| 第6章 Navicat操作MySQL数据库 | 您所在的位置:网站首页 › 查询数据库内容的关键字 › 第6章 Navicat操作MySQL数据库 |
第6章 Navicat操作MySQL数据库
|
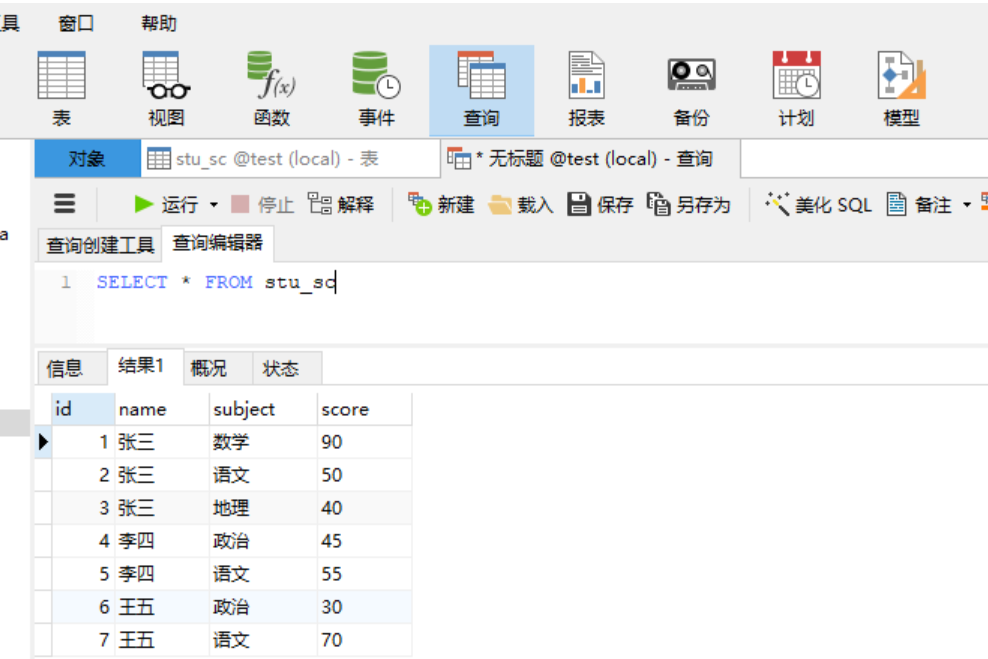
1. 查询 1.1 SELECT语句: MySQL 中使用 SELECT 语句来查询数据。 数据库中根据需求,使用不同的查询方式来获取不同的数据,是使用频率最高、最重要的操作。 1.2 查询---通配符 1.2.1 通配符---(“ * ”)用法 语法: SELECT * FROM ;
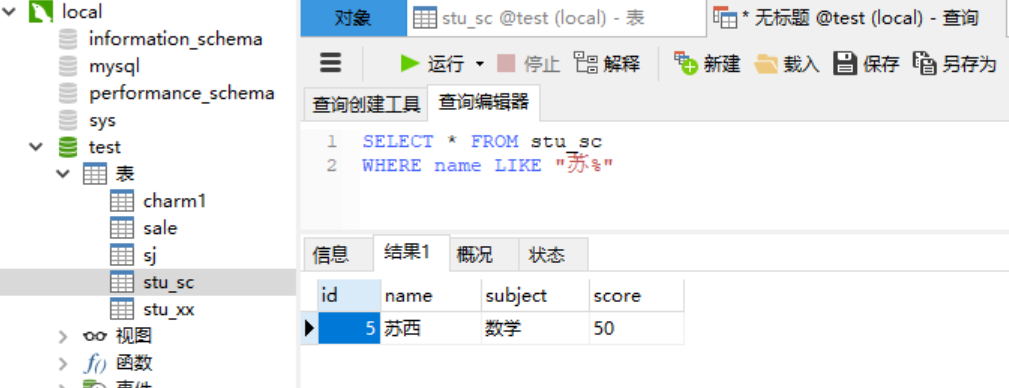
1.2.2 通配符---(“ % ”)用法 匹配任意长度的字符串,包括空字符串。例如,字符串“ c% ”匹配以字符 c 开始,任意长度的字符串,如“ ct ”,“ cut ”,“ current ”等;字符串“ c%g ”表示以字符 c 开始,以 g 结尾的字符串;字符串“ %y% ”表示包含字符“ y ”的字符串,无论“ y ”在字符串的什么位置。
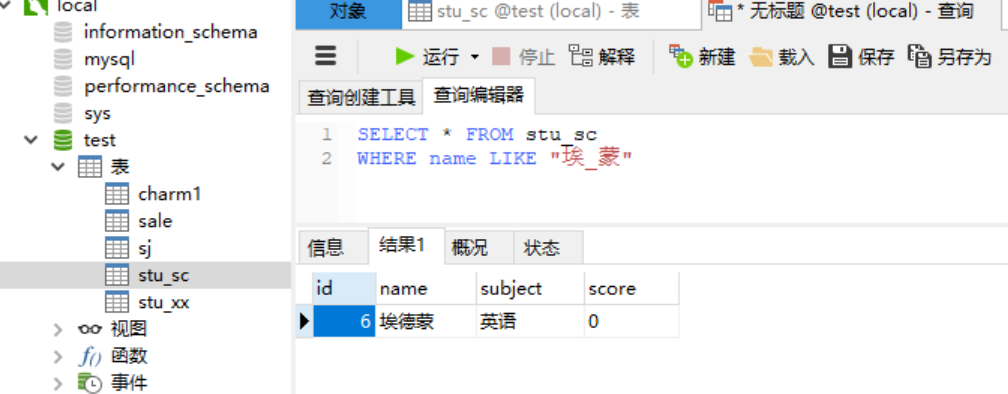
1.2.3 通配符---(“ _ ”)用法 下划线通配符只匹配单个字符,若要匹配多个字符,需要使用多个下划线通配符。例如,字符串“ cu_ ”匹配以字符串“ cu ”开始,长度为3的字符,如“ cut ”,“ cup ”;字符串“ c__l”匹配在“ c ”和“ l ”之间包含两个字符的字符串,如“ cool ”。需要注意的是,连续的“_”之间不能有空格,例如“M_ _QL”只能匹配“My SQL”,不能匹配“MySQL”。 注意:若要查询的字段值本来就含有“ % ”或者“ _ ”,则要用“ \ ”进行转义,如要查询本身含有“ % ”的字符串,命令应改为 “ %\%%”。
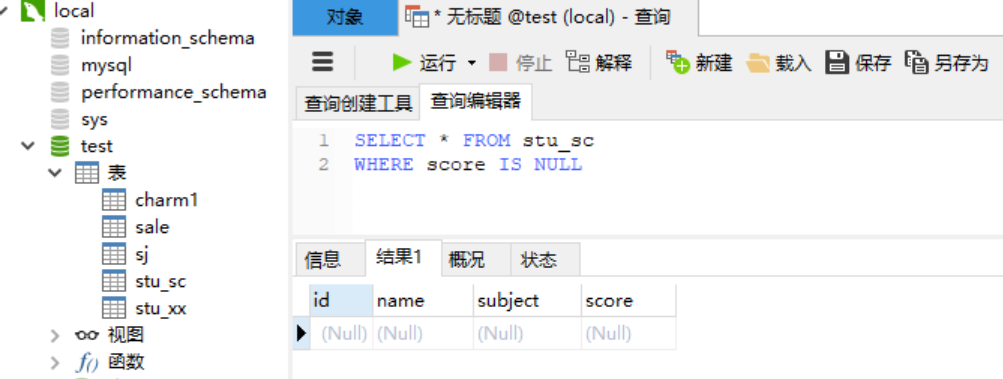
1.3 查询---空值 在数据表中有些值可能为空值(NULL),空值不同于0。需要使用 IS NULL 来判断字段的值是否为空值。IS NOT NULL 关键字用来查询字段不为空值的记录。 语法: SELECT [字段名1,字段名2,…] FROM WHERE [字段名] IS [ NOT ] NULL
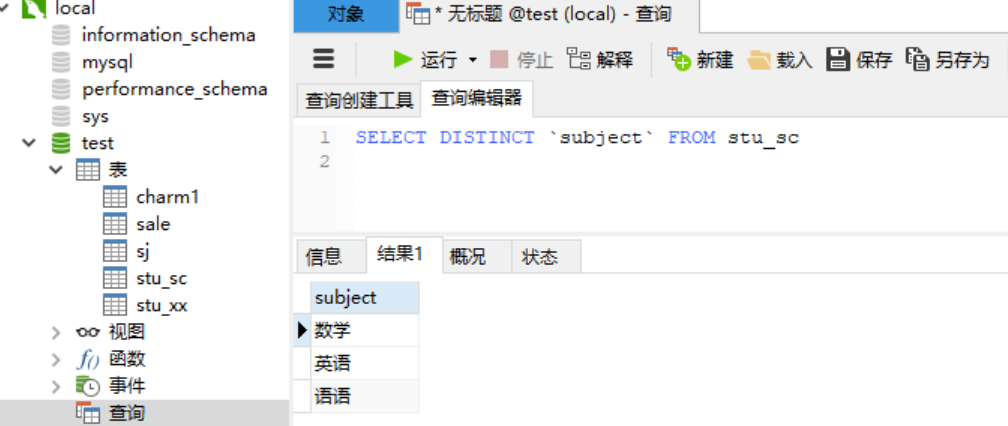
1.4 查询---关键字 1.4.1 关键字---distinct用法 很多表中某些字段的数据存在重复的值,可以使用DISTINCT关键字来过滤重复的值,只保留一个值。DISTINCT 关键字还可作用于多个字段,则只有多个字段的值都完全相同时才会被认作是重复记录。 语法: SELECT DISTINCT [字段名] FROM
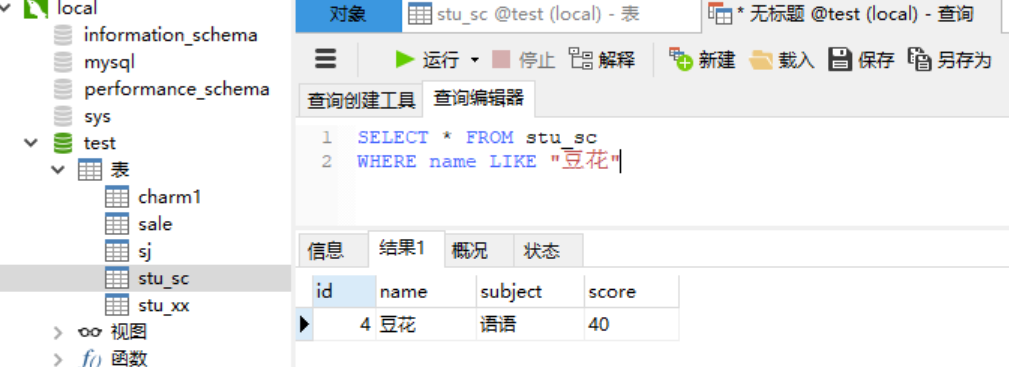
1.4.2 关键字---like用法 通常与通配符 “%” 与 “_” 搭配使用,也可以单独使用。 语法: SELECT [字段名1,字段名2,…] FROM WHERE [字段名] [ NOT ] LIKE ‘匹配字符串’
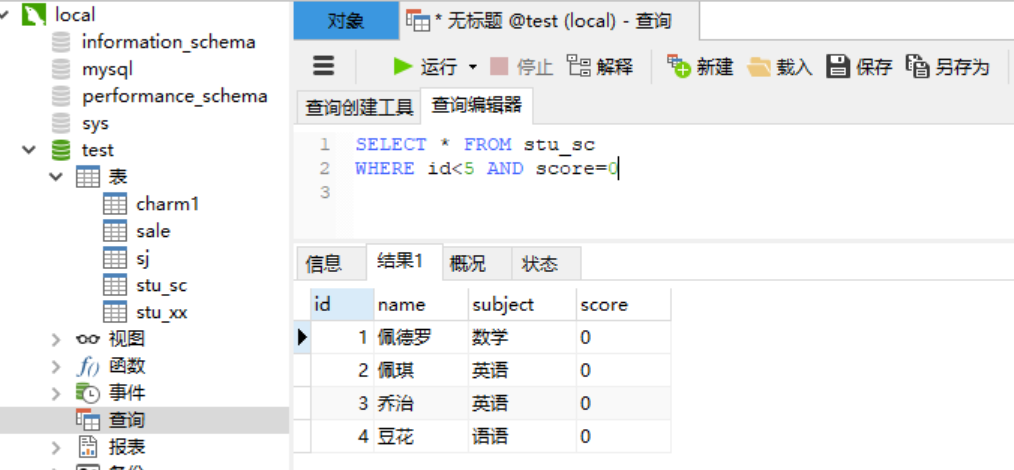
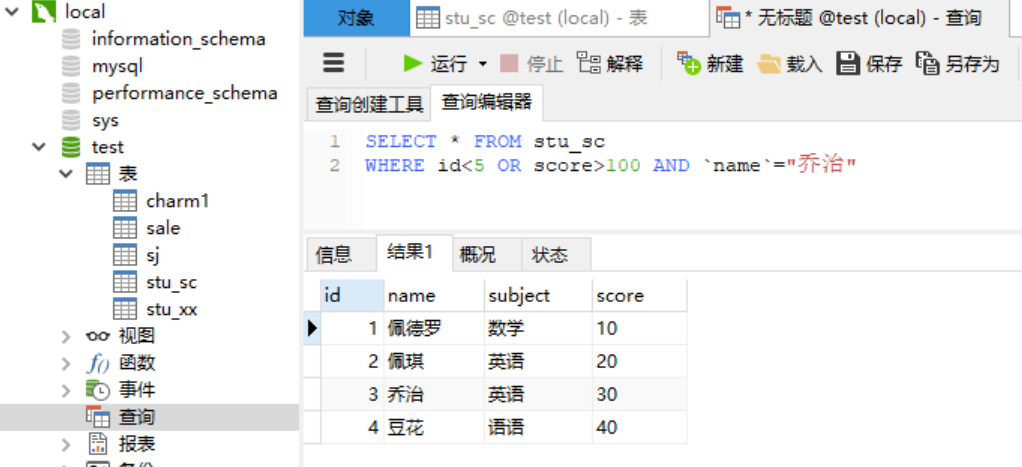
1.4.3 关键字---and用法 在使用SELECT语句查询数据时,优势为了使查询结果更加精确,可以使用多个查询条件,如使用 AND 关键字可以连接两个或多个查询条件。 语法: SELECT [字段名1,字段名2,…] FROM WHERE [条件表达式1] AND [条件表达式2] ...
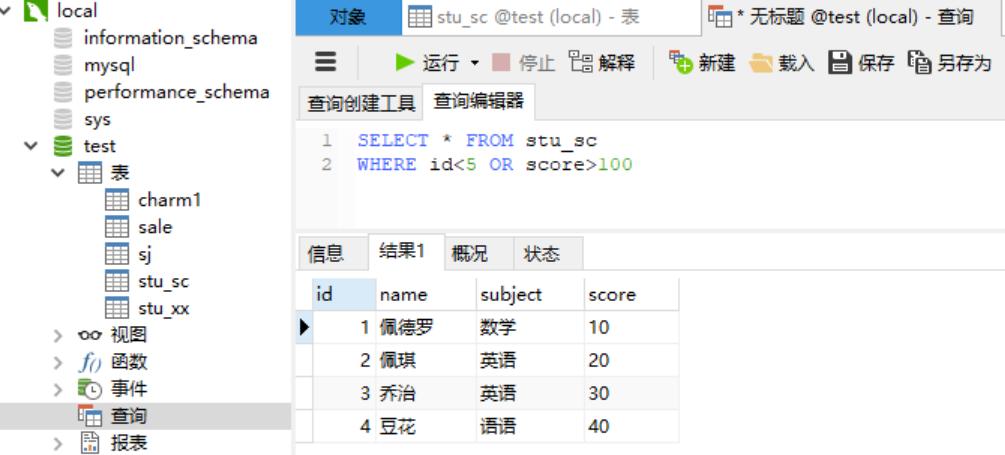
1.4.4 关键字---or用法 与 AND 关键字不同,OR 关键字只要满足任意一个条件就会被查询出来。 语法: SELECT [字段名1,字段名2,…] FROM WHERE [条件表达式1] OR [条件表达式2] ...
1.4.5 关键字---and与or配合用法 OR 和 AND 一起使用的时候,AND 的优先级高于 OR,因此二者一起使用时,会先运算 AND 两边的表达式,再运算 OR 两边的表达式。
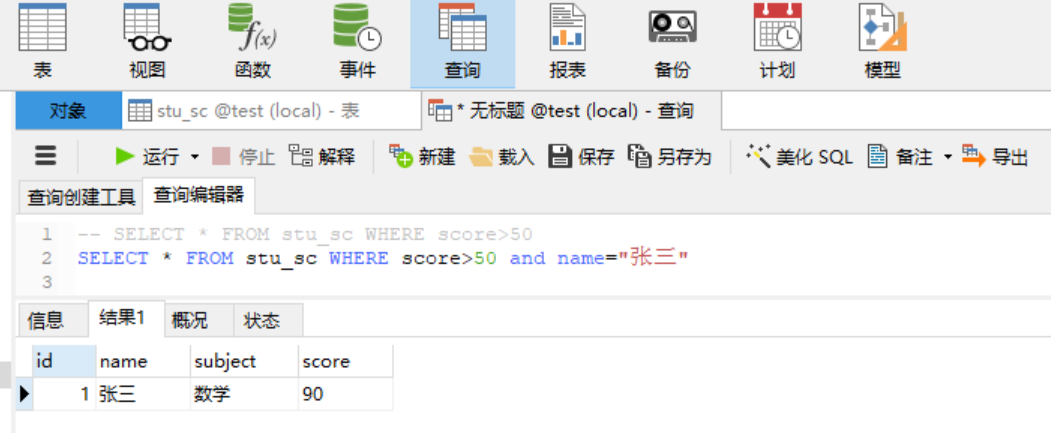
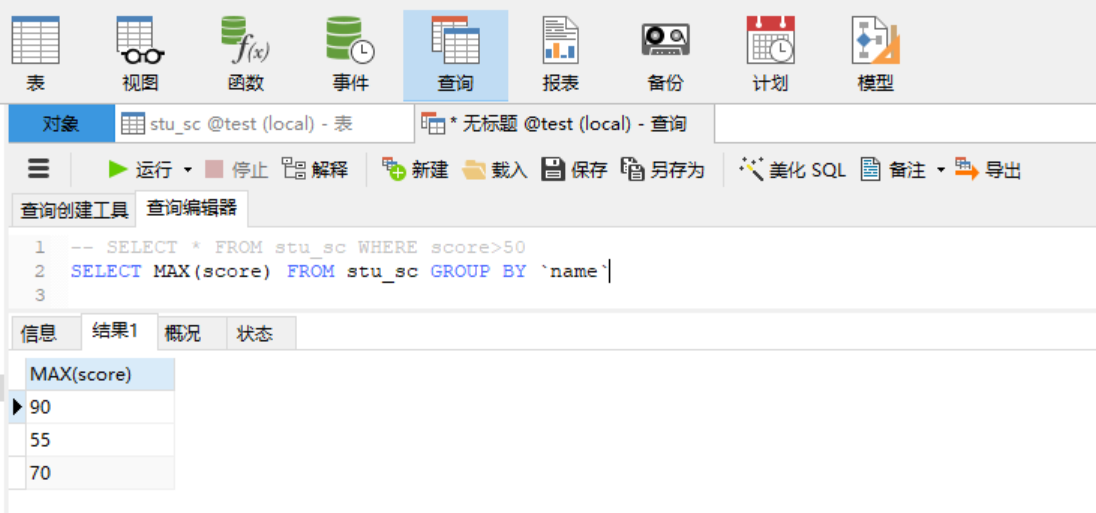
2. 子查询 通常我们在查询的SQL中嵌套查询,称为子查询。子查询通常会使复杂的查询变得简单,但是相关的子查询要对基础表的每一条数据都进行子查询的动作,所以当表单中数据过大时,一定要慎重选择,常用的子查询语句有五种: 条件查询(where子句):按照“条件表达式”指定的条件进行查询。 分组查询(group by子句):按照“属性名”指定的字段进行分组。group by子句通常和count()、sum()等聚合函数一起使用。 筛选查询(having子句):有group by才能having子句,只有满足“条件表达式”中指定的条件的才能够输出。 排序查询(order by子句):按照“属性名”指定的字段进行排序。排序方式由“asc”和“desc”两个参数指出,默认是按照“asc”来排序,即升序。 限制查询(limit):限制结果集。2.1 条件查询(where子句) where子句常用与运算符配合使用,常用于配合的运算符: 类型 运算符 说明 比较运算符 =,!= 小于,小于等于,等于,大于,大于等于,不等于 逻辑运算符 not 或 !,or 或 |,and 或 & 非,或,与 需求:查询表格中分数大于50,且名字为“张三”的数据! 2.2 分组查询(group by子句) “group by”就是,根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。group by语句中,select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中。 select 类别, sum(数量) as 数量之和 from A group by 类别MySQL常用的五种聚合函数: max():求最大值。 min():求最小值。 sum():求和。 avg():求平均值。 count():统计记录的条数。需求:选出表中各成员中成绩最高的数据!
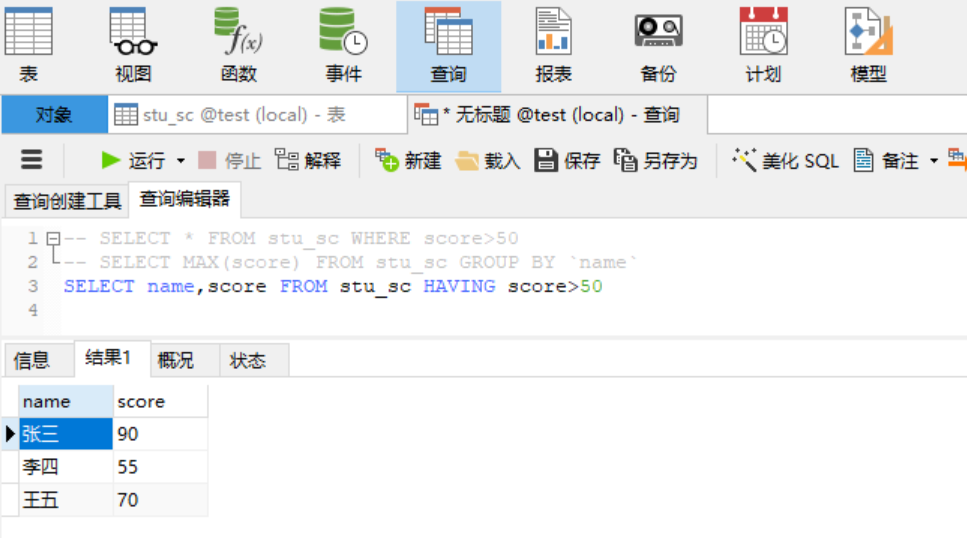
2.3 筛选查询(having子句) having子句可以让我们筛选“成组”后的各种数据,主要是针对“组"里面条件进行筛选。where子句在聚合前先筛选记录,也就是说作用在group by和having子句前。而 having子句在聚合后对组记录进行筛选。 需求:筛选出name和score这组数据中,分数大于50的数据!
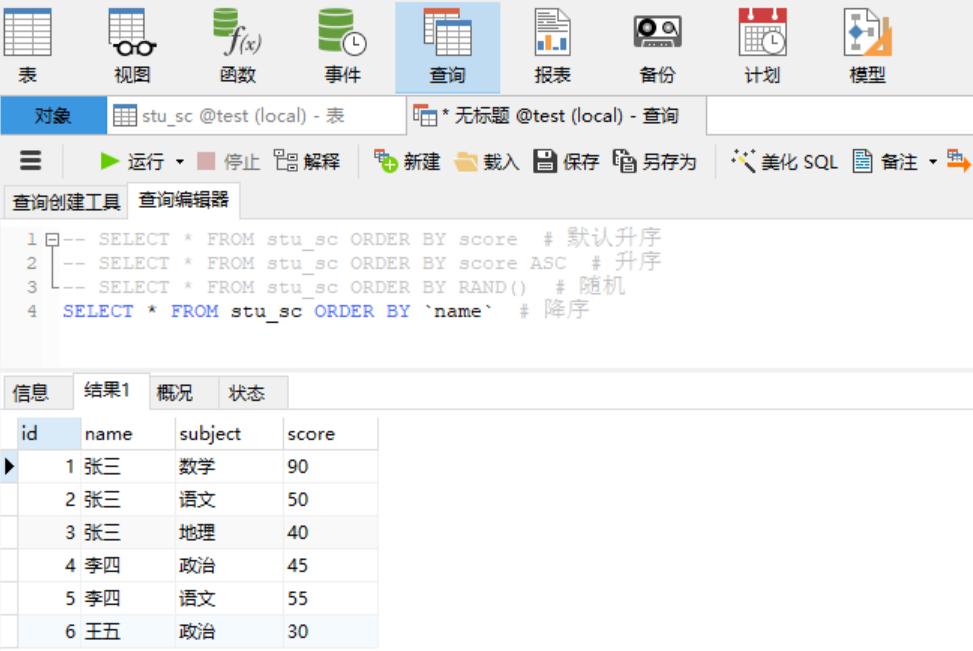
where和having的区别: 作用的对象不同。WHERE 子句作用于表和视图,HAVING 子句作用于组。 WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算), 而 HAVING 在分组和聚集之后选取分组的行。因此,WHERE 子句不能包含聚集函数; 因为试图用聚集函数判断那些行输入给聚集运算是没有意义的。相反,HAVING 子句总是包含聚集函数。(严格说来,你可以写不使用聚集的 HAVING 子句, 但这样做只是白费劲。同样的条件可以更有效地用于 WHERE 阶段。)在上面的例子中,我们可以在 WHERE 里应用数量字段来限制,因为它不需要聚集。 这样比在 HAVING 里增加限制更加高效,因为我们避免了为那些未通过 WHERE 检查的行进行分组和聚集计算。 综上所述: having一般跟在group by之后,执行记录组选择的一部分来工作的。where则是执行所有数据来工作的。 再者having可以用聚合函数,如having sum(qty)>1000。 2.4 排序查询(order by子句) order by # 默认升序排列 order by desc # 降序排列 order by asc # 升序排列 order by rand() # 随机排列需求:将数据表中的数据依据score,进行降序排列!
列中的元素不是为数字也可以的。
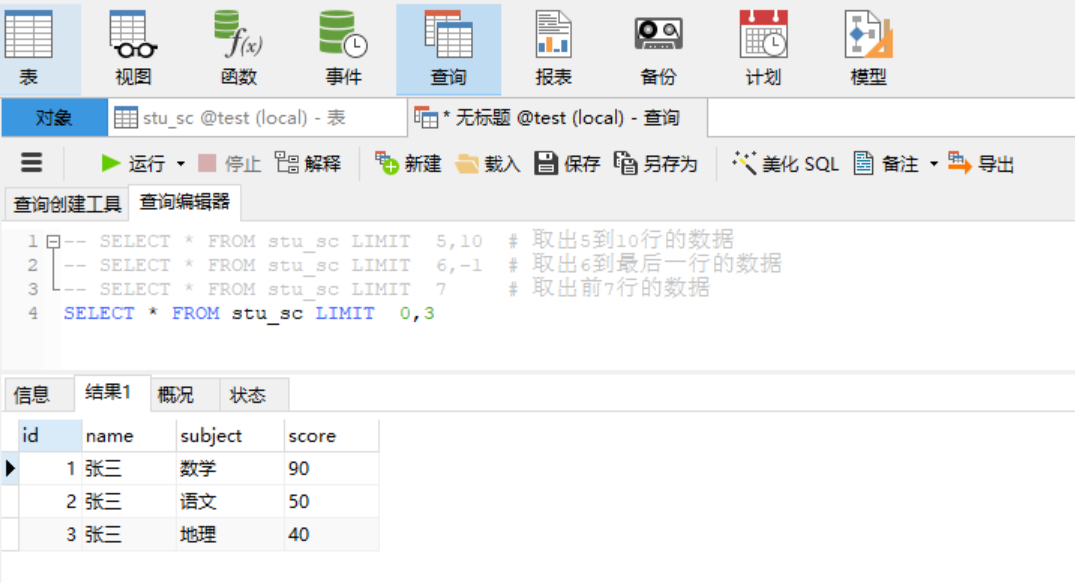
2.5 限制查询(limit子句) 在查询语句中,我们经常想要只返回前面几行或中间几行的数据,可使用【 limit [offset,] N 】,offset偏移量,可选,默认为0,【limit 0,N】取出0至N数据。
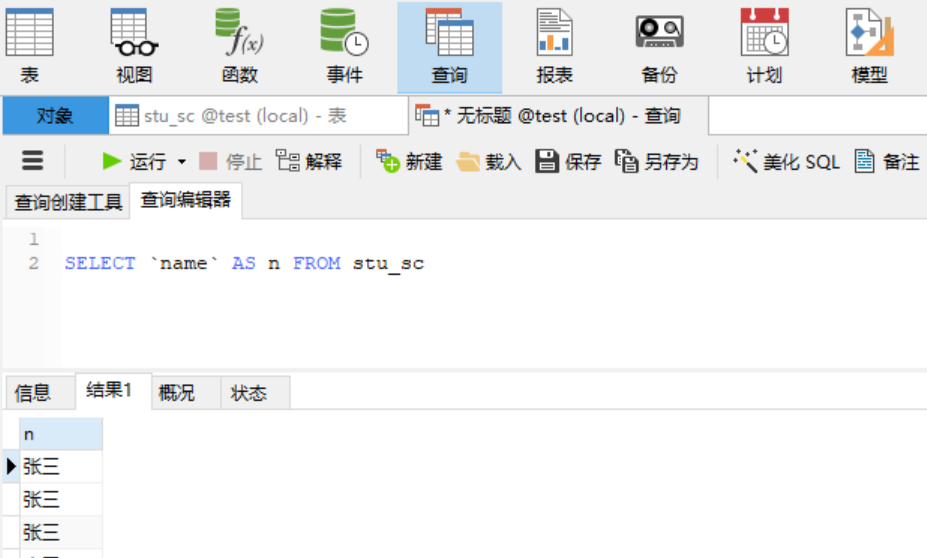
2.6 子查询关键字 2.6.1 关键字---as的用法 1)重命名表/列名:as可以理解为用作、当成,一般是重命名“列名”或者“表名”,主要是为了查询方便。 需求:将表中“name”列名,重命名为n。
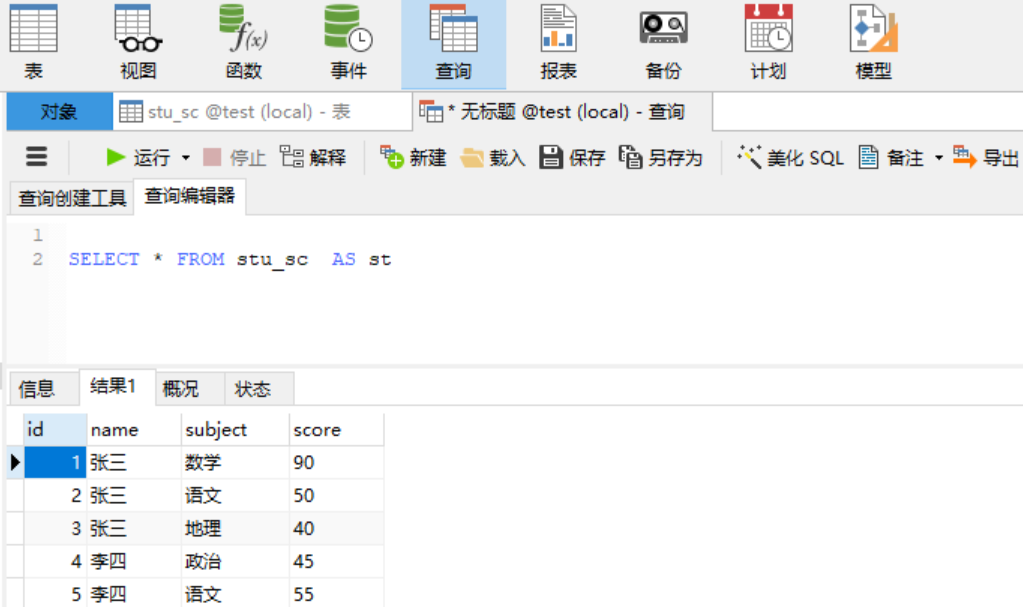
需求:查找表中数据,并将数据表重命名为st。
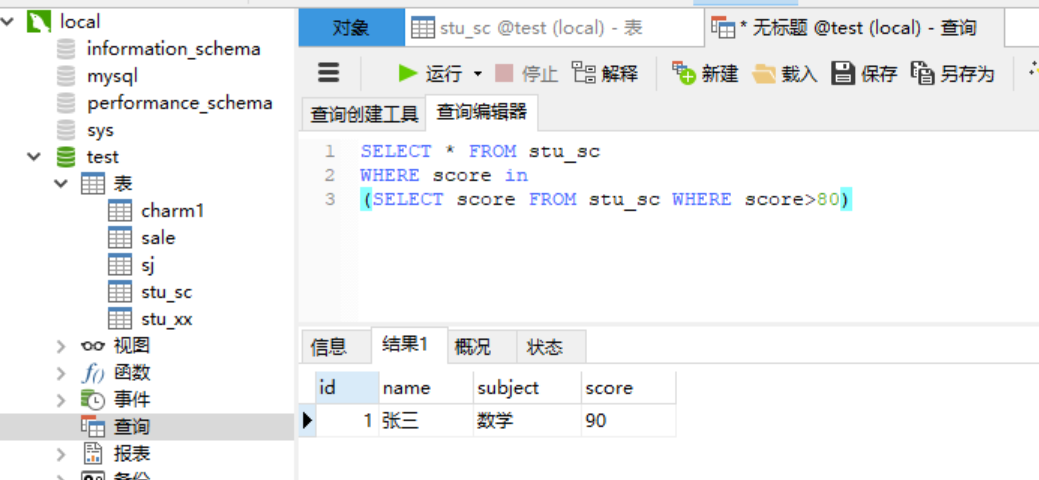
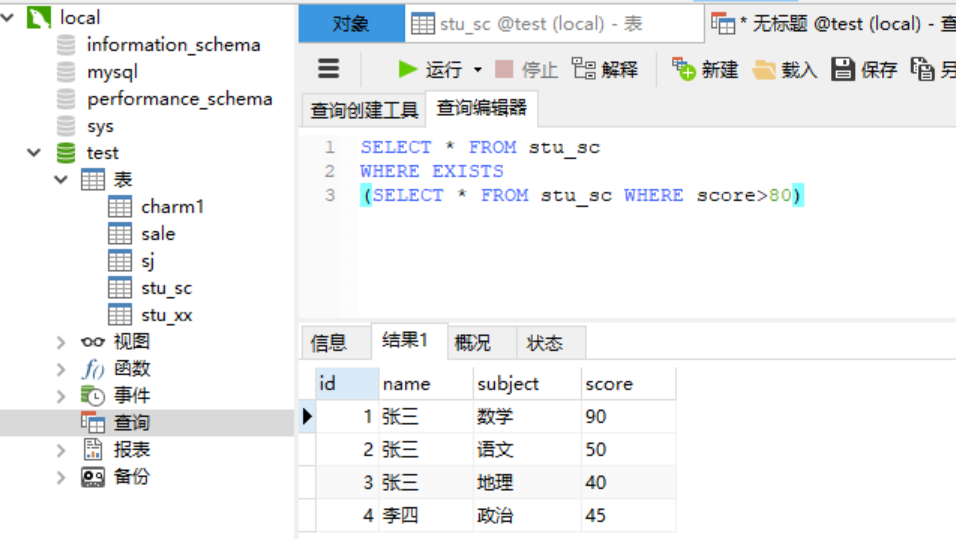
2)关键字as作为连接语句的操作符 create table charm1 as select * from charm2解释:上面的语句是先获取charm1表格中所有数据,之后再创建一张charm1表,结构和charm2表相同,记录为后面语句的查询结果。 2.6.2 关键字---in用法 使用in关键字可以将原表中特定列的值与子查询返回的结果集中的值进行比较如果某行的特定列的值存在,则在select语句的查询结果中就包含这一行。 例:查询成绩大于80的学生的所有信息,先在子查询中查出成绩大于80的结果集,然后将原成绩表中的成绩与结果集进行比较,如果存在,就输出这条学生的记录。 2.6.3 关键字---exists用法 exists: 是否存在的意思, exists子查询就是用来判断某些条件是否满足(跨表),exists是接在where之后exists返回的结果只有0和1。 需求:如果存在成绩大于90的人则列出“整个表”的记录。
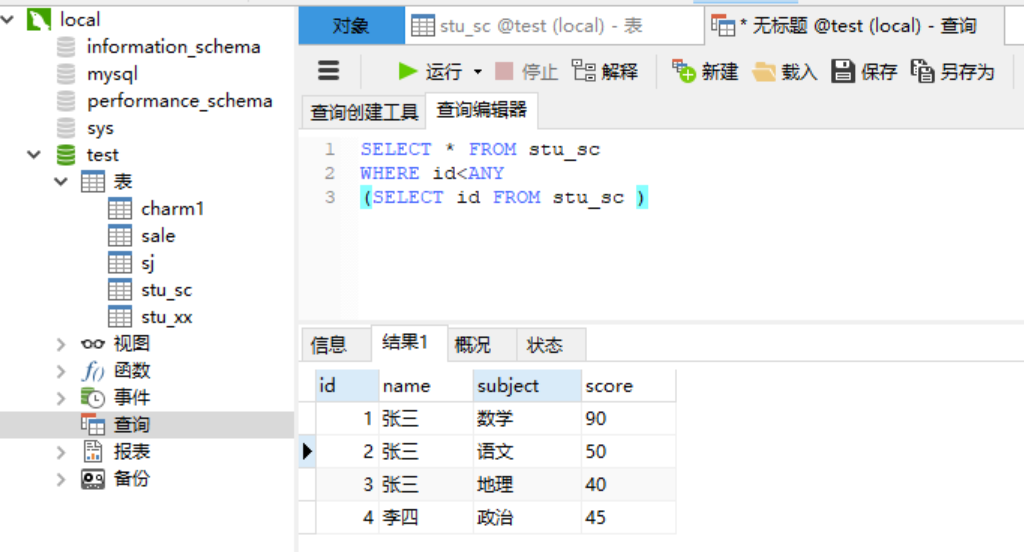
2.6.4 关键字---any用法 any关键字表示满足其中的任意一个条件,使用any关键字时,只要满足内层查询语句结果的的任意一个,就可以通过该条件来执行外层查询语句。
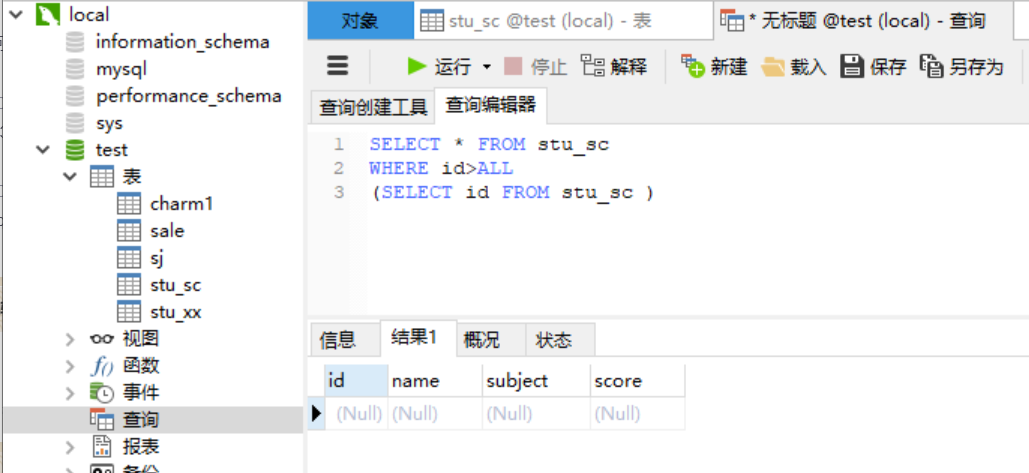
2.6.5 关键字---all用法 all和any刚好是相反的,all关键字表示满足所有结果,使用all关键字,要满足内层查询语句的所有结果,才可以通过该条件来执行外层查询语句。
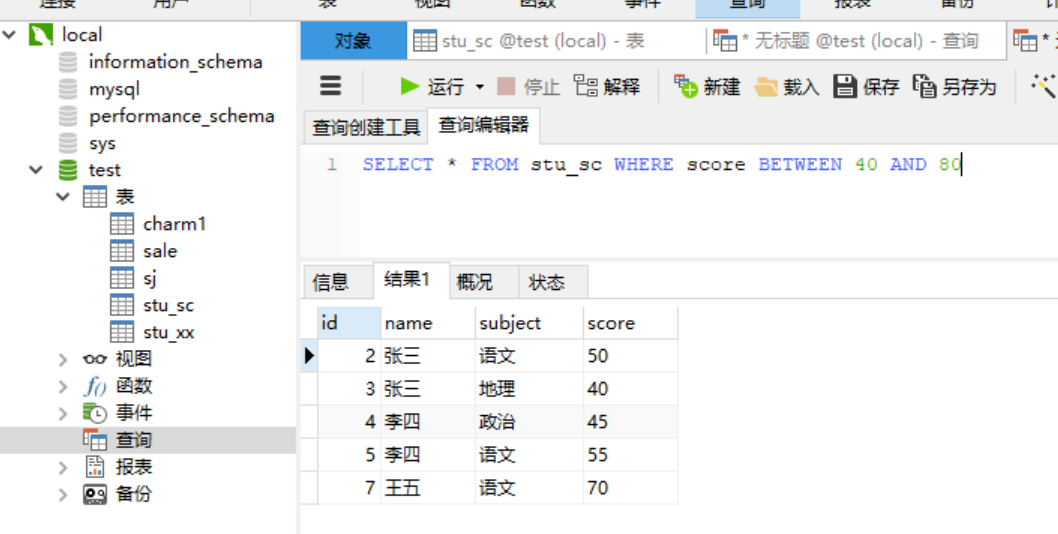
2.6.6 关键字---between and 用法 between关键字是一个逻辑操作符用来筛选指定属性或表达式某一范围内或范围外的数据。between常用在where关键字后与select或update或delete共同使用。 between的使用语法: expr [NOT] BETWEEN begin_expr AND end_expr 在整个表达式中,expr表示的是一个单一的属性或者是一个计算的表达式,整个表达式中的三个参数 expr、begin_expr、end_expr 必须是同一种数据类型。 between筛选的是 expr >= begin_expr并且 expr end_expr 的数据,如果不存在则返回的是0; 如果 expr 返回的是 NULL,则between 也返回的是null (暂未验证)。需求:查询stu_sc表中,分数在40-80分之间的数据!
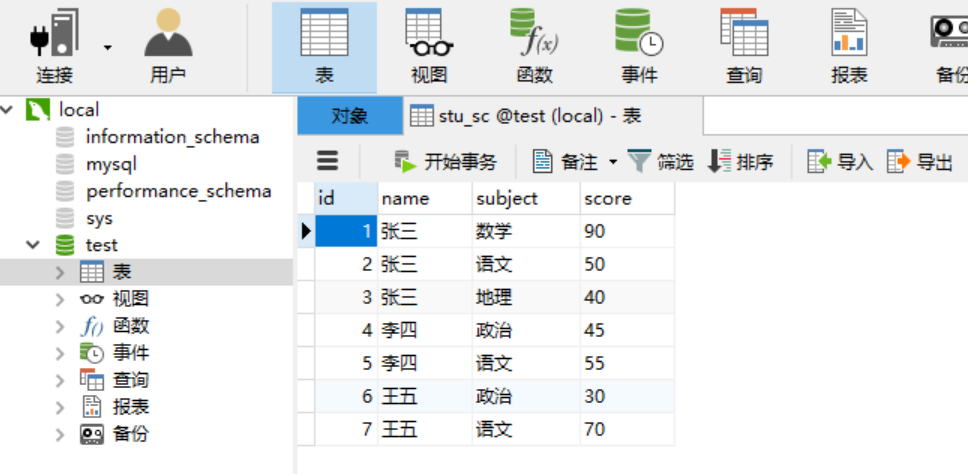
2.7 子查询组合 2.7.1 组合:where + group by + having + 函数。 需求:查询出两门以上不及格者的平均成绩(注意:是所有科目含及格科目的平均成绩) 第一步:打开数据表。
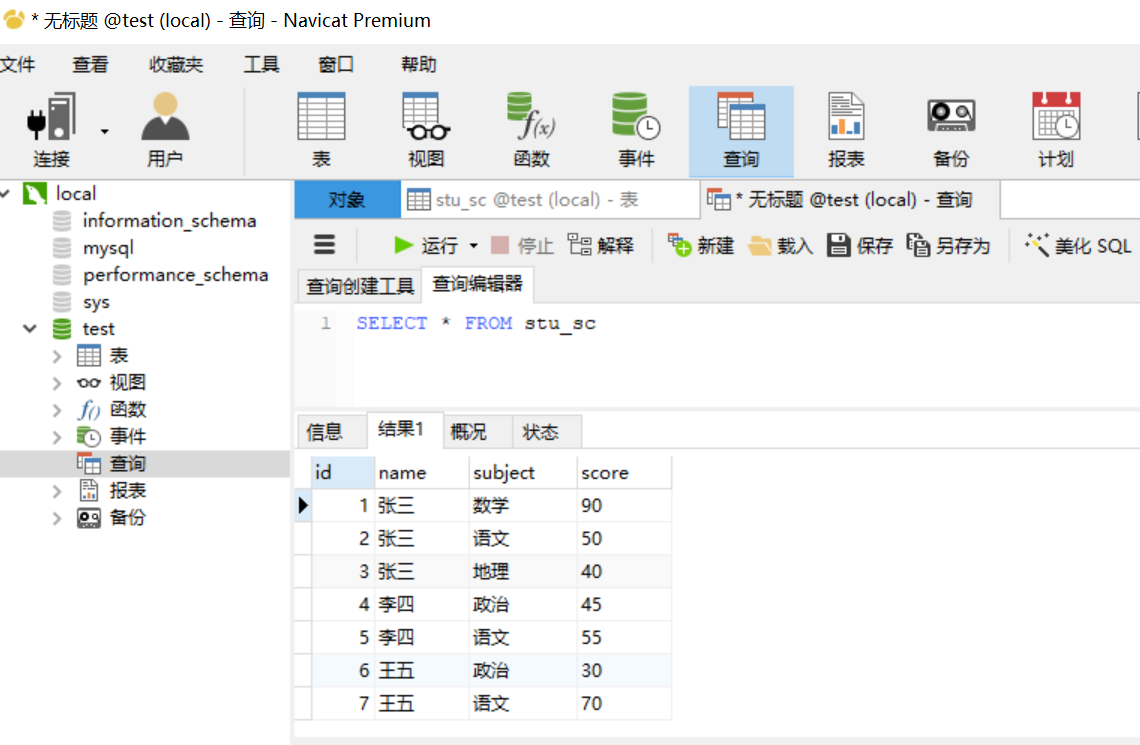
第二步:打开查询,新建查询,输入查询语句,查询出表中所有数据。
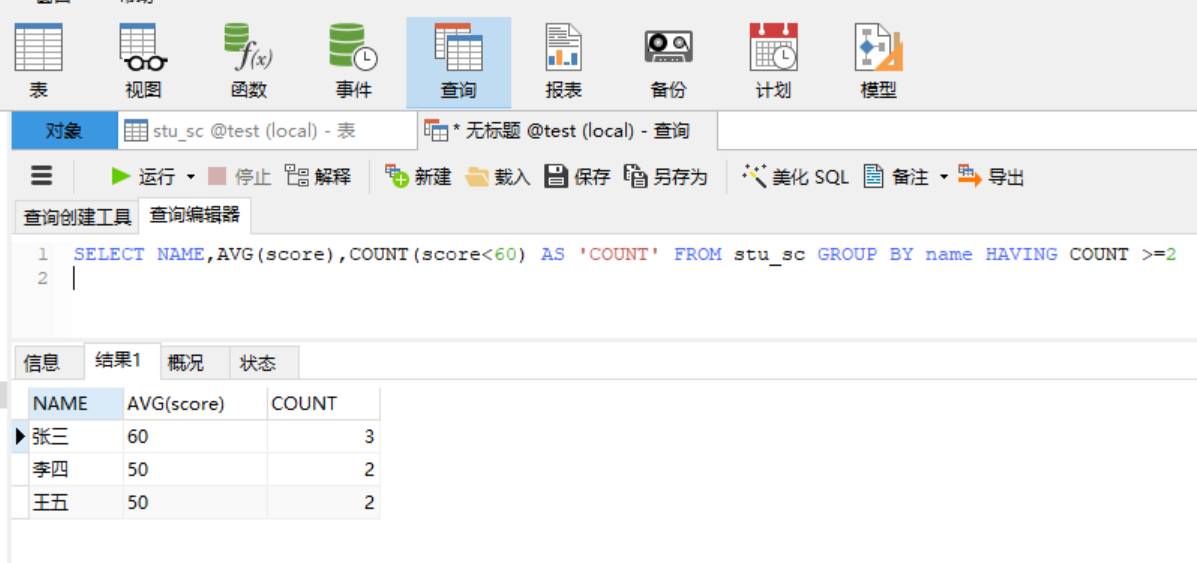
第三步:试试用count()函数,count(a),无论a是什么,都只是数一行;count时,每遇到一行,就数一个a,跟条件无关!(数据多了王五的)!
第四步:试试用sum()函数,用sum(score |

【本文地址】