| 实例教程:样本量计算之RCT遇到连续变量 | 您所在的位置:网站首页 › 样本变量怎么求 › 实例教程:样本量计算之RCT遇到连续变量 |
实例教程:样本量计算之RCT遇到连续变量
|
本次实例教程带来样本量计算第二弹:对于结局指标是连续变量,平行设计的随机对照试验,样本量计算方法包教包会! 小咖:我就喜欢勤奋的你。那今天咱们来看看平行设计的随机对照试验,结局指标是连续变量的样本量计算方法吧。 上次说了,样本量计算时,需要知道几个重要的参数。对于结局指标是连续变量,平行设计的随机对照试验,计算样本量时需要知道 :1、研究设计类型;2、结局指标类型;3、结局指标的估计平均值;4、结局指标的离散程度;5、检验水准α;6、把握度1-β 小明:额,好复杂啊。你能不能举个例子呢? 小咖:某研究者拟开展一项平行设计的随机对照试验,探讨A药是否能降低血清胆固醇。估计安慰剂对照组血清总胆固醇的平均值为(215±30)mg/dl,干预组使用A药后可以降低15mg/dl。设α=0.05(双侧),β=0.10,请计算干预组和对照组所需样本量。 这个例子里面,我已经把需要知道的6个参数都列出来了。1、研究设计类型(随机对照试验);2、结局指标类型(连续变量——血清总胆固醇);3、结局指标的估计平均值(对照组215mg/dl、干预组200mg/dl);4、结局指标的离散程度(标准差30mg/dl);5、检验水准α=0.05;6、把握度1-β=0.9。 小明:研究设计类型、结局指标类型、检验水准、把握度这几个指标我都明白。可是我还没有开展研究,怎么能知道结局指标的估计平均值和离散程度呢? 小咖:这个......主要是依靠查阅文献、预试验、专家经验来定的,给一个大致的范围即可。明确了这几个参数之后,咱们就可以使用PASS 11 软件估算样本量了。 1、选择Means→Two Independent Means→Test (Inequality)→Test for Two Means(Two-Sample T-Test)[Differences]
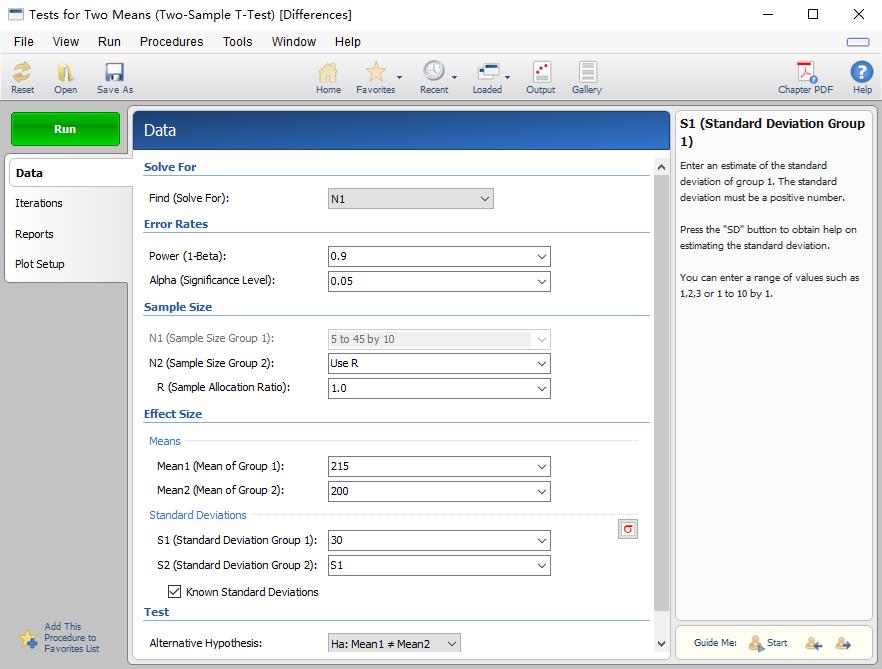
2、Find (Solve for)中选择N1,Power (1-Beta)中选择0.9,Alpha (Significance Level)中选择0.05;N2 (Sample Size Group 2)中选择Use R,R (Sample Allocation Ratio)中选择1.0[R为N2组与N1组的样本量之比。如果预设两组样本量相等,则选择1.0;如果预设两组样本量之比为1:2,则选择2.0;依次类推];Mean1 (Mean of Group 1)中填入215,Mean2 (Mean of Group 2)中填入200;S1 (Standard Deviation Group 1)中填入30,S2 (Standard Deviation Group 2)中选择S1;点击Know Standard Deviations。其它选择为默认选项后,点击RUN。 展开全文
3、结果解读
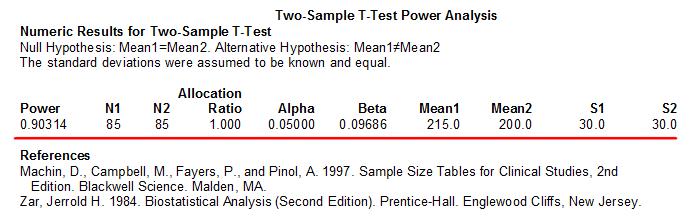
PASS软件给出了样本量计算的结果、参考文献、报告中的名词定义和总结性描述。在样本量计算结果中我们需要关注以下2列: 1)N1:干预组样本量。本研究的干预组需要85例研究对象。 2)N1:对照组样本量。本研究的对照组需要85例研究对象。 小明:太好了,我又学会了一种样本量估算方法。我试着写一下这个结果,你看看对不对啊? 本研究为平行随机对照研究。干预组为使用A药组,对照组为安慰剂对照组,血清总胆固醇为主要观察的结局指标。根据既往文献报道,估计对照组血清总胆固醇的平均值为215mg/dl,干预组使用A药后可以降低15mg/dl,血清总胆固醇的标准差约为30mg/dl。设α=0.05(双侧),β=0.10。利用PASS 11软件计算得到干预组和对照组的样本量N1=N2=85例。假定研究对象的失访率为10%,则需样本量N1=N2=85÷0.9=94例。实际研究中,两组各纳入100例。 小咖:给你满分^_^ (微信公众号:医咖会。用生动有趣的形式传递医学新进展,重点探讨临床研究方法。)返回搜狐,查看更多 责任编辑: |
【本文地址】