| 概率密度直方图(可看作PDF的在步长较大时的近似)与累积分布直方图(可看作CDF的在步长较大时的近似) | 您所在的位置:网站首页 › 概率pdf峰值宽度怎么算 › 概率密度直方图(可看作PDF的在步长较大时的近似)与累积分布直方图(可看作CDF的在步长较大时的近似) |
概率密度直方图(可看作PDF的在步长较大时的近似)与累积分布直方图(可看作CDF的在步长较大时的近似)
|
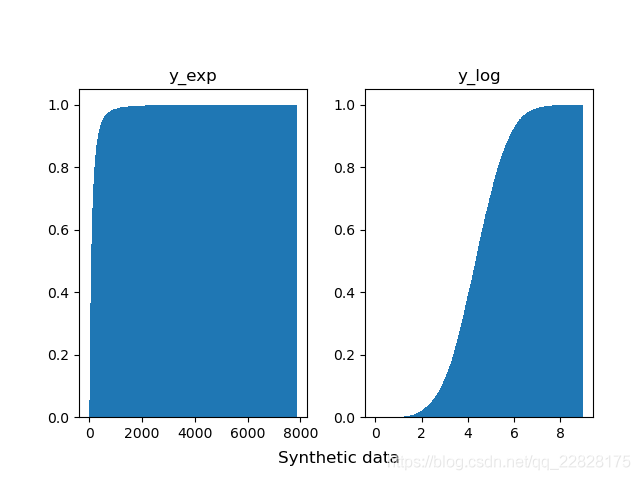
在概率密度直方图中,取到任一bin中的一个样本的平均概率,等于该箱的高度(纵坐标y值) × 宽度(横坐标间距δx) ÷ 该箱中样本个数(n_samples),而不是等于纵坐标y值;即此时面积表示概率之和,而不是纵坐标y值表示单一样本概率;如图1、图2所示。在累积分布直方图中,取到任一bin中的一个样本的平均概率,等于(该箱的高度(纵坐标y值) -左侧箱的高度)/ 该箱中样本个数;即此时纵坐标y值表示概率,但为累计概率;如图3、图4所示。当箱的个数等于样本总数,即每个箱中只有一个样本时,取到任意一个样本的概率,在概率密度直方图中,等于该箱的高度 × 宽度;在累积分布直方图中,等于该箱的高度-左侧箱的高度。此时累积分布直方图趋近于累计分布函数(CDF),但概率密度直方图中各箱顶点的连线通常并不趋近于概率密度函数(PDF),因为在各个横坐标处,也就是样本的取值处,通常会存在离群的样本取值概率,也就是离群的纵坐标值;只有对该直方图取一定程度的平滑曲线,才趋近于概率密度函数;如图5、图6所示。
图1 bins=4的概率密度直方图 |
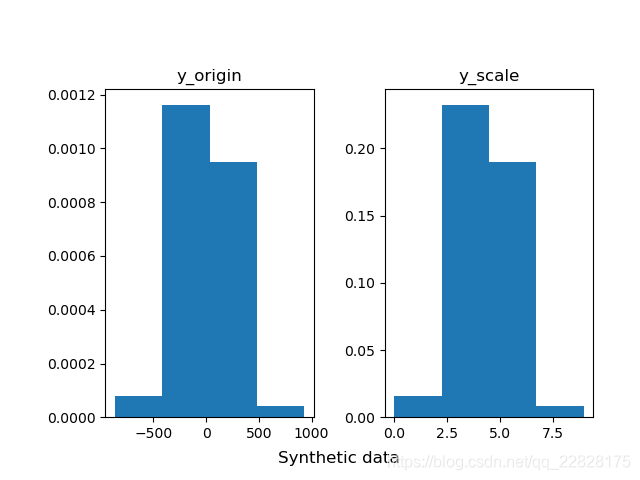
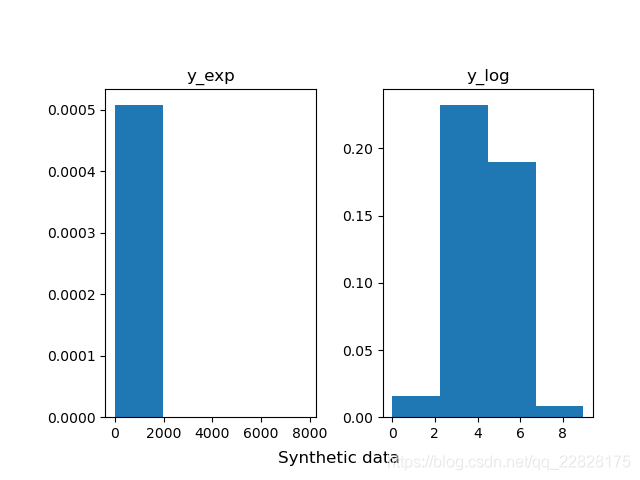 图2 bins=40的概率密度直方图
图2 bins=40的概率密度直方图 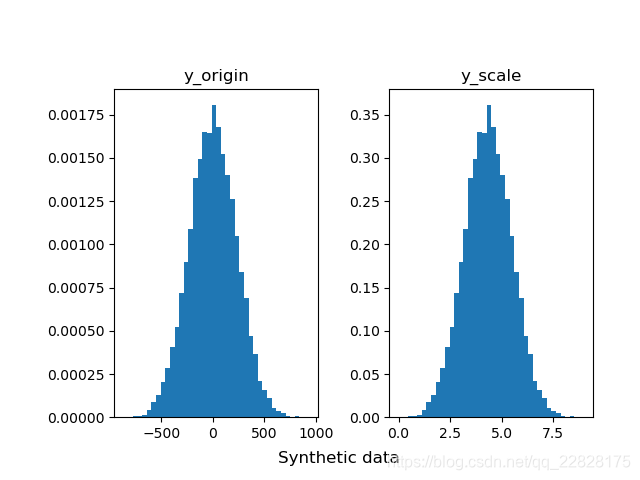
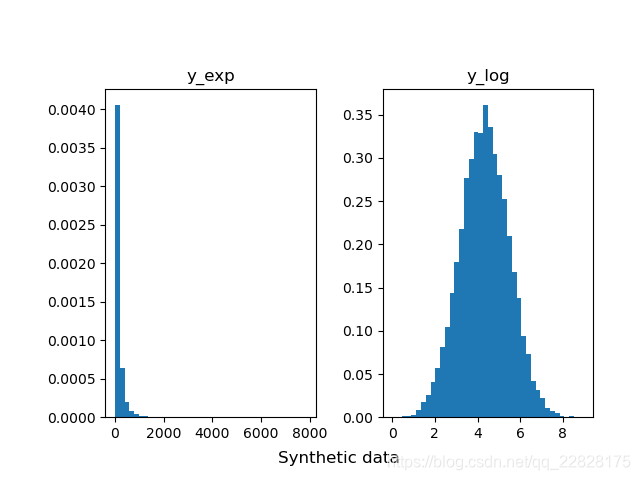 图3 bins=4的累积分布直方图
图3 bins=4的累积分布直方图 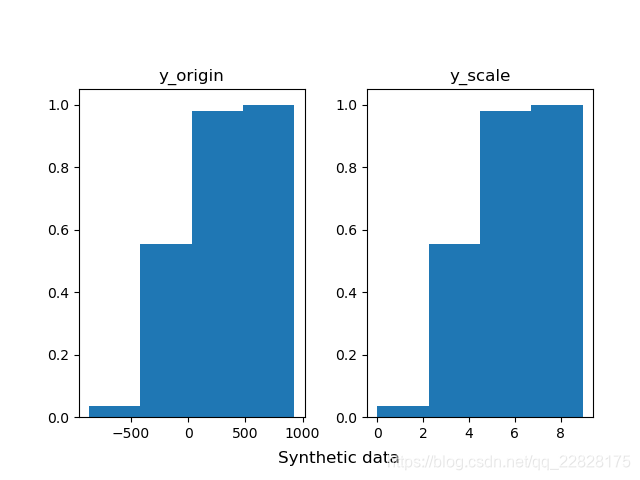
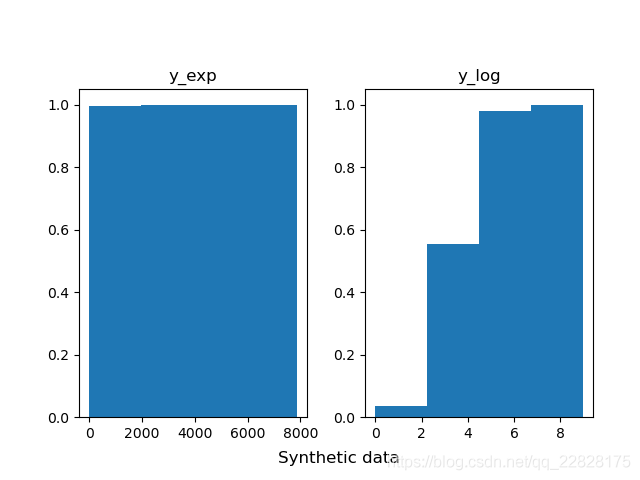 图4 bins=40的累积分布直方图
图4 bins=40的累积分布直方图 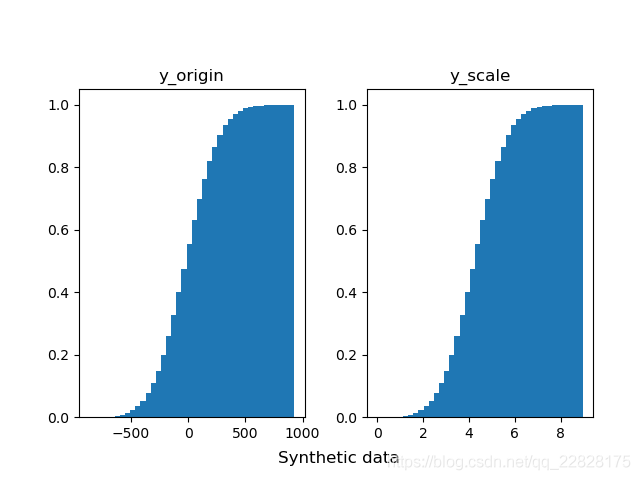
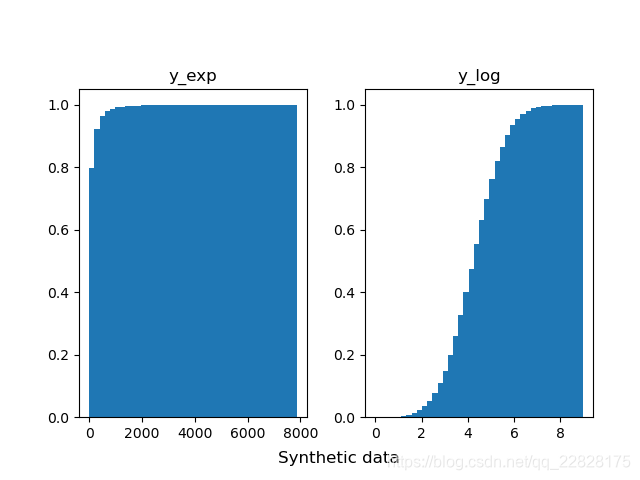 图5 bins等于样本总数时的概率密度直方图
图5 bins等于样本总数时的概率密度直方图 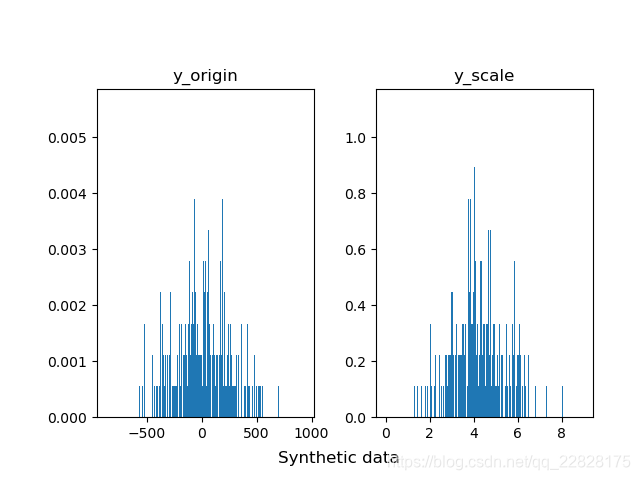
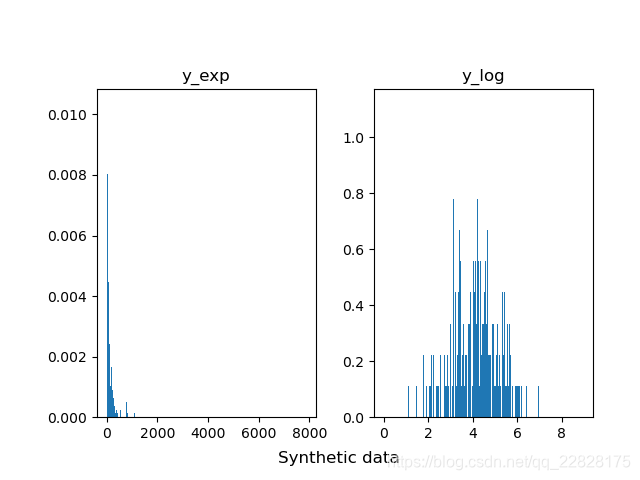 图6 bins等于样本总数时的累积分布直方图
图6 bins等于样本总数时的累积分布直方图 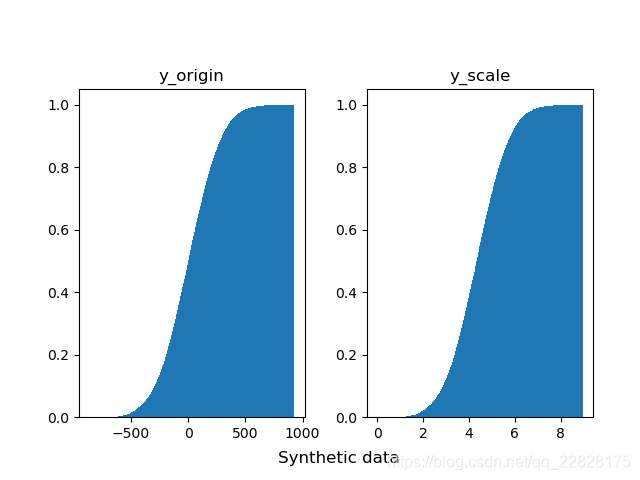
【本文地址】
公司简介
联系我们