| 在树莓派上轻松实现深度学习目标检测 | 您所在的位置:网站首页 › 树莓派实现目标跟踪 › 在树莓派上轻松实现深度学习目标检测 |
在树莓派上轻松实现深度学习目标检测
|
这个现实世界造成了很多挑战,比如数据有限、只有微型的计算机硬件(像手机、树莓派)所造成的无法运行复杂深度学习模型等。这篇文章演示了如何使用树莓派来进行目标检测。就像路上行驶的汽车,冰箱里的橘子,文件上的签名和太空中的特斯拉。 免责声明:我正在建设 nanonets.com 来帮助使用很少的数据和没有计算机硬件的情况下构建机器学习模型。 如果你很迫切,请直接下拉到这篇文章的底部进入Github的仓库。
树莓派是一款灵活的计算机硬件,它以1500万台的销量已经吸引了一代消费者的心,并且黑客们也在树莓派上构建了很多很酷的项目。考虑到深度学习和树莓派相机的的流行,我们认为如果能在树莓派上使用深度学习来检测任意的物体那就非常棒了。 现在你可以检测到你的自拍照里的照片炸弹,有人进入到Harambe的笼子里,哪里有辣椒酱或者亚马逊的快递员进入到你的房子里。
什么是目标检测? 2000万年的进化使得人类的视觉系统有了相当高的进化。人脑有30%的神经元负责处理视觉信息(相对比只有8%处理触觉和3%处理听觉)。与机器相比,人类有两个主要的优势。一是立体视觉,二是训练数据集的供应几乎是无限的(一个五岁的婴儿可以大约在30fps的采样间隔获得2.7B的图像数据)。
为了模仿人类水平的表现,科学家将视觉感知任务分解为四个不同的类别。1.分类,为图像指定一个标签。2.定位,对特定的标签指定一个边框。3.物体检测,在图像中绘制多个边框。4.图像分割,得到物体在图像中的精确位置区域。 物体检测对于很多应用已经足够好(图像分割是更精确的结果,它受到了创建训练数据复杂性的影响。相比于画边框它通常花费人类标注者12倍的时间去分割图像。)此外,在检测物体之后,可以将物体在边框中单独分割出来。 使用物体检测:目标检测具有重要的现实意义,已经在各行各业得到了广泛应用。下面列举了一些例子:
物体检测可以用于解决各种各样的问题。这些是一个概括的分类:1.物体是不是出现在我的图像中?比如在我的房子有一个入侵者。2.在图像中的一个物体在哪个位置?比如一个汽车试图在世界各地导航时,知道物体的位置就很重要。3.图像中有多少个物体?物体检测是计算物体数目最有效的方法之一。比如仓库的货架上有多少个盒子。4.图像中有哪些不同类型的物体?比如动物园的哪些区域有哪些动物?5.物体的尺寸有多大?特别是使用静态的相机,很容易计算出物体的大小。比如芒果的大小是多少。6.物体之间是如何相互作用的?比如在足球场上的队形是如何影响比赛结果的?7.物体在不同时间的位置(跟踪一个物体)?比如跟踪一个像火车一样的物体并且计算它的速度。 在20行代码内完成物体检测
有多种用于物体检测的模型或结构。每一个都在速度、尺寸和精确度之间权衡。我们选择了最流行的一个:YOLO(You only look once),并且展示它如何以20行代码(忽略注释)进行工作。 注意:这是伪代码,不是一个可直接工作的实例。它有一个非常标准的CNN构成的黑箱,如下图所示: 你可以阅读(YOLO)全文:https://pjreddie.com/media/files/papers/yolo_1.pdf
YOLO中使用卷积神经网络的体系结构代码小于20行,如下: #this is an Image of size 140x140. We will assume it to be black and white (ie only one channel, it would have been 140x140x3 for rgb) image = readImage() #We will break the Image into 7 coloumns and 7 rows and process each of the 49 different parts independently NoOfCells = 7 #we will try and predict if an image is a dog, cat, cow or wolf. Therfore the number of classes is 4 NoOfClasses = 4 threshold = 0.7 #step will be the size of step to take when moving across the image. Since the image has 7 cells step will be 140/7 = 20 step = height(image)/NoOfCells #stores the class for each of the 49 cells, each cell will have 4 values which correspond to the probability of a cell being 1 of the 4 classes #prediction_class_array[i,j] is a vector of size 4 which would look like [0.5 #cat, 0.3 #dog, 0.1 #wolf, 0.2 #cow] prediction_class_array = new_array(size(NoOfCells,NoOfCells,NoOfClasses)) #stores 2 bounding box suggestions for each of the 49 cells, each cell will have 2 bounding boxes, with each bounding box having x, y, w ,h and c predictions. (x,y) are the coordinates of the center of the box, (w,h) are it's height and width and c is it's confidence predictions_bounding_box_array = new_array(size(NoOfCells,NoOfCells,NoOfCells,NoOfCells)) #it's a blank array in which we will add the final list of predictions final_predictions = [] #minimum confidence level we require to make a prediction threshold = 0.7 for (i |




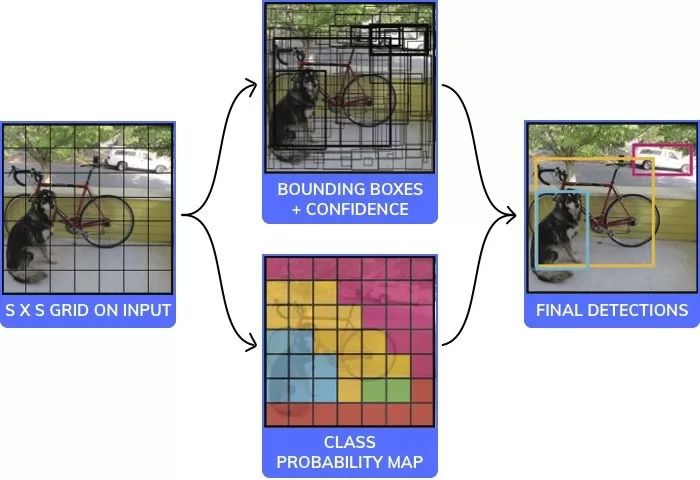 YOLO算法的可视化
YOLO算法的可视化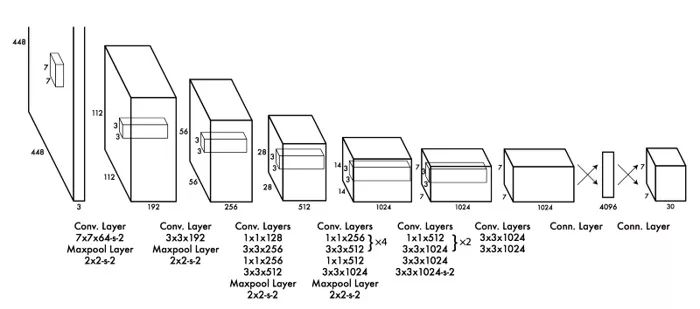
【本文地址】