| (毫米波雷达数据处理中的)聚类算法(1) | 您所在的位置:网站首页 › 星越L5个毫米波雷达作用 › (毫米波雷达数据处理中的)聚类算法(1) |
(毫米波雷达数据处理中的)聚类算法(1)
|
说明
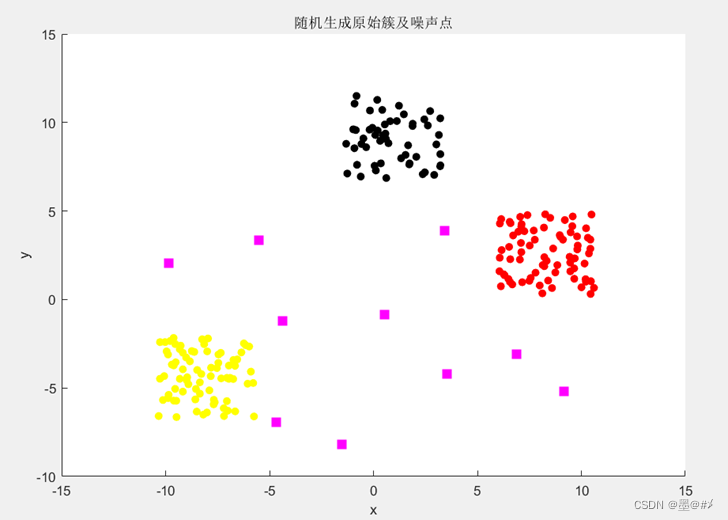
聚类算法的应用范围是很广的,在毫米波雷达数据处理中的应用只是其一。(所以我在文章标题中对“毫米波雷达数据处理中的”加了括号)。关于该话题,我现阶段规划了三篇博文,本文作为第一篇,对聚类算法做一些宽泛性/框架性的介绍,后面的博文我将基于数据实践两种典型的聚类算法(DBSCAN和K-means)。(本系列文章不只限于车载雷达数据处理上的应用)。 Blog 2024.5.15 博文第一次撰写 目录说明 目录 一、聚类算法在车载雷达上的应用讨论 二、聚类算法概述 --- 一些典型的聚类算法 三、可用于聚类实践的现有数据集以及数据集生成 3.1 现有数据集介绍 3.2 二维平面内点簇形数据生成介绍与仿真 四、聚类算法的评价指标 五、总结 六、参考资料 七、参考代码和数据集 一、聚类算法在车载雷达上的应用讨论在车载雷达领域,传统的3D雷达其实主要着眼于运动目标,通常而言,单个运动目标(比如前方的车辆)经过CFAR检测后会出现比较多的点云,在对该目标进行跟踪之前,我们一般会使用聚类算法将同一个目标对应的诸多点云聚成一个点用来表征该目标(因为这些点云表示的是同一个目标,我们没有必要浪费内存和计算资源对全部的点云进行跟踪并维护航迹),这是聚类算法在车载毫米波雷达数据处理中存在的必要性。现如今,4D雷达的普及下,有了更致密的点云后,我们开始越来越多的关注目标轮廓、以及包括路沿、桥梁等车道周边环境在内的绝大多数的静止目标,我们希望可以从雷达回波中寻找和保留更多的信息!但是我们知道,从回波ADC数据到点云聚类这整个的信号和数据处理流程中,其实每一步都在丢掉一些信息,其中以聚类最为“严重”,当我们开始关注目标轮廓时,聚类算法就显得多余了,不过对于运动目标的航迹维护,在跟踪前还是少不了先聚类。 对于车载雷达的数据处理,我们最常用的是基于密度的聚类算法DBSCAN。 二、聚类算法概述 --- 一些典型的聚类算法物以类聚,聚类说白了就是把同类的聚在一起:对一个数据集合,我们基于一些特征(或者准则),将之分成多个不同的类(或簇),使得同一个簇内数据的相似性尽可能大、不同簇中的数据对象的差异性尽可能大。聚类是一种探索性的数据分析技术,它可以帮助我们发现数据中的内在结构,而不依赖于预先标注,所以聚类也是机器学习中无监督学习的一个典型应用! 经过多年的发展,现如今已经有很多的聚类算法可以给我们使用。以下是我从Kimi(Kimi.ai - 帮你看更大的世界 (moonshot.cn))中输入“典型聚类算法”后它给我的输出: 聚类算法是无监督学习中用来发现数据内在结构的一系列方法。根据搜索得到的结果,以下是一些典型的聚类算法: K-Means聚类算法:K-Means算法是一种划分式聚类方法,它通过迭代选择簇中心点,将数据点分配到最近的簇中心,然后更新簇中心为分配给它的点的均值,直到收敛。K-Means算法简单、快速,适用于大型数据集,但需要预先指定簇的数量,且对初始簇中心敏感。层次聚类算法:层次聚类通过创建一个簇的层次结构来进行聚类。它不需要预先指定簇的数量,可以用于发现数据集的层次结构。层次聚类分为聚合的(自底向上)和分裂的(自顶向下)两种策略。DBSCAN(Density-Based Spatial Clustering of Applications with Noise):基于密度的聚类算法,能够识别任意形状的簇,并对噪声点具有良好的鲁棒性。DBSCAN通过定义核心点和密度阈值来识别簇,但对参数敏感。Mean Shift聚类算法:Mean Shift是一种基于密度的非参数聚类算法,通过寻找密度函数的局部极大值点来确定簇中心,不需要预先指定簇的数量。谱聚类(Spectral Clustering):谱聚类利用数据的相似性矩阵来进行聚类,它通过将相似性矩阵转换为特征向量和特征值,然后在较低维的空间中进行聚类。GMM(Gaussian Mixture Models):高斯混合模型是一种基于概率的聚类方法,它将数据集建模为多个高斯分布的混合,每个分布对应一个簇。OPTICS:是DBSCAN算法的扩展,用于处理不同密度区域的聚类问题,通过生成一个特殊顺序的数据集来解决参数选择的问题。K-Modes:适用于分类属性数据的聚类算法,可以给出类的特性描述。基于网格的聚类算法:如GDILC(Grid Density Isoline Clustering),使用密度等值线图描述样本分布,适用于大型、高维数据集。基于模型的方法:如高斯混合模型,通过建立数据的概率模型来进行聚类。每种算法都有其特定的应用场景和优缺点,选择合适的聚类算法通常取决于数据集的特性和聚类的目标。 上面的介绍比较简单,但算是比较全的了,读者对更多的细节感兴趣的话可以自行查找相关资料。在后续的博文中我将主要关注DBSCAN和K-means这两种典型的CFAR算法,对其进行更细致的介绍和实践。 三、可用于聚类实践的现有数据集以及数据集生成本章分享一些可用于聚类的现有数据集,并介绍和仿真实践点簇形数据集的生成。 3.1 现有数据集介绍比较经典且应用广泛的就是UCI的数据集[1]。(网站中的数据集是面向机器学习的,不仅只有用于聚类的数据集),更细节的链接,可以参考博文[2],这些数据集都可以从[1]中下载。我下载了一些,并将之一并打包在了后文的代码和数据集链接中,读者可以一并下载。在后续的两博文中,我将以其中的Iris数据(Iris - UCI Machine Learning Repository)作为聚类的实践对象。 3.2 二维平面内点簇形数据生成介绍与仿真除上述现有的数据集外,我们也可以自行生成一些数据来实践聚类算法。如参考资料[3]中所介绍的,[3]中也给出了一些参考代码,不过没有Matlab版本的,我自编了一份二维平面内点簇形数据集生成的代码,一并打包在了后文的代代码和数据集链接中,在后续的两博文中,我将使用DBSCAN和K-means两种聚类算法分别实践前述Iris数据集以及本节所生成的点簇数据集。 这里给出该点簇形数据集的参数设置以及生成结果:【该数据集似乎看起来很容易生成,但实践起来还是有很多细节的。】 表3.1 二维平面内点簇形数据集的参数设置列表 参数 值 簇数量 3 每个簇内点的数量范围 [50 80] (随机确定) 生成的点在二维平面内的范围 X:[-10 10]; Y:[-10 10] (为一个矩形区域) 任意两个簇簇中心之间的距离D > 矩形区域对角线长度/簇数量 任意一个簇内点的范围 以簇中心为中心,以2*D/M为边长的正方形区域,在后续的仿真中,M取4 噪声点的数量 10 对每个噪声点的要求 不属于任意一个簇的范围内 (前述任意参数读者都可以在我提供的代码中很方便更改) 在前述参数设计下,生成的点簇如下图所示:
图3.1 随机生成的二维平面内的点簇 图中,三组不同颜色的圆点表示三类簇,品红色的矩形方块表示噪声点。在后续的聚类实践中,将所生成的全部的点输入聚类算法,看看聚类后的结果是否与上图所生成的结果相近。 四、聚类算法的评价指标聚类完成后,如何客观地评价聚类的效果(好?坏?)是很重要的。本章介绍几种聚类算法的评价指标(聚类算法的评价指标不限于后文介绍的4种,但有了后文介绍的4种我觉得应该也够了,在后续的聚类实践中,我将针对本章介绍的这4个指标分别给出对应的计算函数,并计算DBSCAN和K-means两种聚类算法下聚类结果的上述客观评价指标值)。本章的内容主要是参考资料[4][5],如果后面的描述读者有不清楚的可以再看看其它的资料。 1. 紧密度(Compactness) 紧密度顾名思义是表征聚类后的簇的紧密程度,该指标是通过计算每个簇中样本点到聚类中心的平均距离,并对全部簇的紧密度再求均值得到。不难理解的是:紧密度越小,表示簇内的样本点越集中,样本点之间距离越短,也就是说簇内相似度越高。
式中,compactnessi表示第i个簇的紧密度,n表示第i个簇中包含有n个样本点, 2. 分割度(Seperation) 分割度表征各簇之间的分离程度,分割度通过求解各簇的簇心之间的平均距离得到,分割度值越大说明簇间的间隔越远,即簇间相似度越低,聚类效果越好。 该值可以通过先求得各个簇的簇中心,然后构造嵌套的两个for循环求得。 3. 戴维森堡丁指数(Davies-bouldin Index,DBI) DBI用来衡量任意两个簇的簇内距离之和(两簇的紧密度之和)与簇间距离之比。该指标越小表示簇内距离越小,簇内相似度越高,簇间距离越大,簇间相似度低。其计算方法如下:
式中,DBI为聚类结果的戴森堡丁指数,K表示有K个簇,Rij表征簇i和簇j之间的相似度,si表示簇i的紧密度,其计算方法已经在前文式(4-1)中给出,dij表示簇i和簇j之间的距离(两簇中心之间的距离)。 4. 轮廓系数(Silhouette Coefficient) 我们定义任意一个样本点的轮廓系数为:
式中,a(i)表示样本点i的内聚度,通过求解其与其所在簇内的其它点的距离均值得到:
b(i)表示样本点i离其它簇的簇间距离,通过求解该点与其它簇中所有点之间的距离均值得到,假设聚类后一共有M个簇,则对于任意簇内的样本点,我们可以得到M-1个b(i),在求解S(i)时,我们选取其中最小的b(i)来计算。 基于式(4-5)、(4-6)我们可以求得任意一个样本点的轮廓系数,随后我们对全部样本点的轮廓系数求均值得到最终的轮廓系数值。 五、总结本文对聚类算法做了一些宽泛性/框架性的介绍。具体地,介绍了几种聚类算法、给出了一个可用作聚类算法实践的数据集、给出了一种自己生成二维平面内点簇的方法以及生成的结果、介绍了4种聚类结果的客观评价指标。本文的工作为后续基于具体的聚类算法的实践打下了基础。 六、参考资料[1] Datasets - UCI Machine Learning Repository [2] 一些用于聚类和分类问题的数据集_聚类和分类融合的数据-CSDN博客 [3] 机器学习中常用的聚类数据集生成方法_用于聚类的合成数据集-CSDN博客 [4] 轮廓系数、方差比、DB指数(三种常见的聚类内部评价指标) - 知乎 (zhihu.com) [5] 6个常用的聚类评价指标 - 知乎 (zhihu.com) 七、参考代码和数据集我将本聚类算法系列的三篇博文所涉及的代码和数据集打包成了一份,其内含如下内容:
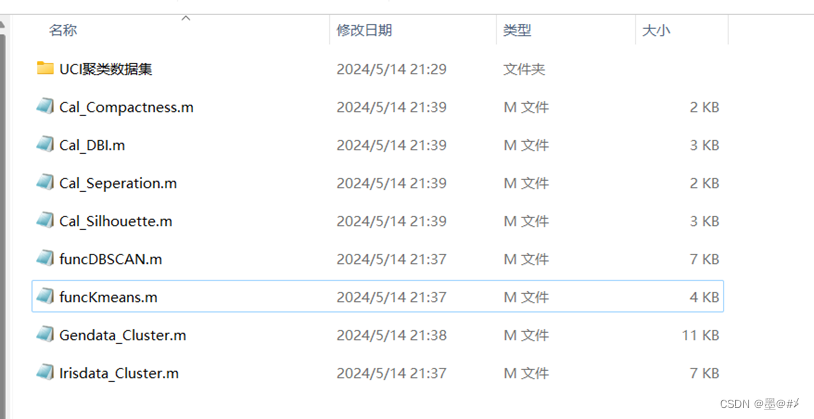
图中,UCI聚类数据集包含了多个可用于聚类算法实践的数据集;前四个m文件为本文第4章所介绍的四种客观评价指标的计算函数;funcDBSCAN为基于DBSCAN算法的聚类函数,funcKmeans为基于K-means算法的聚类函数;Gendata_Cluster.m为主函数,该函数首先生成点簇数据集,然后分别调用funcDBSCAN.m、funcKmeans.m完成聚类以及聚类结果的展示,最后再分别调用前面的四个客观指标计算函数完成客观评价指标的计算;Irisdata_Cluster.m则是另一个主函数,该函数获取UCI的Iris数据集,并对该数据集做一些处理(包括降维),随后和Gendata_Cluster.m函数一样,完成聚类、客观指标计算等流程。读者可以自行下载参考,链接为(抱歉,要收费): (毫米波雷达数据处理中的)聚类算法系列博文对应的代码和数据集资源-CSDN文库 |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |