| 06 PCA(主成分分析)之特征值分解 | 您所在的位置:网站首页 › 样本量太小与样本特征值的关系是什么 › 06 PCA(主成分分析)之特征值分解 |
06 PCA(主成分分析)之特征值分解
|
参考博客: 主成分分析(PCA)原理详解 PCA (主成分分析)详解 (写给初学者) PCA之特征分解 1. 相关背景2. 数据降维3. PCA原理详解3.1 什么是PCA3.2 协方差和散度矩阵3.3 特征值分解矩阵原理3.4 SVD分解矩阵原理3.5 PCA算法两种实现方法(1) 基于特征值分解协方差矩阵实现PCA算法(2) 基于SVD分解协方差矩阵实现PCA算法 4 PCA实例 ](PCA之特征分解) 在机器学习领域,PCA算是用的蛮多的了。最近也是在学这个的时候发现了个蛮有意思的事情,PCA求解分为俩种方法:一种基于线性代数,一种基于梯度上升(梯度上升我会在写篇博客)。所以让我有点不知道怎么划分这篇博客序号(感觉放在梯度下降法会好点)。当然,这些属于闲谈不提。PCA(PrincipalComponents Analysis)即主成分分析,是图像处理中经常用到的降维方法,大家知道,我们在处理有关数字图像处理方面的问题时,比如经常用的图像的查询问题,在一个几万或者几百万甚至更大的数据库中查询一幅相近的图像。 这时,我们通常的方法是对图像库中的图片提取响应的特征,如颜色,纹理,sift,surf,vlad等特征,然后将其保存,建立响应的数据索引,然后对要查询的图像提取相应的特征,与数据库中的图像特征对比,找出与之最近的图片。 这里,如果我们为了提高查询的准确率,通常会提取一些较为复杂的特征,如sift,surf等,一幅图像有很多个这种特征点,每个特征点又有一个相应的描述该特征点的128维的向量,设想如果一幅图像有300个这种特征点,那么该幅图像就有300*vector(128维)个,如果我们数据库中有一百万张图片,这个存储量是相当大的,建立索引也很耗时,如果我们对每个向量进行PCA处理,将其降维为64维,是不是很节约存储空间啊? 1. 相关背景在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。 因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。主成分分析与因子分析就属于这类降维算法。 2. 数据降维降维就是一种对高维度特征数据预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。 降维具有如下一些优点: 使得数据集更易使用。降低算法的计算开销。去除噪声。使得结果容易理解。降维的算法有很多,比如奇异值分解(SVD)、主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)。 3. PCA原理详解 3.1 什么是PCAPCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。 PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。 事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。 由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。 3.2 协方差和散度矩阵样本均值: X ‾ = ∑ i = 1 n X i n \overline{X}= \frac{\sum_{i=1}^n X_i}{n} X=n∑i=1nXi 标准差: s = ∑ i = 1 n ( X i − X ‾ ) 2 n − 1 s= \sqrt{\frac{\sum_{i=1}^n(X_i-\overline{X})^2}{n-1}} s=n−1∑i=1n(Xi−X)2 方差: s 2 = ∑ i = 1 n ( X i − X ‾ ) 2 n − 1 s^2 = \frac{\sum_{i=1}^n(X_i-\overline{X})^2}{n-1} s2=n−1∑i=1n(Xi−X)2 既然我们都有这么多描述数据之间关系的统计量,为什么我们还要用协方差呢?我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解这几科成绩之间的关系,这时,我们就要用协方差,协方差就是一种用来度量两个随机变量关系的统计量,其定义为: C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = ∑ i = 1 n ( X i − X ‾ ) ( Y i − Y ‾ ) n − 1 Cov(X,Y)= E[(X-E(X))(Y-E(Y))]= \frac{\sum_{i=1}^n(X_i-\overline{X})(Y_i-\overline{Y})}{n-1} Cov(X,Y)=E[(X−E(X))(Y−E(Y))]=n−1∑i=1n(Xi−X)(Yi−Y) 其性质如下: c o v ( X , X ) = v a r ( X ) cov(X,X)=var(X) cov(X,X)=var(X),也就是X的方差 c o v ( X , Y ) = c o v ( Y , X ) cov(X,Y)=cov(Y,X) cov(X,Y)=cov(Y,X) 由上面的公式,我们可以得到以下结论:(1) 方差的计算公式是针对一维特征,即针对同一特征不同样本的取值来进行计算得到;而协方差则必须要求至少满足二维特征;方差是协方差的特殊情况。 (2) 方差和协方差的除数是n-1,这是为了得到方差和协方差的无偏估计。 协方差为正时,说明X和Y是正相关关系;协方差为负时,说明X和Y是负相关关系;协方差为0时,说明X和Y是相互独立。Cov(X,X)就是X的方差。当样本是n维数据时,它们的协方差实际上是协方差矩阵(对称方阵)。给出协方差矩阵的定义: C n × n = ( c i , j , c i , j = c o v ( D i m i , D i m j ) C_{n×n}=(c_{i,j},c_{i,j} = cov(Dim_i,Dim_j) Cn×n=(ci,j,ci,j=cov(Dimi,Dimj) 这个定义还是很容易理解的,我们可以举一个简单的三维的例子 ( x , y , z ) (x,y,z) (x,y,z),假设数据集有三个维度,则协方差矩阵为: C = ( c o v ( x , x ) c o v ( x , y ) c o v ( x , z ) c o v ( y , z ) c o v ( y , y ) c o v ( y , z ) c o v ( z , x ) c o v ( z , y ) c o v ( z , z ) ) C = \begin{pmatrix} cov(x,x) ; cov(x,y) ; cov(x,z)\\ cov(y,z) ; cov(y,y) ; cov(y,z) \\ cov(z,x) ; cov(z,y) ; cov(z,z)\end{pmatrix} C=⎝⎛cov(x,x)cov(y,z)cov(z,x)cov(x,y)cov(y,y)cov(z,y)cov(x,z)cov(y,z)cov(z,z)⎠⎞ 可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。 散度矩阵定义为: S = ∑ k = 1 n ( x k − m ) ( x k − m ) T S = \sum_{k=1}^n (x_k-m)(x_k-m)^{T} S=k=1∑n(xk−m)(xk−m)T其中,m是均值向量(mean vector): m = 1 n ∑ k = 1 n x k m = \frac{1}{n} \sum_{k=1}^n {x}_k m=n1k=1∑nxk 注意:下x,m均为向量。 对于数据X的散度矩阵为。其实协方差矩阵和散度矩阵关系密切,散度矩阵就是协方差矩阵乘以(总数据量-1)。因此它们的特征值和特征向量是一样的。这里值得注意的是,散度矩阵是SVD奇异值分解的一步,因此PCA和SVD是有很大联系。 3.3 特征值分解矩阵原理(1) 特征值与特征向量 如果一个向量v是矩阵A的特征向量,将一定可以表示成下面的形式: A v = λ v Av = \lambda v Av=λv 其中,λ是特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。 (2) 特征值分解矩阵 对于矩阵A,有一组特征向量v,将这组向量进行正交化单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵A分解为如下式: A = Q Σ Q − 1 A = QΣ Q^{-1} A=QΣQ−1 其中,Q是矩阵A的特征向量组成的矩阵, ∑ \sum ∑则是一个对角阵,对角线上的元素就是特征值。 3.4 SVD分解矩阵原理奇异值分解是一个能适用于任意矩阵的一种分解的方法,对于任意矩阵A总是存在一个奇异值分解: A = U Σ V T A = UΣ V^{T} A=UΣVT 假设A是一个mn的矩阵,那么得到的U是一个mm的方阵,U里面的正交向量被称为左奇异向量。Σ是一个mn的矩阵。Σ除了对角线其它元素都为0,对角线上的元素称为奇异值。 V T V^{T} VT是v的转置矩阵,是一个nn的矩阵,它里面的正交向量被称为右奇异值向量。而且一般来讲,我们会将Σ上的值按从大到小的顺序排列。 SVD分解矩阵A的步骤: 求 A A T AA^T AAT的特征值和特征向量,用单位化的特征向量构成 U。求 A A T AA^T AAT的特征值和特征向量,用单位化的特征向量构成 V。将求 A A T AA^T AAT或者求 A T A A^TA ATA的特征值求平方根,然后构成 Σ。 3.5 PCA算法两种实现方法 (1) 基于特征值分解协方差矩阵实现PCA算法输入:数据集 X = ( x 1 . x 2 , x 3 , , … , x n ) X = (x_1.x_2,x_3,,…, x_n) \quad X=(x1.x2,x3,,…,xn),需要降到k维。 去平均值(即去中心化),即每一位特征减去各自的平均值。 2)计算协方差矩阵 1 n X X T \frac{1}{n}XX^T n1XXT,注:这里除或不除样本数量n或n-1,其实对求出的特征向量没有影响。用特征值分解方法求协方差矩阵 1 n X X T \frac{1}{n}XX^T n1XXT的特征值与特征向量对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。将数据转换到k个特征向量构建的新空间中,即Y=PX。举个例子: X = ( − 1 − 1 0 2 0 − 2 0 0 1 1 ) X = \begin{pmatrix} -1 ; -1 ; 0 ; 2 ; 0 \\ -2 ; 0 ; 0 ; 1 ; 1 \\ \end{pmatrix} X=(−1−2−10002101) 以X为例,我们用PCA方法将这两行数据降到一行。 1)因为X矩阵的每行已经是零均值,所以不需要去平均值。 2)求协方差矩阵: 求解后的特征值为: λ 1 = 2 , λ 2 = 2 5 \lambda_1 = 2, \lambda_2 = \frac{2}{5} λ1=2,λ2=52 对应的特征向量为: c 1 ( 1 1 ) , c 2 ( − 1 1 ) c_1 \begin{pmatrix} 1 \\ 1\\ \end{pmatrix}, c_2 \begin{pmatrix} -1 \\ 1 \\ \end{pmatrix} c1(11),c2(−11) 其中对应的特征向量分别是一个通解,和可以取任意实数。那么标准化后的特征向量为: ( 1 2 1 2 ) , ( − 1 2 1 2 ) \begin{pmatrix} \frac{1}{\sqrt{2}} \\ {\frac{1}{\sqrt{2}}} \\ \end{pmatrix}, \begin{pmatrix}- \frac{1}{\sqrt{2}} \\ {\frac{1}{\sqrt{2}}} \\ \end{pmatrix} (2 12 1),(−2 12 1) 4)矩阵P为: P = ( 1 2 1 2 − 1 2 1 2 ) P = \begin{pmatrix} \frac{1}{\sqrt{2}} ; \frac{1}{\sqrt{2}}\\ {-\frac{1}{\sqrt{2}}} ; \frac{1}{\sqrt{2}} \\ \end{pmatrix} P=(2 1−2 12 12 1) 5)最后我们用P的第一行乘以数据矩阵X,就得到了降维后的表示: Y = ( 1 2 1 2 ) ( − 1 − 1 0 2 0 − 2 0 0 1 1 ) = ( − 3 2 − 1 2 0 3 2 − 1 2 ) Y = \begin{pmatrix} \frac{1}{\sqrt{2}} ; {\frac{1}{\sqrt{2}}} \\ \end{pmatrix} \begin{pmatrix} -1 ; -1 ; 0 ; 2 ; 0 \\ -2 ; 0 ; 0 ; 1 ; 1 \\ \end{pmatrix} = \begin{pmatrix} -\frac{3}{\sqrt{2}} ; -{\frac{1}{\sqrt{2}}} ; 0 ; \frac{3}{\sqrt{2}} ; -\frac{1}{\sqrt{2}}\\ \end{pmatrix} Y=(2 12 1)(−1−2−10002101)=(−2 3−2 102 3−2 1) 结果如图1所示:
输入:数据集 X = ( x 1 . x 2 , x 3 , , … , x n ) X = (x_1.x_2,x_3,,…, x_n) \quad X=(x1.x2,x3,,…,xn),需要降到k维。 去平均值(即去中心化),即每一位特征减去各自的平均值。 2)计算协方差矩阵。通过SVD计算协方差矩阵的特征值与特征向量。对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。将数据转换到k个特征向量构建的新空间中,即Y=PX。在PCA降维中,我们需要找到样本协方差矩阵, X X T XX^T XXT的最大k个特征向量,然后用这最大的k个特征向量组成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵 X X T XX^T XXT,,当样本数多、样本特征数也多的时候,这个计算还是很大的。当我们用到SVD分解协方差矩阵的时候,SVD有两个好处: 1)有一些SVD的实现算法可以先不求出协方差矩阵 X X T XX^T XXT也能求出我们的右奇异矩阵V。也就是说,我们的PCA算法可以不用做特征分解而是通过SVD来完成,这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是特征值分解。 2)左奇异矩阵可以用于对行数的压缩;右奇异矩阵可以用于对列(即特征维度)的压缩。这就是我们用SVD分解协方差矩阵实现PCA可以得到两个方向的PCA降维(即行和列两个方向)。 4 PCA实例直接上代码了: ##Python实现PCA import numpy as np def pca(X,k):#k is the components you want #step 1: #mean of each feature n_samples, n_features = X.shape mean=np.array([np.mean(X[:,i]) for i in range(n_features)]) #normalization norm_X=X-mean #step 2:协方差矩阵 #scatter matrix scatter_matrix=np.dot(np.transpose(norm_X),norm_X) #step 3: 计算协方差矩阵的特征值与特征向量。 #Calculate the eigenvectors and eigenvalues eig_val, eig_vec = np.linalg.eig(scatter_matrix) eig_pairs = [(np.abs(eig_val[i]), eig_vec[:,i]) for i in range(n_features)]#拆分为列表,分别存储各自的特征值与特征向量 print(eig_pairs) #step 4: 特征值排序 # sort eig_vec based on eig_val from highest to lowest eig_pairs.sort(reverse=True)#设为True意味着反转,默认从小到大排序,直接在原序列修改 #step 4: 选择特征值最大的k个特征向量 # select the top k eig_vec feature=np.array([ele[1] for ele in eig_pairs[:k]])#ele[0]是特征值,ele[1]是特征向量 #将数据转换到k个特征向量构建的新空间中,即Y=PX #get new data data=np.dot(norm_X,np.transpose(feature)) return data X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) print(pca(X,1))该方法基于特征分解(也就是第一个方法),结果如下: 这是得到的特征值与特征向量:[(37.70674550364642, array([0.8549662 , 0.51868371])), (1.6265878296869243, array([-0.51868371, 0.8549662 ]))] PCA结果: [[-0.50917706] [-2.40151069] [-3.7751606 ] [ 1.20075534] [ 2.05572155] [ 3.42937146]]注意:sklearn中的PCA是通过svd_flip函数实现的,sklearn对奇异值分解结果进行了一个处理,与此不同。 |
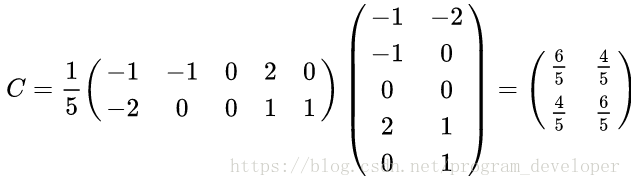 3)求协方差矩阵的特征值与特征向量。
3)求协方差矩阵的特征值与特征向量。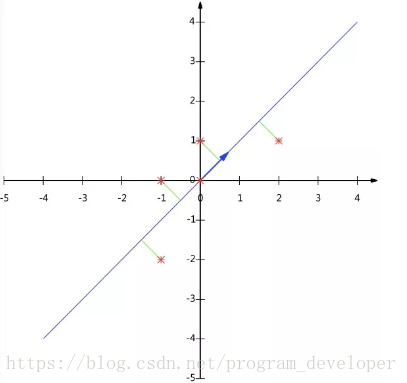 注意:如果我们通过特征值分解协方差矩阵,那么我们只能得到一个方向的PCA降维。这个方向就是对数据矩阵X从行(或列)方向上压缩降维。
注意:如果我们通过特征值分解协方差矩阵,那么我们只能得到一个方向的PCA降维。这个方向就是对数据矩阵X从行(或列)方向上压缩降维。【本文地址】