| MMPose姿态估计+人体关键点识别效果演示 | 您所在的位置:网站首页 › 根据图片识别视频格式 › MMPose姿态估计+人体关键点识别效果演示 |
MMPose姿态估计+人体关键点识别效果演示
|
MMPose——开源姿态估计算法库(附人体关键点识别效果演示)
一、简介
1.1 背景
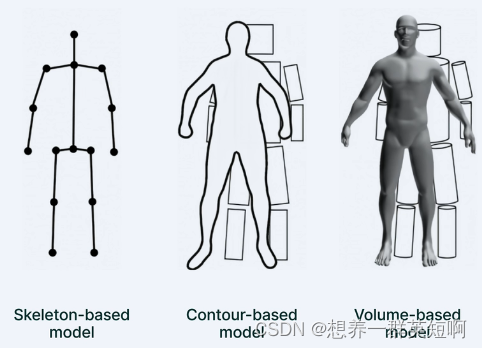
首先姿态估计属于计算机视觉领域的一个基础研究方向。MMPose是基于Pytorch的姿态估计开源算法库,功能全,涵盖的算法多。 1.2 姿态估计的任务分类维度:预测的是2D还是3D姿态。 输入格式:图片 or 视频 姿态的表示形式:关键点 or 形状等 目标类型:全身 or 人脸 or 人手 or 动物 or 服饰 1.3 关于人体姿态估计任务Human Pose Estimation是关键点检测任务中最热门的任务,即进行人体骨架和关节的关键点检测。 人体姿态估计任务的扩展:包括基于骨架的、基于表面的、基于三维空间立体的。
例如:facebook提出的Dense pose。将整个人体表面进行包络。(伪3D),并没有将3维坐标还原出来。如果要做3D,用三维人体重建的库MMHuman3D。 关于视频理解(MMAction2)与人体姿态估计的关系:视频动作理解的基础就是人体姿态估计。先得把骨骼关键点构建出来,才能根据这些特征判断动作。MMAction2可以参考这篇:关于MMAction2 论文链接:DensePose 1.4 MMPose的相关贡献(1)2D Human Pose(包括body+hand+face一共133个关键点) (2)3D Human Pose(先检测人体,再检测2D Human Pose,再检测3D Human Pose)
(3)3D Human Pose(人体网格重建任务——从image中恢复人体网格)
(4)3D Hand Pose(基于RGB图像的2D和3D手势联合估计)
(5)其他还包括脸部关键点,animal pose,目标跟踪等等。 二、MMPose所涉及的算法★这里先解释一下Regression和Heatmap Regression:直接用模型回归预测得到每一个关键点的坐标Heatmap: 不直接回归关键点本身的像素坐标,而是生成一张图,表示图中不同区域是该关键点的置信度。例如,人身上有14个关键点,就会生成14张heatmap,每个关键点处就会存在概率分布。 2.1 基于关键点坐标回归(Regression based)
2.1 基于关键点坐标回归(Regression based)
DeepPose就是这一类方法的经典代表。直接回归关键点坐标的方法思路比较简单,预测速度快,但直接预测坐标的精度会受到一定影响。
基于heatmap的方式逐渐成为主流。该方法会去每个位置预测一个分数,来表征该位置是关键点的置信度。根据预测到的heatmap,可以进一步去提取关键点的位置。由于该方法可以更好地保留空间信息,更符合CNN的设计特性,精度也比坐标直接回归更高。
主要分为两种方法:自顶向下、自底向上 自顶向下(TopDown):先检测处图片中的人体,再对每一个人体单独预测关键点。该方法的计算量会随着人数的增多而上升,但对不同尺寸的人体更加鲁棒,精度更高。通俗来说,该方法更准确。 自底向上(BottomUp):先去检测到所有的关键点,再进行关键点聚类,组合成人体。该方法的计算量不会随着人数的增多而上升。通俗来说,该方法更快(人更多的时候越明显)。
主要在3维空间里去预测人的位置,根据输入不同,可以分为以下3种方法 基于单目图像从2D Pose预测3D Pose这种方法的经典代表:SimpleBaseline3D。根据2Dpose和原始图像的特征,直接估计3D Pose。但是基于单目图像会存在遮挡问题。
这种方法的经典代表:VoxelPose。解决遮挡问题,例如一个场景有很多人,可以融合多视角的信息去重建3D Pose。
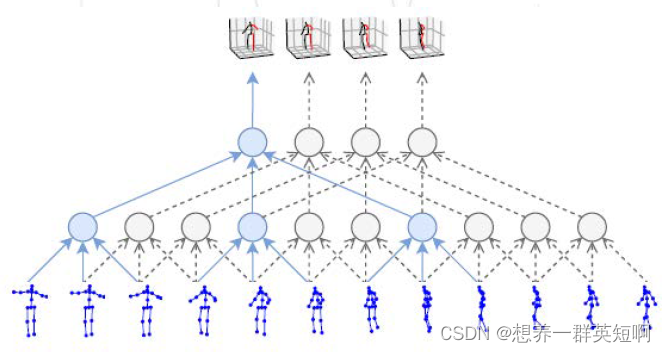
论文链接:VoxelPose 基于视频(多帧)信息在以上两种方法的基础上,引入时间维度,相邻的上下文信息可以辅助更好的预测。例如之前看的ViPNAS就是用上下文信息来辅助更好的预测。 这种方法的经典代表:VideoPose3D。用2D关键点序列(多了时间维度,就是有好几帧)作为输入,然后通过时序的卷积网络去处理信息,最后输出3DPose。
论文链接:VideoPose3D 三、MMPose所用的数据集 3.1 姿态估计关键点数据集(2D)基于图像:COCO
基于视频:PoseTrack18
基于单人:Human3.6M(360万个人体pose的标注)
基于多视角:CMU Panoptic
基于手部:InterHand2.6M
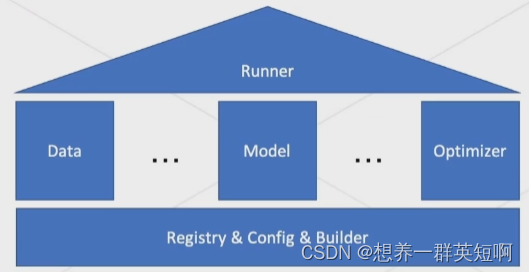
将深度学习拆分成data(数据集)、model(模型)、optimizer(优化器)等组件,先把每一个小模块做好,再注册到registry(注册器)里,注册器里包含了很多功能类似的模块。在需要启动任务时,通过config配置系统,代码就会调用builder,从而构造一整套流程。减少了代码的耦合。 4.2 用户接口在架构上,mmpose使用了mmcv提供的底层的接口,通过runner去管理模型的训练、测试、推理等。
(1)Dataloader:sample定义 + pipline (Dataloader文件所在位置:Dataloader) 在dataloader方面,mmpose提供了一些数据集的接口,里面定义了sample和需要经过的pipline datasets文件夹:完成数据加载,准备pipline的输入,在evaluate函数里计算metric piplines文件夹:pipline是数据预处理的流水线,由一系列的transform组成,每个transform的输入和输出都是字典。例如,LoadImageFromFile就是从文件中读取图像,ToTensor就是将读取的图像转化为pytorch的tensor。 samplers文件夹:sampler就是采样器。sampler提供dataset里数据的索引,然后dataloader根据索引从dataset里提取出对应的data。然后将data输给网络进行training。(2)Model:backbone + (neck) + head (Model文件所在位置:models) 在模型层面,会把模型 分为backbone,neck,head三个部分 detectors文件夹:pose的检测器。通常由backbone,neck,head组成。例如TopDown。backbones文件夹:主干网络。例如ResNet,HRNet,HRFormer等就在这里定义。necks文件夹:处理backbone得到的特征heads文件夹:预测头,输出最终预测结果。(loss定义在head中) 4.4 其他文件夹(1)apis(https://github.com/open-mmlab/mmpose/tree/master/mmpose/apis) 封装训练,测试和推理等流程 train.py:准备数据加载,把模型加载到GPU,构建optimizer和runner,注册hooks等 test.py:模型测试。需要输入模型和dataloader,测试模型精度。 inference.py:模型推理,进行可视化等工作。 Webcam API:调用MMpose及其他算法,实现基于摄像头输入视频的交互式应用。 (2)cores:(https://github.com/open-mmlab/mmpose/tree/master/mmpose/core) 前后处理,可视化,定制工具等 (3)tools:(https://github.com/open-mmlab/mmpose/tree/master/tools) train.py:启动训练任务的入口,读入config,初始化训练环境,创建模型及数据集等,调用apis/train.pytest.py:模型推理测试的接口,数据集开启test_mode,加载checkpoint,调用apis/test.py运行测试分布式训练的启动脚本:dist_train.sh——通过pytorch启动分布式 slurm_train.sh——通过slrum(一种集群式管理系统)启动分布式 五、MMPose相关效果演示 5.1 安装配置本机环境:GPU RTX 2060、CUDA v11.1 Pytorch版本:1.8.0 torchvision版本:0.9.0 编译器版本:MSVC 192930137 mmtracking mmpose:0.28.1 5.2 对图像中人体的关键点检测(1)TopDown 这里使用TopDown方法对图像进行预测 先用目标检测把人的框检测出来:faster_rcnn网络 再做框里的人的姿态估计与关键点检测:hrnet网络 效果展示
(2)BottomUp 这里不需要目标检测模型,只需要bottom up人体姿态估计模型人体关键点检测模型:hrnet效果精度并不如TopDown,会存在部分关键点之间的错误连接。但是在人更多的情况下速度会比TopDown快。
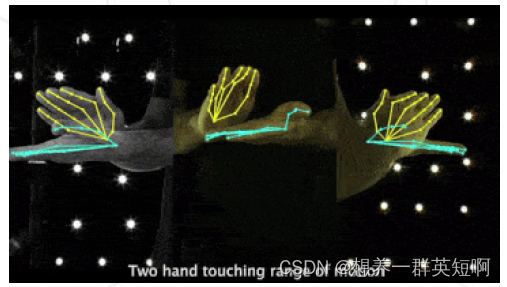
(1)单帧输入模型的视频预测 这里使用TopDown方法对视频进行预测 目标检测与关键点识别的网络依然是faster_rcnn和hrnet 效果展示 MMPose——单帧输入视频预测 关于多帧输入模型的视频预测,就是将视频前后多帧画面输入模型用于姿态预测。相比于单帧输入,检测到的会更细,例如橱窗里的模特,广告牌上的人也会被检测到。但是同样,计算量也会大很多。(2)全图输入模型的视频预测 不提取人体检测框,直接将全图输入至姿态估计模型中。仅适用于单人,并且单人的效果并不好 这里使用TopDown的全图输入方法对视频进行预测 没有目标检测模型 人体关键点检测网络:vipnas 效果展示 MMPose——全图输入模型的视频预测 (3)BottomUp算法的视频预测 同样,精度效果不如TopDown 人体姿态估计模型:hrnet MMPose——BottomUp算法的视频预测 5.4 对图像和视频中手掌的关键点检测 Topdown算法目标检测模型:cascade_rcnn手部关键点检测模型:res50效果展示:在存在少部分遮挡的情况下,会存在部分关键点的误识别,但基本上手部关键点都检测正确
在没有遮挡的情况下,手部关键点全都准确识别。
视频中的手部关键点识别效果也不错 MMPose——手掌关键点检测 5.5 对图像和视频中全身的关键点检测 Topdown算法目标检测模型:faster_rcnn全身关键点检测模型:hrnet效果展示
视频中关键点检测效果也不错 MMPose——全身关键点检测(人脸+手+肢体) 5.6 MMPose摄像头实时效果实时的效果一般,目标检测的fps为20左右,人体姿态估计的fps为10左右
|



 论文链接:DeepPose
论文链接:DeepPose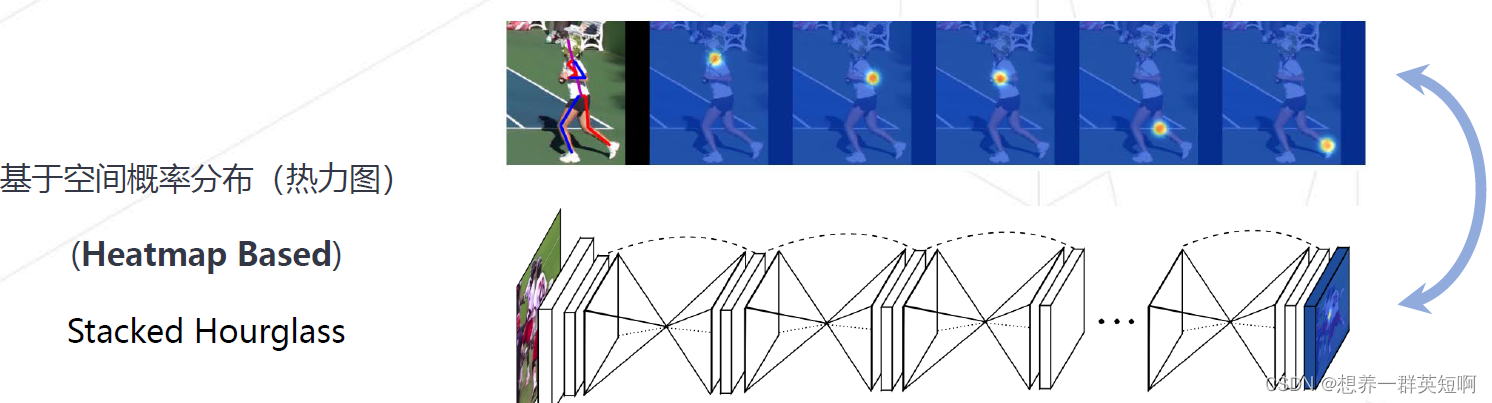 论文链接:Stacked Hourglass
论文链接:Stacked Hourglass
 论文链接:SimpleBaseline3D
论文链接:SimpleBaseline3D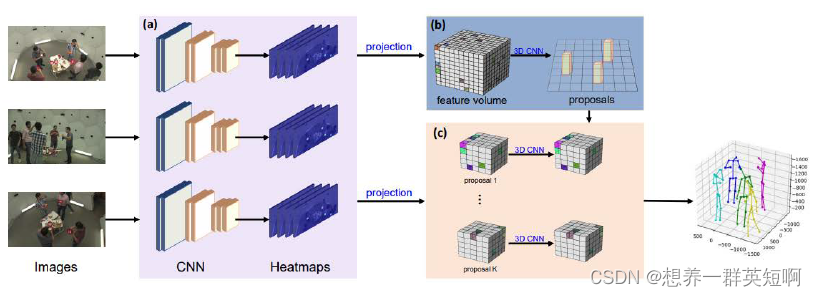











【本文地址】