| CTF | 您所在的位置:网站首页 › 案例分析题应该怎么做 › CTF |
CTF
|
我见过的流量分析类型的题目总结: 一,ping 报文信息 (icmp协议) 二,上传/下载文件(蓝牙obex,http,难:文件的分段上传/下载) 三,sql注入攻击 四,访问特定的加密解密网站(md5,base64) 五,后台扫描+弱密码爆破+菜刀 六,usb流量分析 七,WiFi无线密码破解 八,根据一组流量包了解黑客的具体行为 例题: 一,ping 报文信息 (icmp协议)例1.1 打开流量包,发现有一大段的icmp协议的包,发现在icmp报文中夹杂着flag
这里可以依次查看每一个icmp报文数据,然后得到flag 也可以用脚本处理:(不推荐) 先过滤出 icmp协议的包》导出特定分组 》保存为flag.pcapng》然后用脚本处理: (这个脚本只能处理data只有一个字节的包,局限性较大,还不如直接一个包一个包查看,反正flag也不会太长) import pyshark cap = pyshark.FileCapture('flag.pcapng') for packet in cap: data = ''+packet[packet.highest_layer].data print(chr(int(data,16)),end='') cap.close()
二,上传/下载文件(蓝牙obex,http,难:文件的分段上传/下载) 这类夹杂着文件的流量包最好处理, 方法一,直接用foremost直接分离提取一下就能提取出其中隐藏的文件,一般会直接分离出来一个 压缩包,一张图片,或者flag.txt都是有可能的 方法二, 自动提取通过http传输的文件内容 文件->导出对象->HTTP
在打开的对象列表中找到有价值的文件,如压缩文件、文本文件、音频文件、图片等,点击Save进行保存,或者Save All保存所有对象再进入文件夹进行分析。
手动提取通过http传输的文件内容 选中http文件传输流量包,在分组详情中找到data,Line-based text, JPEG File Interchange Format, data:text/html层,鼠标右键点击 – 选中 导出分组字节流。
如果是菜刀下载文件的流量,需要删除分组字节流前开头和结尾的X@Y字符,否则下载的文件会出错。鼠标右键点击 – 选中 显示分组字节
在弹出的窗口中设置开始和结束的字节(原字节数开头加3,结尾减3)
最后点击Save as按钮导出。 例2.1手机热点(蓝牙传输协议obex,数据提取) 题目来源:第七季极客大挑战 考点:蓝牙传输协议obex,数据提取 题目信息:(Blatand_1.pcapng)
题中说用 没流浪 向电脑传了文件 那肯定是 用的蓝牙 蓝牙协议 为 obex协议 帅选出 obex 协议包 :发现 有一个包 里有一个 rar压缩包:
要分离出 这个 rar 包: 方法一:直接复制 数据块 然后复制到winhex中 转存为 rar 复制数据块 as Hex stream > 在winhex中粘贴 为 ASCII HEX > 删除前面的 多余信息 > 保存为 rar
方法二 :用formost 分离:分离出来好多东西,不过我们目标是rar包
得到一张flag.git:
例2.2 抓到一只苍蝇 这题属于比较难的类型,是文件的分段传输,我们需要将几段数据拼接起来 首先在 分组字节流中 搜索一下 字符串 flag 找到第一个 包,追踪一下数据流 ,
然后就看到了上述信息,知道了应该是在用 qq邮箱传输文件, 文件的信息: fly.rar 文件的大小为 525701 {"path":"fly.rar","appid":"","size":525701,"md5":"e023afa4f6579db5becda8fe7861c2d3","sha":"ecccba7aea1d482684374b22e2e7abad2ba86749","sha3":""} 既然知道了在上传文件,肯定要用到 http的request的 POST方法 在过滤器中 输入 http && http.requesthod==POST然后找到这5个包,第一个包是 文件的信息,后面5个包为数据
分别查看其中 date 的长度: 前四个 为 131436 最后一个为 17777 所以 131436*4 +17777=527571 与第一个包给出的 fly.rar的长度 525701 差 1820 因为每个包都包含头信息,1820/5 = 364 所以每个包的头信息为 364 接下来导出数据包: wireshark->文件->导出对象->http->选择save对象
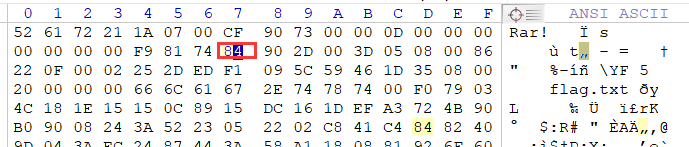
将对应的包 分别save 为 1 2 3 4 5 将这五个包拖进 kali中 执行: dd if=1 bs=1 skip=364 of=11 dd if=2 bs=1 skip=364 of=22 dd if=3 bs=1 skip=364 of=33 dd if=4 bs=1 skip=364 of=44 dd if=5 bs=1 skip=364 of=55将数据包的头部的 364个字节去除 得到 11 22 33 44 55 将这五个包合并 cat 11 22 33 44 55 > fly.rar查看一下 flag.rar的md5值是否正确 md5sum fly.rar正确 解压,跳出提示文件头损坏,并且要求输入密码 知道是伪密码,用winhex打开,修改文件头,将 84 改为 80,保存
解压得到,flag.txt 打开一堆乱码,直接用 foremost分离一下,得到很多的图片 发现一张二维码,扫描后得到flag
flag{m1Sc_oxO2_Fly}
其实我刚开始不是这么做的,我是直接用foremost分离 流量包 ,然后分离出来几张图片 和一个压缩包,尝试解压 爆出一堆错误,并提示输入密码,将 文件头的 84 修改为 80 后依然打不开 ,,可能是 这个文件中还包含了其他错误信息,然后就换用上面的方法了 三,sql注入攻击例3.1信息提取(超详细) 曾经在比赛中也遇过几乎一样的题,一直没有好好的写过一篇详细的博客,今天决定借助这个题好好记录理解一下这种类型的题 提示 : sqlmap 打开流量包,也观察到了 是 用sqlmap进行的 sql盲注的过程,用的是二分法 为了更好的理解 注入的过程 我们首先把 注入语句提取出来,这样方便观察
过滤http流量 ,然后 文件 》导出分组解析结果 》为CSV 保存为 123.txt 用notepad++ 打开 123.txt,可以看到语句语句中还是夹杂着很多的urlcode 全选 , 然后 插件 》MIME Tools 》 url decode ,这样就把URLcode转为更直观的 ascii了
然后再 来理解用 二分法 进行sql盲注的过程 以flag 的第一个字符为 例 :
绿色框中的数字 代表是测试第几个 字符 红色框中的数字 代表 与当前测试的字符的ascii值 相比较的 值 粉色框中数字 代表返回的数据的长度(一会我们要依据这个来判断上面的语句是否正确) ascii有 128个所以从 64 开始判断,然后是96(64和128的中间值),说明>64是正确的 ,才会取96,然后是 80,80小于96,说明>96是错误的,所以才会取 64和96 的中间值 80,然后是 72 ,说明>80是错误的,取80和64之间的中间值72,然后是76,说明>72是正确的,才会取 72 和80之间的中间值76,然后是 74,说明>76是错误的,才会取 72 和76的中间值 74,然后是73,说明>74是错误的,才会取 72 和 74的中间值 73 至于 > 73 语句是否正确,关系到我们最后的取值, 我们已经知道了 第一个字符 的ascii值 的范围 为 72< x 73 正确, 则 x = 74 第一个字符 的ascii值为 74 就是 J 若 >73 错误,则 x = 73 就是 I 由于我们上面已经知道了 >64 是正确的 返回包的数据长度是 467 >96 是错误的 返回包的数据长度是 430 >80 是错误的 返回包的数据长度是 430 >72 是正确的 返回包的数据长度是 467 >76 是错误的 返回包的数据长度是 430 >74 是错误的 返回包的数据长度是 430 可以看到 当判断语句正确时 ,返包的数据长度 是 大于 430的 ,错误时 是小于等于 430 然后看到 最后一条语句 >73 的返回值 为 430,说明与错误, 第一个字符的ascii 为 73
理解了过程就好做多了 我们只需要 找到 当前测试字符的 最后一条的测试语句的 ascii值 和 返回值 如果返回值大于 430 则 当前测试字符的ascii 值 为 最后一条测试语句的ascii值 如果返回值 小于等于 430 则 当前测试字符的ascii值 为 最后一条测试语句的ascii + 1
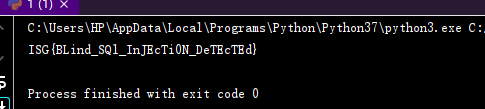
方法一:(当flag 较短的时候) 当flag较短的时候,我们肯定是用手工 一个一个记下 每个字符的ascii值 比较快 方法二: (当flag 较长时) 当flag 为 25个字符以上的时候,手工就显得太费劲,不如写个脚本来的快,就想本题一样,flag的长度为 33 上脚本: import re import urllib.parse # 更改为自己从wireshark提取出的csv文件地址 f = open(r"123.txt") lines = f.readlines() datas = [] # 转码, 保存进datas for line in lines: datas.append(urllib.parse.unquote(line)) lines = [] # 懒得改, 就复用一下, 这个lines保存注入flag的url for i in range(len(datas)): # 提取出注入flag的url if datas[i].find("isg.flags ORDER BY `value` LIMIT 0,1),1,1))>64") > 0: lines = datas[i:] break flag = {} # 用正则匹配 macth1 = re.compile(r"LIMIT 0,1\),(\d*?),1\)\)>(\d*?) HTTP/1.1") macth2 = re.compile(r'"HTTP","(\d*?)","HTTP/1.1 200 OK') for i in range(0, len(lines), 2): # 因为有返回响应, 所以步长为2 get1 = macth1.search(lines[i]) if get1: key = int(get1.group(1)) # key保存字符的位置 value = int(get1.group(2)) # value保存字符的ascii编码 get2 = macth2.search(lines[i + 1]) if get2: if int(get2.group(1)) > 450: value += 1 flag[key] = value # 用字典保存flag f.close() result = '' for value in flag.values(): result += chr(value) print(result)为什么脚本中 判断的返回值取 450 呢? 因为 取430时,得出来的flag不对,仔细查看123.txt后,发现 其中还有一些错误的语句的返回 包 为 431 或者 432,所以就干纯粹取个 450 (433~460都可以) (这再看不懂就考虑换专业吧) 得到flag:
ISG{BLind_SQl_InJEcTi0N_DeTEcTEd}
例3.2日志审计 用 notepad++ 打开 日志文件,先用 插件中的 MIME Tool 中的 URL decode 解一下码 然后就能清楚的看出来 是在进行 sql 盲注操作, 进一步审查,还可以看到每一条语句 返回的状态码 ,并且知道 他是用的 二分法在进行 sql盲注 我需要做的就是找到 每一个 测试的字符的 最后一条状态码为 200 的 语句中的 ascii 值并记录下来 例如:
由于使用的是二分法,所以我们这里可以知道 flag的第 18 个字符的ascii 为 117+1 ,118 当然你你也可以用手工的方法,一个一个的记下 flag 每一个 字符的 ascii 值 (flag也就 25个字符,如果写不出代码的话) 当然最好是用脚本跑出来 我找了个脚本: # coding:utf-8 import re import urllib f = open('access.log', 'r') lines = f.readlines() datas = [] for line in lines: t = urllib.unquote(line) # 过滤出与flag相关,正确的猜解,这里只收集正确的猜解,而测试字符的ascii = 最后一个正确的猜解的ascii +1(这是二分法的一个隐藏规律) if '200 1765' in t and 'flag' in t: datas.append(t) flag_ascii = {} for data in datas: matchObj = re.search(r'LIMIT 0,1\),(.*?),1\)\)>(.*?) AND', data) if matchObj: key = int(matchObj.group(1)) value = int(matchObj.group(2)) + 1 flag_ascii[key] = value # 使用字典,保存最后一次猜解正确的ascii码 flag = '' for value in flag_ascii.values(): flag += chr(value) print flag解释一下: t = urllib.unquote(line) 就是将 文本进行 urldecode 解码 if '200 1765' in t and 'flag' in t: 如果语句中有这两个字符串就直接将这个语句 存入 数组datas中 datas.append(t) matchObj = re.search(r'LIMIT 0,1\),(.*?),1\)\)>(.*?) AND', data) 在date 中搜索符合 正则表达的 字符串并 将匹配的字符串存入变量 matchObj 中 key = int(matchObj.group(1)) 取 变量matchObj 中 的第一个括号里的内容 (也就是上条语句中的 (.*?)中的内容)并转为10进制 value = int(matchObj.group(2)) + 1 取 变量matchObj 中 的第二个括号里的内容,并转为 10 进制
得到 flag:flag{sqlm4p_15_p0werful} 四,访问特定的加密解密网站(md5,base64) 例4.1:你能找到我吗? 打开流量包,在分组字节流中搜索 字符串 flag,找到了几个包,但都没有什么可利用的信息
然后尝试着过滤出http包,(别问我为什么要过滤出http包,经验告诉我http有问题的可能性最大) 然后就剩6个包了:
点击第一个包,右键 追踪流 》http 然后仔细审查这个包,发现了base64 ,访问域名:http://tool.chinaz.com/Tools/Base64.aspx 发现是个base64加密解密的网站:
然后把 result后面的密文复制下来,解密两次 拿到了flag:sdut2019{Traffic_analysis_seclab507} 五,后台扫描+弱密码爆破+菜刀 例5.1,中国菜刀 在 分组字节流中搜索 flag 字符串,找到第8 个包,追踪tcp数据流
看到了 flag.tar.gz,猜测流量包中隐藏了一个压缩包, 用binwalk 审查一下:发现了一个压缩包,分离
key{8769fe393f2b998fa6a11afe2bfcd65e} 例5.2 密码爆破 flag为flag{管理员入口 地址 + 管理员密码 } 找不到源文件了,大致的过程就是 黑客先利用后台扫描工具,扫描出来了网站的后台管理员入口 然后用 用户名 admin 进行密码的暴力破解,破解成功,然后干了些猥琐的事情的过程 我们需要找到黑客扫描到的 管理员入口的地址 并找到他破解出admin 的密码 六,usb流量分析 usb流量分析,包括usb键盘流量,usb鼠标流量 键盘流量数据为 8个字节 鼠标流量数据为 4个字节 (具体每个字节代表些啥,自行百度) 例6.1:usb流量分析 打开流量包:看到的确是usb流量,并且没有杂包(如果有不是usb的包需提前滤除掉)
把这个包放进linux中提取数据: tshark -r example.pcap -T fields -e usb.capdata > usbdata.txt然后就得到了 usbdata.txt文件:
看到每行为8个字节,确定是 键盘流量数据, 然后用脚本进行处理得到flag: normalKeys = {"04": "a", "05": "b", "06": "c", "07": "d", "08": "e", "09": "f", "0a": "g", "0b": "h", "0c": "i", "0d": "j", "0e": "k", "0f": "l", "10": "m", "11": "n", "12": "o", "13": "p", "14": "q", "15": "r", "16": "s", "17": "t", "18": "u", "19": "v", "1a": "w", "1b": "x", "1c": "y", "1d": "z", "1e": "1", "1f": "2", "20": "3", "21": "4", "22": "5", "23": "6", "24": "7", "25": "8", "26": "9", "27": "0", "28": "", "29": "", "2a": "", "2b": "\t", "2c": "", "2d": "-", "2e": "=", "2f": "[", "30": "]", "31": "\\", "32": "", "33": ";", "34": "'", "35": "", "36": ",", "37": ".", "38": "/", "39": "", "3a": "", "3b": "", "3c": "", "3d": "", "3e": "", "3f": "", "40": "", "41": "", "42": "", "43": "", "44": "", "45": ""} shiftKeys = {"04": "A", "05": "B", "06": "C", "07": "D", "08": "E", "09": "F", "0a": "G", "0b": "H", "0c": "I", "0d": "J", "0e": "K", "0f": "L", "10": "M", "11": "N", "12": "O", "13": "P", "14": "Q", "15": "R", "16": "S", "17": "T", "18": "U", "19": "V", "1a": "W", "1b": "X", "1c": "Y", "1d": "Z", "1e": "!", "1f": "@", "20": "#", "21": "$", "22": "%", "23": "^", "24": "&", "25": "*", "26": "(", "27": ")", "28": "", "29": "", "2a": "", "2b": "\t", "2c": "", "2d": "_", "2e": "+", "2f": "{", "30": "}", "31": "|", "32": "", "33": "\"", "34": ":", "35": "", "36": "", "38": "?", "39": "", "3a": "", "3b": "", "3c": "", "3d": "", "3e": "", "3f": "", "40": "", "41": "", "42": "", "43": "", "44": "", "45": ""} output = [] keys = open('usbdata.txt') for line in keys: try: if line[0]!='0' or (line[1]!='0' and line[1]!='2') or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0' or line[6:8]=="00": continue if line[6:8] in normalKeys.keys(): output += [[normalKeys[line[6:8]]],[shiftKeys[line[6:8]]]][line[1]=='2'] else: output += ['[unknown]'] except: pass keys.close() flag=0 print("".join(output)) for i in range(len(output)): try: a=output.index('') del output[a] del output[a-1] except: pass for i in range(len(output)): try: if output[i]=="": flag+=1 output.pop(i) if flag==2: flag=0 if flag!=0: output[i]=output[i].upper() except: pass print ('output :' + "".join(output))例6.2 usb流量 打开发现有大量的usb协议的流量包,不过其中有很多的杂包,
发现其中有一大段是 4个字节的 usb数据(鼠标数据) 先将这些鼠标流量的包过滤出来, usb.src == "2.3.1" 过滤后,文件 》导出特殊分组 》保存为 jjj.pcap 把jjj.pcap放进linux中: tshark -r jjj.pcap -T fields -e usb.capdata > usbdata.txt生成usbdata.txt文件,然后将usbdata.txt中的鼠标流量数据转换为坐标 nums = [] keys = open('usbdata.txt','r') file = open('xy.txt','w') posx = 0 posy = 0 for line in keys: if len(line) != 12 : continue x = int(line[3:5],16) y = int(line[6:8],16) if x > 127 : x -= 256 if y > 127 : y -= 256 posx += x posy += y btn_flag = int(line[0:2],16) # 1 for left , 2 for right , 0 for nothing if btn_flag == 1 : string = str(posx) + ' '+str(posy) +'\n' file.write(string) keys.close() file.close()生成了xy.txt文件:
然后在linux中 执行 gnuplot >plot "xy.txt"就得到了用鼠标画的图了:
七,WiFi无线密码破解 例7.1题目:想蹭网先解开密码(无线密码破解) 题目来源:bugku 考点:无线密码破解 题目信息:(wifi.cap)
wifi 连接认证 的重点在于 WAP的 四次握手过程 ,就是 EAPOL 协议的包,
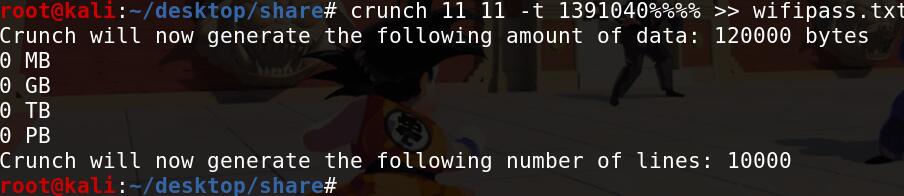
存在 握手过程:直接进行爆破: 先用 linux中的 crunch 生成一个字典:
然后 用 aircrack-ng 进行爆破: 得到 WiFi密码:13910407686 八,根据一组流量包了解黑客的具体行为 参考:https://jwt1399.top/2019/07/29/ctf-liu-liang-fen-xi-zong-jie/(想要下面例子源文件的去看看) 例8.1 (1.pcap) 2018信息安全铁人三项数据赛
打开流量包,流量包有点大,打开比较慢,这里我们先过滤为HTTP协议可以看到202.1.1.2对192.168.1.8进行了疯狂的爆破
不难看出,黑客利用的SqlMap在对目标站点进行不断的SQL试探注入因此受害主机的网卡IP地址为192.168.1.8 而注入的参数也可以清晰的看见,为list[select] 追踪http流,根据回显内容,目标站点数据库抛出的错误,可以清晰的看见
不难确定,目标站点的数据库表名前缀为ajtuc_ 接着为了确定受害主机网站数据库的名字,再进行了一次过滤 (ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http此时挑选最后一次注入的payload进行url解码
可以清楚的看到 FROM joomla.ajtuc_users因此数据库名为joomla 所以答案: 1.黑客攻击的第一个受害主机的网卡IP地址 192.168.1.8 2.黑客对URL的哪一个参数实施了SQL注入 list[select] 3.第一个受害主机网站数据库的表前缀(加上下划线例如abc_) ajtuc_ 4.第一个受害主机网站数据库的名字 joomla例8.2(2.pcap) 题目来源:2018信息安全铁人三项数据赛
根据题目一已确定目标ip,所以依旧使用以下过滤简化操作 (ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http可以看到一个奇怪文件kkkaaa.php,跟进POST数据查看
不难发现,是中国菜刀的流量,木马密码为zzz 接着确定黑客第二次上传php木马的时间 我进行了过滤,猜想黑客应该是根据第一个木马来上传的第二个木马 (ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http.requesthod==POST此时一条数据格外引人注目
我们对其16进制进行分析
将保存的值放入winhex中得到源码
将文件保存为php,但是代码经过混淆过的,在代码末尾加上下面两句代码 var_dump($j); var_dump($x);运行php进行解混淆,发现这就是木马
由此可确定这个引人注目的包上传了第二个木马 因此上传时间为:17:20:44.248365 还是使用过滤 (ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http然后可以看到许多请求footer.php的页面,点开一个查看详情
容易发现referer数据十分可疑,而ACCEPT_LANGUAGE较为正常 所以可以基本确定,木马通过HTTP协议中的Referer头传递数据 答案 1.黑客第一次获得的php木马的密码是什么 zzz 2.黑客第二次上传php木马是什么时间 17:20:44.248365 3.第二次上传的木马通过HTTP协议中的哪个头传递数据 Referer例.8.3(3.pcap) 题目来源:2018信息安全铁人三项数据赛
直接进行过滤 tcp contains "mysql" && mysql得到大量数据,可以发现黑客应该在对Mysql的登录进行爆破,内网受害机器为192.168.2.20
我们找到最后一条登录数据
该值就为我们需要的mysql密码hash了 简单过滤一下 (ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http
目标机器已经被挂上了tunnel.php,方便外网对内网的访问 为方便查看黑客操作,我们过滤出POST请求 (ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http.requesthod==POST && http
我们清晰的看见黑客的php代理第一次使用时最先连接4.2.2.2这个ip,并且端口为53 答案 1.内网主机的mysql用户名和请求连接的密码hash是多少(用户:密码hash) admin:1a3068c3e29e03e3bcfdba6f8669ad23349dc6c4 2.php代理第一次被使用时最先连接了哪个IP地址 4.2.2.2例8.4(4.pcap) 题目来源:2018信息安全铁人三项数据赛
为确定黑客第一次获取到当前目录下的文件列表的漏洞利用请求发生在什么时候,我们继续进行过滤 (ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && (http contains "dir" || http contains "ls")
此时一条为ls,一条为dir,我们先对ls的进行验证 追踪其tcp流 发现并没有执行成功,再对dir进行验证
于是可以确定无误,目标系统为windows,同时dir命令执行成功 时间为:18:37:38.482420 既然该192.168.2.20的机器可以执行命令,于是我改变过滤方式,查看黑客如何进行攻击 ip.addr == 192.168.2.20 && http
可以看到上面几条受害机器分别执行了 dir ,pwd,dir,以及echo%20.....等命令 不难发现,黑客利用echo命令写入了一个名为sh.php的后门 然后往下翻看到黑客利用这个后门post 了一些东西,猜测应该是木马文件,看一下:
果然,木马的密码是123,是中国菜刀的流量 我们进一步跟进黑客执行的指令,由于是中国菜刀流量,我们选择根据回显明文,猜测指令,这样更有效率 ip.src == 192.168.2.20 && http在18:50:09.344660时,我们发现可疑操作,我们发现一条可疑数据,判断黑客应该是执行了net user的命令
然后在18:50:42.908737发现黑客再次执行了net user命令 此时回显为:
看来黑客成功添加了管理员用户kaka 确定了大致的作案时间,我们即可使用过滤 确定了大致的作案时间,我们即可使用过滤 ip.addr == 192.168.2.20 && http根据之前的判断,我们可以知道 18:49:27.767754时,不存在kaka用户
在此期间,一共4个POST请求,我们挨个查看,果不其然,在第一个POST中就发现了问题 Y2QvZCJDOlxwaHBTdHVkeVxXV1dcYjJldm9sdXRpb25caW5zdGFsbFx0ZXN0XCImbmV0IHVzZXIg a2FrYSBrYWthIC9hZGQmZWNobyBbU10mY2QmZWNobyBbRV0=解码后 cd/d"C:\phpStudy\WWW\b2evolution\install\test\"&net user kaka kaka /add&echo [S]&cd&echo [E]可以明显看到 net user kaka kaka /add于是可以断定,用户名和密码均为kaka 最后一题既然是下载,应该是利用中国菜刀进行下载了,那我们只过滤出post流量,查看命令即可 ip.dst == 192.168.2.20 && http.requesthod==POST然后我们在数据包的最后发现如下数据
我们将其解码
发现使用了procdump.exe 同时发现文件
解码得到
最后我们可以确定,黑客下载了lsass.exe_180208_185247.dmp文件 答案 1.黑客第一次获取到当前目录下的文件列表的漏洞利用请求发生在什么时候 18:37:38.482420 2.黑客在内网主机中添加的用户名和密码是多少 kaka:kaka 3.黑客从内网服务器中下载下来的文件名 lsass.exe_180208_185247.dmp
|










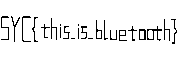













































 18:50:42.908737时,kaka用户已成为管理员 所以可以断定作案时间点在这段时间内
18:50:42.908737时,kaka用户已成为管理员 所以可以断定作案时间点在这段时间内



【本文地址】