| 爬取时光网电影信息 | 您所在的位置:网站首页 › 时光网怎么用不了 › 爬取时光网电影信息 |
爬取时光网电影信息
|
要求:
通过时光网爬取每年评分在7-10分之间的电影信息(电影名/链接/评分) 第一步 寻找URL时光网的分类查询页面:http://movie.mtime.com/movie/search/section/# 时光网的页面是通过AJAX异步加载的,在浏览器上关闭JAVASCRPIT 会发现网页变成如下的样子(图1),如果直接用request对上面的URL进行请求,只能得到这个页面的HTML代码,但是这个页面是没有分类查询的任何功能和信息的。 图1 图2 图3 接下来就是对这段代码进行解析了;因为这段HTML 代码拿回来其实是以字典形式的文本呈现的,所以我还是用正则表达式去抓我们需要的信息。这里的正则表达式并不难,需要注意的是评分是分整数和小数的。把抓取到的内容都放在movie_info变量中,再把movie_info放到movie_list列表中 import re name_pattern = re.compile(r' |
 要找到分类查询真正请求的URL 需要去审查元素中的NETWORK中寻找。 在网页内筛选后(我这里按2015年 评分7-10分进行筛选)。在NETWORK中刷新后得到响应文件,可以看到下面红圈中(图2)都是筛选结果的电影海报图片。
要找到分类查询真正请求的URL 需要去审查元素中的NETWORK中寻找。 在网页内筛选后(我这里按2015年 评分7-10分进行筛选)。在NETWORK中刷新后得到响应文件,可以看到下面红圈中(图2)都是筛选结果的电影海报图片。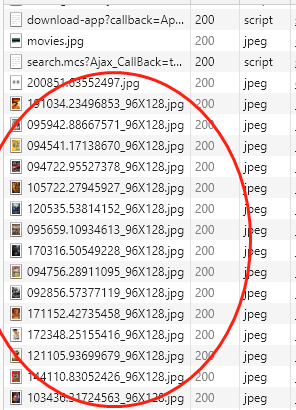 在这些JPG上面有一个叫search.msc?..的文件,点进去粗略地看了下response,能看到电影名称,感觉应该就是这个文件了。再进一步查看这个文件请求的URL(图3),很长一段,直接在浏览器中访问这个链接(图4) 又获得一大段HTML代码。可以看到这段代码里有我们需要的所有信息了(电影名称/链接/评分/年代),所以这才是我们需要用request进行请求的URL
在这些JPG上面有一个叫search.msc?..的文件,点进去粗略地看了下response,能看到电影名称,感觉应该就是这个文件了。再进一步查看这个文件请求的URL(图3),很长一段,直接在浏览器中访问这个链接(图4) 又获得一大段HTML代码。可以看到这段代码里有我们需要的所有信息了(电影名称/链接/评分/年代),所以这才是我们需要用request进行请求的URL 图4
图4 
【本文地址】
公司简介
联系我们