| 利用BP网络实现非线性函数映射(基于matlab工具箱) | 您所在的位置:网站首页 › 映射关系函数怎么求 › 利用BP网络实现非线性函数映射(基于matlab工具箱) |
利用BP网络实现非线性函数映射(基于matlab工具箱)
|
利用BP网络实现非线性函数映射(基于matlab工具箱)
目录
利用BP网络实现非线性函数映射(基于matlab工具箱)一、网络结构二、学习过程三、学习结果四、误差分析五、实验总结附录(源程序)
实验目的:自己设计一个BP网络实现非线性函数映射
基本要求:设有两输入单输出函数
f
(
x
,
y
)
=
2
x
2
+
s
i
n
(
y
+
π
4
)
f(x,y)=2x^2+sin(y+\frac{\pi}{4})
f(x,y)=2x2+sin(y+4π)
其中自变量x,y的取值范围为
(
−
2
π
,
2
π
)
(-2\pi,2\pi)
(−2π,2π)
试设计一个BP网络实现此函数映射。要求以完整的实验报告形式描述网络的结构、学习过程、结果,以附录形式附源程序。
一、网络结构
首先建立简单的BP神经网络模型,隐层神经元个数为10,输入二维,为函数的两个自变量x和y,输出为函数值的估计值,为一维。 在此基础上建立三层BP神经网络,两个隐层神经元个数都为10,输入二维,为函数的两个自变量x和y,输出为函数值的估计值,为一维。 使用自己编写的子函数GetInput生成训练数据,可以自行指定生成的数据个数。调用格式为:[Input,Output] = GetInput(SampleNum) (1)首先尝试自己通过编程实现简单的BP网络 参数设置为: 总体样本30个,其中训练样本21个,验证样本5个,测试样本4个。 最多训练次数为10000次,允许误差选为10-7,学习速率为0.01。 传输函数为 y = x y=x y=x(purelin)最简单的一一对应关系。 训练算法为梯度下降法,不断地对权值矩阵W1、W2,阈值矩阵B1、B2进行修正,最终达到训练效果。 (2)利用matlab自带的神经网络工具箱搭建BP网络 备注:也尝试了GUI界面编程,但是无法以代码形式展现,其工作过程与命令行操作相同。 一共构建了两个网络:10-10-1和10-1,即第一部分中提到的两个网络。 网络10-10-1参数设置为: 总体样本分别为100个和1000个,其中训练样本70%,验证样本15%,测试样本15%。 最多训练次数为10000次,允许误差选为 1 0 − 7 10^{-7} 10−7,学习速率为0.01,动量因子为0.9。 隐层传输函数为 y = 1 − e − x 1 + e − x y=\frac{1-e^{-x}}{1+e^{-x}} y=1+e−x1−e−x(tansig),输出层传输函数为 y = x y=x y=x(purelin)。 训练算法为神经网络训练中常用的L-M算法(trainlm) 网络10-1参数设置为: 总体样本分别为100个、300个、500个和1000个,其中训练样本70%,验证样本15%,测试样本15%。 最多训练次数为10000次,允许误差选为10-7,学习速率为0.01,动量因子为0.9。 隐层传输函数为 y = 1 − e − x 1 + e − x y=\frac{1-e^{-x}}{1+e^{-x}} y=1+e−x1−e−x(tansig),输出层传输函数为 y = x y=x y=x(purelin)。 训练算法为神经网络训练中常用的L-M算法(trainlm) 三、学习结果(1)自己编程搭建的BP神经网络 30个训练样本和30个随机样本的验证结果
网络学习结果拟合图
(2)神经网络工具箱搭建的BP网络 Net1:10-10-1,100个样本 
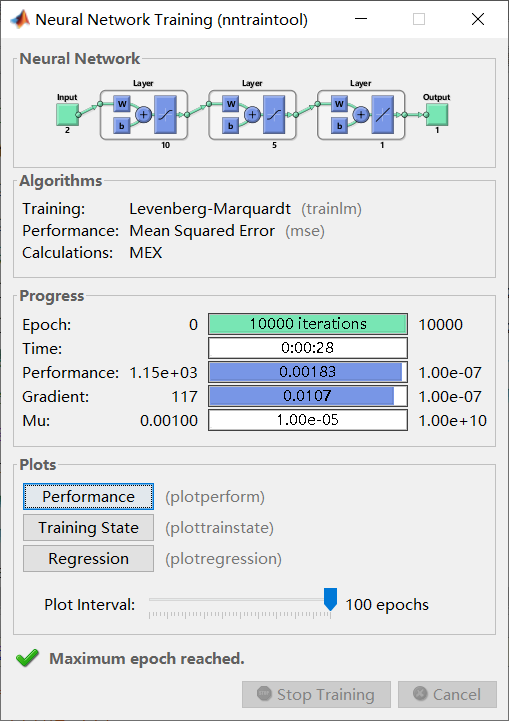
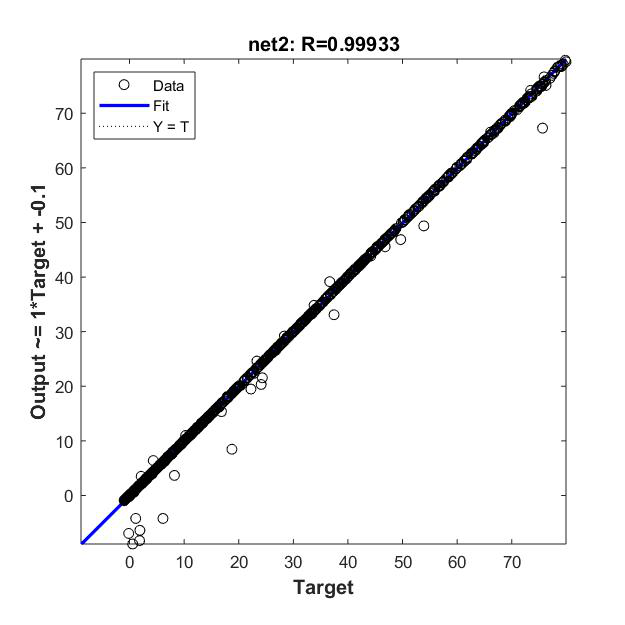
Net2:10-1,100个样本 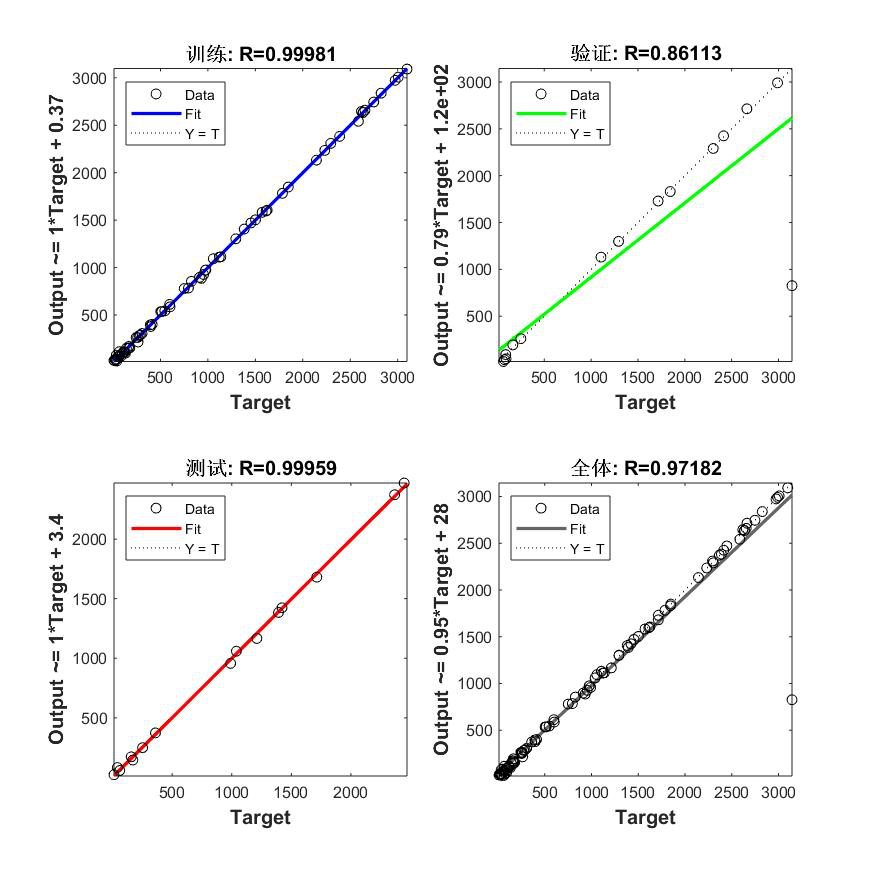

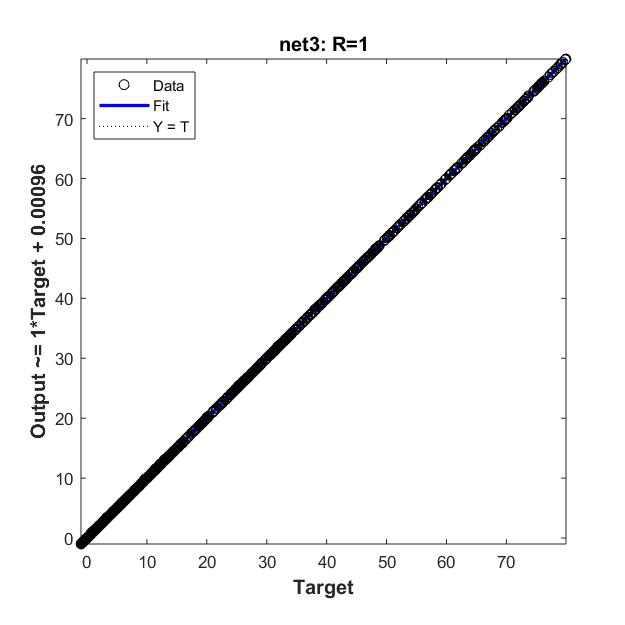
Net3:10-1,300个样本 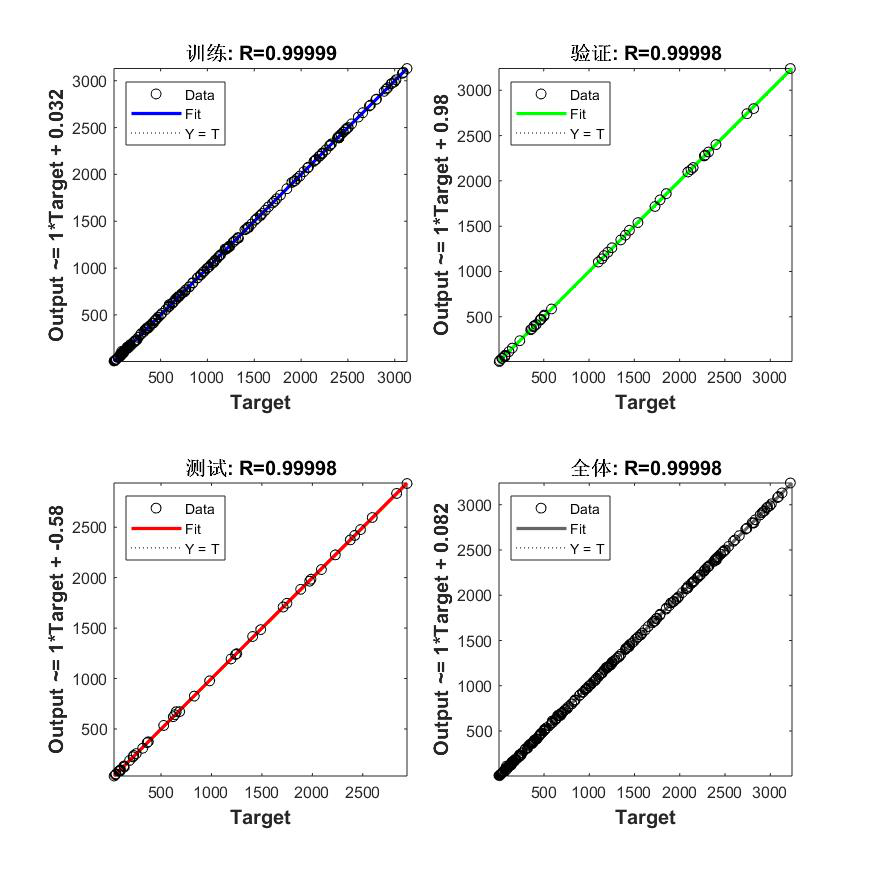

Net4:10-1,500个样本 

Net5:10-1,1000个样本 
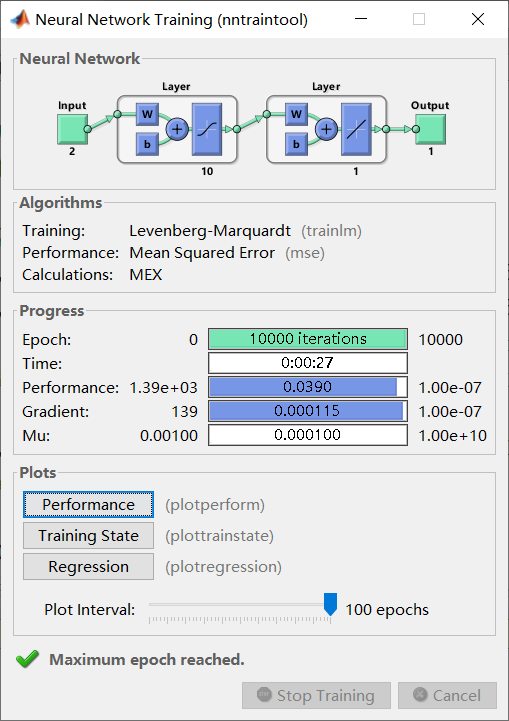
Net6:10-10-1,1000个样本 
 四、误差分析
四、误差分析
(1)自己编程搭建的BP神经网络 标准差:3.5937 (2)神经网络工具箱搭建的BP网络 标准差: 40.4614 / 0.8592 / 0.0310 0.5113 / 0.2013 / 0.2013 


 五、实验总结
五、实验总结
这次实验中,我先尝试使用matlab自己编写了BP神经网络,输入映射函数使用最简单的y=x,训练算法采用梯度下降法。在实际操作中我发现当训练样本数大于28时,极有可能会陷入局部最优解,导致神经网络误差偏大,当训练样本数大于57时,误差甚至会随着迭代次数的增加而发散,这也是最基础的神经网络中难以避免的问题。20多个训练样本是比较合适的,所以总样本数选取了30。在训练样本和随机样本的检测下都显示出了比较好的效果。最后误差检验的结果显示,拟合图比较均匀地分布在直线两侧,标准差也不算太大。 由于经典梯度下降法有着各种各样的问题,我在调用神经网络工具箱时采用了现在普遍使用的L-M算法,同时也尝试搭建了三层的BP神经网络。在两层神经网络中,预测精度得到了明显的提高,而且随着训练样本的增加,精度也有提高的趋势。然而事情也并非绝对,在精度达到一个阈值时,即使增加样本,精度也不会有明显的提高。而且训练有着一定的偶然性,即使样本数很少,初始条件选择合适的话也会比样本数多的模型精度更高。而三层网络在训练样本数少时预测效果反而没有两层的好,当样本数较多时效果和两层模型相同,这也提醒我,当问题比较简单时,不要贸然增加网络深度,有时候网络过深也不见得是一件好事。 附录(源程序)(1)自编 训练函数: % function main() clc % 清屏 clear all; %清除内存以便加快运算速度 close all; %关闭当前所有figure图像 Num=30; %所有样本总个数 TrainSamNum=0.7*Num; %输入样本数量为21 ValSamNum=1/6*Num; %验证样本数量为5 TestSamNum=2/15*Num; %测试样本数量也是4 HiddenUnitNum=10; %中间层隐节点数量取10 InDim=2; %网络输入维度为2 OutDim=1; %网络输出维度为1 %原始数据 [p,t] = GetInput(Num);%生成输出p和输入t %输入数据矩阵p %目标数据矩阵t [SamIn,minp,maxp,SamOut,mint,maxt]=premnmx(p,t); %原始样本对(输入和输出)初始化,进行了数据的归一化 [TrainSamIn,ValSamIn,TestSamIn] =divideblock(SamIn,0.7,1/6,2/15); [TrainSamOut,ValSamOut,TestSamOut] =divideblock(SamOut,0.7,1/6,2/15); rand('state',sum(100*clock)) %依据系统时钟种子产生随机数 NoiseVar=0.01; %噪声强度为0.01(添加噪声的目的是为了防止网络过度拟合) Noise=NoiseVar*randn(1,TrainSamNum); %生成噪声 TrainSamOut=TrainSamOut + Noise; %将噪声添加到输出样本上 MaxEpochs=10000; %最多训练次数为10000 lr=0.01; %学习速率为0.01 E0=1e-7; %目标误差为1e-7 W1=0.5*rand(HiddenUnitNum,InDim)-0.1; %初始化输入层与隐含层之间的权值 B1=0.5*rand(HiddenUnitNum,1)-0.1; %初始化输入层与隐含层之间的阈值 W2=0.5*rand(OutDim,HiddenUnitNum)-0.1; %初始化输出层与隐含层之间的权值 B2=0.5*rand(OutDim,1)-0.1; %初始化输出层与隐含层之间的阈值 W11=W1;W22=W2;B11=B1;B22=B2; ErrHistory=[]; %给中间变量预先占据内存 for i=1:MaxEpochs HiddenOut=logsig(W1*TrainSamIn+repmat(B1,1,TrainSamNum)); % 隐含层网络输出 NetworkOut=W2*HiddenOut+repmat(B2,1,TrainSamNum); % 输出层网络输出 Error=TrainSamOut-NetworkOut; % 实际输出与网络输出之差 SSE=sumsqr(Error); %能量函数(误差平方和) ErrHistory=[ErrHistory SSE]; if SSE |





【本文地址】