| 2021 | 您所在的位置:网站首页 › 机翼的4个部分是哪些部分组成 › 2021 |
2021
|
决策表
决策表,也叫判定表。在所有的功能性测试方法中,基于决策表的测试方法被认为是最严格的,因为决策表具有逻辑严格性。 决策表是分析和表达多逻辑条件下执行不同操作的情况的工具。在程序设计发展的初期,决策表就已被用作编写程序的辅助工具了。它可以把复杂的逻辑关系和多种条件组合的情况表达得比较明确。方便程序员无需知道背后复杂的逻辑关系就能看出动作对应的状态。 决策表 决策表一直被用来表示和分析复杂逻辑关系。决策表很适合描述丌同条件集合下采取行动的若干组合的情况。 决策表有四个部分:桩部分、条目部分、条件部分、行动部分。 决策表的测试 决策表的条件是真值表 保证能够考虑了所有可能的条件组合 使用决策表标识测试用例,能够保证一种完备的测试 为了使用决策表标识测试用例,我们把条件解释为输入,把行动解释为输出。 决策表是说明性的,给出的条件没有特别的顺序,而且所选择的行动发生时也没有任何特定顺序 1、决策表的组成 决策表通常由4个部分组成,如下图: ●动作桩(action stub):列出了问题规定可能采取的操作。这些操作的排列顺序没有约束。 蓝色部分 ●条件项(condition entry):列出针对它所列条件的取值,在所有可能情况下的真假值。 绿色部分 ●动作项(action entry):列出在条件项的各种取值情况下应该采取的动作。 粉红色部分 ●规则:任何一个条件组合的特定取值及其相应要执行的操作。在决策表中贯穿条件项和动作项的一列就是一条规则。显然,决策表中列出多少组条件取值,也就有多少规则,条件项和动作项就有多少列。 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。 由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。 分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。 决策树是一种树形结构,它主要有三种不同的节点:决策节点:它表示的是一个中间过程,主要是用来与一个数据集中各个属性的取值作对比,以此来判断下一步的决策走向趋势。状态节点:代表备选方案的期望值,通过各个状态节点的对比,可以选出最佳的结果。结果节点:它代表的是该类最终属于哪一个类别,同时也可以很清晰的看出该模型总共有多少个类别。最终,一个数据实例根据各个属性的取值来得到它的决策节点 常见决策树分类算法: (1)、CLS算法:是最原始的决策树分类算法,基本流程是,从一棵空数出发,不断的从决策表选取属性加入数的生长过程中,直到决策树可以满足分类要求为止。CLS算法存在的主要问题是在新增属性选取时有很大的随机性。 (2)、ID3算法:对CLS算法的最大改进是摒弃了属性选择的随机性,利用信息熵的下降速度作为属性选择的度量。ID3是一种基于信息熵的决策树分类学习算法,以信息增益和信息熵,作为对象分类的衡量标准。ID3算法结构简单、学习能力强、分类速度快适合大规模数据分类。但同时由于信息增益的不稳定性,容易倾向于众数属性导致过度拟合,算法抗干扰能力差。 ID3算法的核心思想:根据样本子集属性取值的信息增益值的大小来选择决策属性(即决策树的非叶子结点),并根据该属性的不同取值生成决策树的分支,再对子集进行递归调用该方法,当所有子集的数据都只包含于同一个类别时结束。最后,根据生成的决策树模型,对新的、未知类别的数据对象进行分类。 ID3算法优点:方法简单、计算量小、理论清晰、学习能力较强、比较适用于处理规模较大的学习问题。 ID3算法缺点:倾向于选择那些属性取值比较多的属性,在实际的应用中往往取值比较多的属性对分类没有太大价值、不能对连续属性进行处理、对噪声数据比较敏感、需计算每一个属性的信息增益值、计算代价较高。 (3)、C4.5算法:基于ID3算法的改进,主要包括:使用信息增益率替换了信息增益下降度作为属性选择的标准;在决策树构造的同时进行剪枝操作;避免了树的过度拟合情况;可以对不完整属性和连续型数据进行处理;使用k交叉验证降低了计算复杂度;针对数据构成形式,提升了算法的普适性。 (4)、SLIQ算法:该算法具有高可扩展性和高可伸缩性特质,适合对大型数据集进行处理。 (5)、CART(Classification and RegressionTrees, CART)算法:是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子节点都有两个分支,因此,CART算法生成的决策树是结构简洁的二叉树。 |
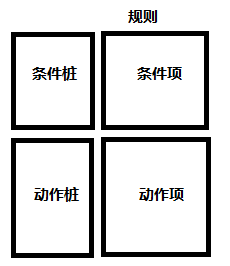 ●条件桩(condition stub):列出了问题的所有条件。通常认为列出的条件的次序无关紧要。 红色部分
●条件桩(condition stub):列出了问题的所有条件。通常认为列出的条件的次序无关紧要。 红色部分


【本文地址】