学的开始,加油! 后记数据分析,商业实践,数据可视化,网络爬虫,统计学,Excel,Word, 社会心理学,认知心理学,行为科学,民族意志学 各种专栏后续疯狂补充 欢迎评论与私信交流! |


 数据预览 & 求解 z 分数
数据预览 & 求解 z 分数 求解 z 分数
求解 z 分数 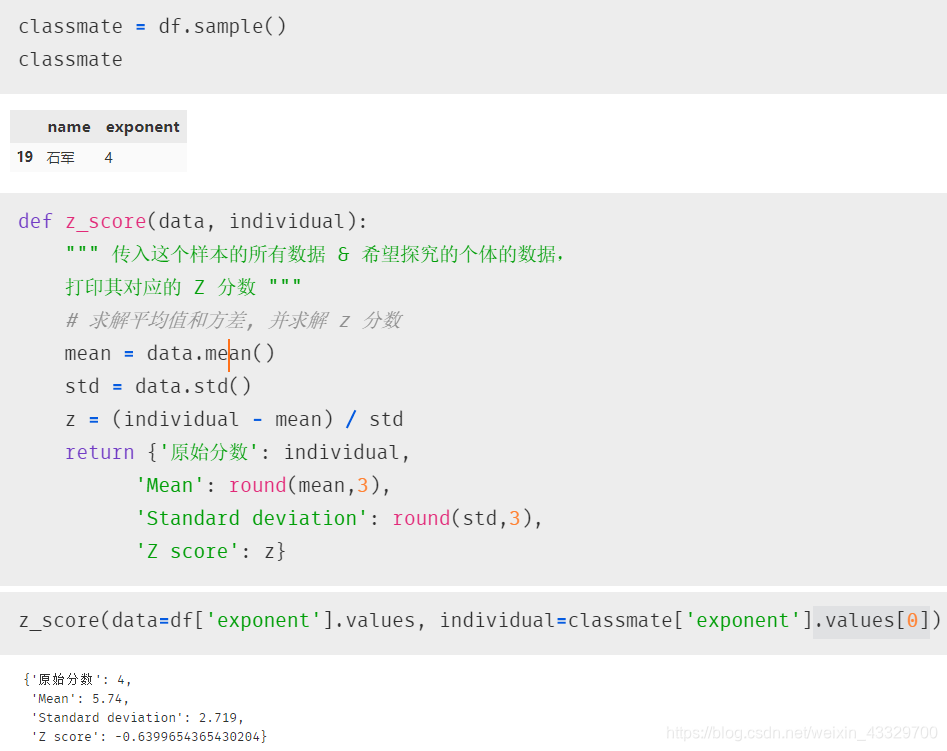 现在我们知道了 “石军” 同学的 z 分数大约为 -0.63,那接下来该如何判断其“段位”呢?两个方法:结合正态分布曲线粗略标定法和直接查表法。
现在我们知道了 “石军” 同学的 z 分数大约为 -0.63,那接下来该如何判断其“段位”呢?两个方法:结合正态分布曲线粗略标定法和直接查表法。 通过上表不难看出,石军的 z_score 为 -0.63,根据正态曲线的 z 分数表可以找出精确的百分比为 0.735(三位小数),即 73.5%,因为其 z 分数为负,所以我们可以这样说:石军同学的强硬指数低于 73.5% 的同学。
通过上表不难看出,石军的 z_score 为 -0.63,根据正态曲线的 z 分数表可以找出精确的百分比为 0.735(三位小数),即 73.5%,因为其 z 分数为负,所以我们可以这样说:石军同学的强硬指数低于 73.5% 的同学。 顺便安利一个免费的提高效率的软件,用后再不说自己忙了。Office Lens:扫描软件,不多说,谁下谁知道。
顺便安利一个免费的提高效率的软件,用后再不说自己忙了。Office Lens:扫描软件,不多说,谁下谁知道。

【本文地址】