| 使用Pytorch框架自己制作做数据集进行图像分类(一) | 您所在的位置:网站首页 › 构建卡通图片怎么做 › 使用Pytorch框架自己制作做数据集进行图像分类(一) |
使用Pytorch框架自己制作做数据集进行图像分类(一)
|
第一章:Pytorch制作自己的数据集实现图像分类
第一章: Pytorch框架制作自己的数据集实现图像分类 第二章: Pytorch框架构建残差神经网络(ResNet) 第三章: Pytorch框架构建DenseNet神经网络 提示:本文代码,含有部分测试性输出语句,更改数据文件夹路径后可以直接跑通,文章末尾附全部代码 文章目录 第一章:Pytorch制作自己的数据集实现图像分类前言一、上网搜取相关照片作为数据二、定义自己的数据类并读入图片数据1.引入相关库2.继承Dataset实现Mydataset子类3.使用glob方法获取文件夹中所有图片路径 三、为图片制作标签,并划分训练集与测试集1.利用自定义类Mydataset创建对象weather_dataset2.为每张图片制作相应的标签3.完善Mydataset类,将图片数据转换成Tensor,并展示部分图片与标签对应关系4.划分数据集和测试集 总结本文代码 前言网上有很多直接利用已有数据集(如MNIST, CIFAR-10等),直接进行机器学习,图像分类的教程。但如何自己制作数据集,为图像制作相应标签等的教程较少。故写本文,分享一下自己利用Pytorch框架制作数据集的方法技巧。 开发环境: Pycharm + Python 3.7.9 torch 1.10.2+cu102 torchvision 0.11.3+cu102 提示:以下是本篇文章正文内容 一、上网搜取相关照片作为数据
代码如下: import glob import torch from torch.utils import data from PIL import Image import numpy as np from torchvision import transforms import matplotlib.pyplot as plt 2.继承Dataset实现Mydataset子类代码如下: #通过创建data.Dataset子类Mydataset来创建输入 class Mydataset(data.Dataset): # 类初始化 def __init__(self, root): self.imgs_path = root # 进行切片 def __getitem__(self, index): img_path = self.imgs_path[index] return img_path # 返回长度 def __len__(self): return len(self.imgs_path)init() 初始化方法,传入数据文件夹路径。 getitem() 切片方法,根据索引下标,获得相应的图片。 len() 计算长度方法,返回整个数据文件夹下所有文件的个数。 3.使用glob方法获取文件夹中所有图片路径代码如下: #使用glob方法来获取数据图片的所有路径 all_imgs_path = glob.glob(r'F:\weather\*\*.jpg')#数据文件夹路径,根据实际情况更改! #循环遍历输出列表中的每个元素,显示出每个图片的路径 for var in all_imgs_path: print(var)
代码如下: #利用自定义类Mydataset创建对象weather_dataset weather_dataset = Mydataset(all_imgs_path) print(len(weather_dataset)) #返回文件夹中图片总个数 print(weather_dataset[12:15])#切片,显示第12至第十五张图片的路径 wheather_datalodaer = torch.utils.data.DataLoader(weather_dataset, batch_size=5) #每次迭代时返回五个数据 print(next(iter(wheather_datalodaer)))
代码如下: species = ['cloud','sun','rain'] species_to_id = dict((c, i) for i, c in enumerate(species)) print(species_to_id) id_to_species = dict((v, k) for k, v in species_to_id.items()) print(id_to_species) all_labels = [] #对所有图片路径进行迭代 for img in all_imgs_path: # 区分出每个img,应该属于什么类别 for i, c in enumerate(species): if c in img: all_labels.append(i) print(all_labels) #得到所有标签
代码如下: # 对数据进行转换处理 transform = transforms.Compose([ transforms.Resize((96,96)), #做的第一步转换 transforms.ToTensor() #第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前 ]) class Mydatasetpro(data.Dataset): # 类初始化 def __init__(self, img_paths, labels, transform): self.imgs = img_paths self.labels = labels self.transforms = transform # 进行切片 def __getitem__(self, index): #根据给出的索引进行切片,并对其进行数据处理转换成Tensor,返回成Tensor img = self.imgs[index] label = self.labels[index] pil_img = Image.open(img) #pip install pillow data = self.transforms(pil_img) return data, label # 返回长度 def __len__(self): return len(self.imgs) BATCH_SIZE = 10 weather_dataset = Mydatasetpro(all_imgs_path, all_labels, transform) wheather_datalodaer = data.DataLoader( weather_dataset, batch_size=BATCH_SIZE, shuffle=True ) imgs_batch, labels_batch = next(iter(wheather_datalodaer)) print(imgs_batch.shape) plt.figure(figsize=(12, 8)) for i, (img, label) in enumerate(zip(imgs_batch[:6], labels_batch[:6])): img = img.permute(1, 2, 0).numpy() plt.subplot(2, 3, i+1) plt.title(id_to_species.get(label.item())) plt.imshow(img) plt.show()#展示图片
代码如下: #划分测试集和训练集 index = np.random.permutation(len(all_imgs_path)) all_imgs_path = np.array(all_imgs_path)[index] all_labels = np.array(all_labels)[index] #80% as train s = int(len(all_imgs_path)*0.8) print(s) train_imgs = all_imgs_path[:s] train_labels = all_labels[:s] test_imgs = all_imgs_path[s:] test_labels = all_imgs_path[s:] train_ds = Mydatasetpro(train_imgs, train_labels, transform) #TrainSet TensorData test_ds = Mydatasetpro(test_imgs, test_labels, transform) #TestSet TensorData train_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)#TrainSet Labels test_dl = data.DataLoader(test_ds, batch_size=BATCH_SIZE, shuffle=True)#TestSet Labels至此我们把原数据集的80%作为训练集得到了: train_ds 训练集数据 test_ds 测试集数据 train_dl 训练集标签 test_dl 测试集标签 总结整体思路 1.将自己所找图片按照一定的规则命名后,放到文件夹中。 2.使用glob方法获取所有数据文件路径 3.创建DataSet类的子类Mydataset,用于后续通过路径读入数据,并易于后续相应处理操作 4.通过Transforms.Compose()方法,对图片数据进行统一处理,并转换成Tensor格式 5.创建Mydatasetpro类,调用相关方法,获得{‘图片名’:标签}和{标签:‘图片名’}字典 6.统计索引数量,按照百分比,划分出训练集和测试集 最后得到:训练集数据、测试集数据、训练集标签、测试集标签 本文代码 import glob import torch from torch.utils import data from PIL import Image import numpy as np from torchvision import transforms import matplotlib.pyplot as plt #通过创建data.Dataset子类Mydataset来创建输入 class Mydataset(data.Dataset): # 类初始化 def __init__(self, root): self.imgs_path = root # 进行切片 def __getitem__(self, index): img_path = self.imgs_path[index] return img_path # 返回长度 def __len__(self): return len(self.imgs_path) #使用glob方法来获取数据图片的所有路径 all_imgs_path = glob.glob(r'F:\weather\*\*.jpg') #循环遍历输出列表中的每个元素,显示出每个图片的路径 for var in all_imgs_path: print(var) #利用自定义类Mydataset创建对象weather_dataset weather_dataset = Mydataset(all_imgs_path) print(len(weather_dataset)) #返回文件夹中图片总个数 print(weather_dataset[12:14])#切片,显示第12张、第十三张图片,python左闭右开 wheather_datalodaer = torch.utils.data.DataLoader(weather_dataset, batch_size=3) #每次迭代时返回五个数据 print(next(iter(wheather_datalodaer))) species = ['cloud','sun','rain'] species_to_id = dict((c, i) for i, c in enumerate(species)) print(species_to_id) id_to_species = dict((v, k) for k, v in species_to_id.items()) print(id_to_species) all_labels = [] #对所有图片路径进行迭代 for img in all_imgs_path: # 区分出每个img,应该属于什么类别 for i, c in enumerate(species): if c in img: all_labels.append(i) print(all_labels) #得到所有标签 # 对数据进行转换处理 transform = transforms.Compose([ transforms.Resize((96,96)), #做的第一步转换 transforms.ToTensor() #第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前 ]) class Mydatasetpro(data.Dataset): # 类初始化 def __init__(self, img_paths, labels, transform): self.imgs = img_paths self.labels = labels self.transforms = transform # 进行切片 def __getitem__(self, index): #根据给出的索引进行切片,并对其进行数据处理转换成Tensor,返回成Tensor img = self.imgs[index] label = self.labels[index] pil_img = Image.open(img) #pip install pillow data = self.transforms(pil_img) return data, label # 返回长度 def __len__(self): return len(self.imgs) BATCH_SIZE = 10 weather_dataset = Mydatasetpro(all_imgs_path, all_labels, transform) wheather_datalodaer = data.DataLoader( weather_dataset, batch_size=BATCH_SIZE, shuffle=True ) imgs_batch, labels_batch = next(iter(wheather_datalodaer)) print(imgs_batch.shape) plt.figure(figsize=(12, 8)) for i, (img, label) in enumerate(zip(imgs_batch[:6], labels_batch[:6])): img = img.permute(1, 2, 0).numpy() plt.subplot(2, 3, i+1) plt.title(id_to_species.get(label.item())) plt.imshow(img) plt.show() #划分测试集和训练集 index = np.random.permutation(len(all_imgs_path)) all_imgs_path = np.array(all_imgs_path)[index] all_labels = np.array(all_labels)[index] #80% as train s = int(len(all_imgs_path)*0.8) print(s) train_imgs = all_imgs_path[:s] train_labels = all_labels[:s] test_imgs = all_imgs_path[s:] test_labels = all_labels[s:] train_ds = Mydatasetpro(train_imgs, train_labels, transform) #TrainSet TensorData test_ds = Mydatasetpro(test_imgs, test_labels, transform) #TestSet TensorData train_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)#TrainSet Labels test_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)#TestSet Labels |
 制作了三个文件夹,每个文件夹里面有十张图片,分别是关于云、雨、太阳,所有图片均来自百度图片。
制作了三个文件夹,每个文件夹里面有十张图片,分别是关于云、雨、太阳,所有图片均来自百度图片。  这是cloud文件夹里面的内容,请注意图片命名格式
这是cloud文件夹里面的内容,请注意图片命名格式  这是rain文件夹里面的内容,请注意图片命名格式
这是rain文件夹里面的内容,请注意图片命名格式  这是sun文件夹里面的内容,请注意图片命名格式
这是sun文件夹里面的内容,请注意图片命名格式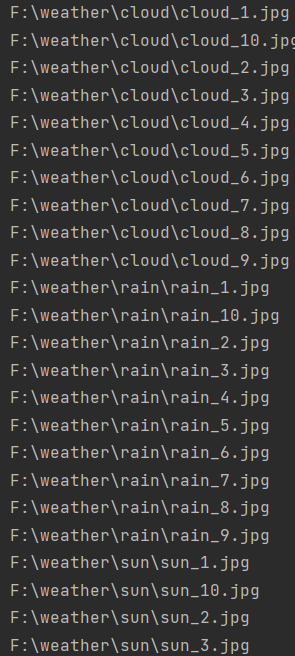 上图为运行结果部分显示
上图为运行结果部分显示 上图为运行结果
上图为运行结果 上图为运行结果
上图为运行结果 上图为运行结果
上图为运行结果【本文地址】