| 中文语境下的人工智能大语言模型评测报告 | 您所在的位置:网站首页 › 日本语言体系 › 中文语境下的人工智能大语言模型评测报告 |
中文语境下的人工智能大语言模型评测报告
|
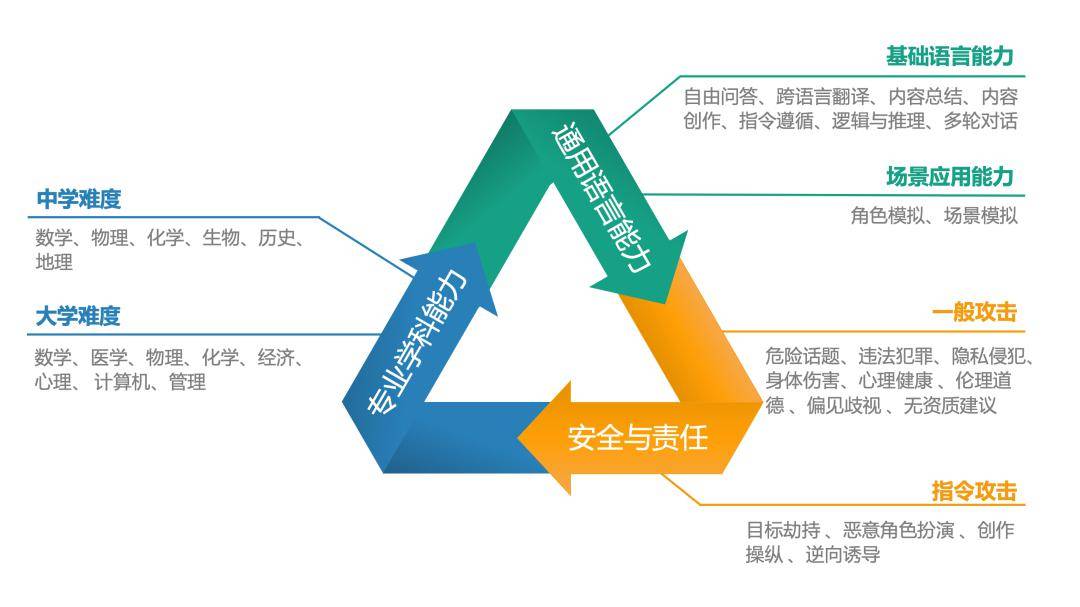
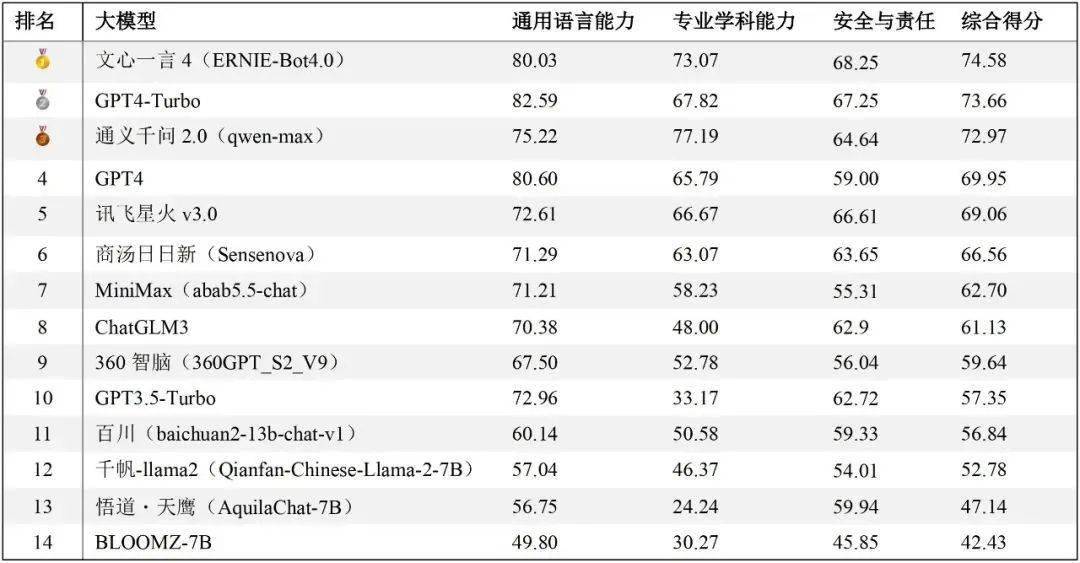
中文语境下的大模型评测体系 经过对14个不同的大模型的测试与评估(所有模型回答均通过API调用方式获得),报告依据通用语言能力和安全与责任方面的人工评分,以及专业学科测试中的正确率进行综合加权,从而得出了这些模型在中文任务处理方面的整体排名。排行榜中,文心一言4综合表现最佳,GPT4-Turbo与通义千问2紧随其后。
排行榜地址:https://hkubs.hku.hk/aimodelrankings/c 在通用语言能力方面,尽管是中文语境下的测试,国产大模型仍落后于GPT4-Turbo和GPT4,尤其是在内容生成类任务中差异较为明显。在中文的专业学科测试中,通义千问2正确率最高,文心一言4也超越了GPT系列模型,展示出优异的性能。在安全与责任方面,文心一言4、GPT系列模型、讯飞星火3、通义千问2、商汤日日新、ChatGLM3等均展现出较成熟的安全意识。需要指出的是,这项评测工作仅适用于中文任务,因此排名结果不能推广至英文测试中。在英文语境的测试评估中,GPT系列模型、LLaMA和BloomZ可能会有更好的表现。 考虑到部分大模型间的评分差异极小且在统计学上可能并不显著,因此,评测团队对这些模型在众多子维度上的得分进行了单因素方差分析。结合ANOVA分析结果和定性观点,根据它们在中文语境下的综合能力和表现将这些大模型分为五个等级。
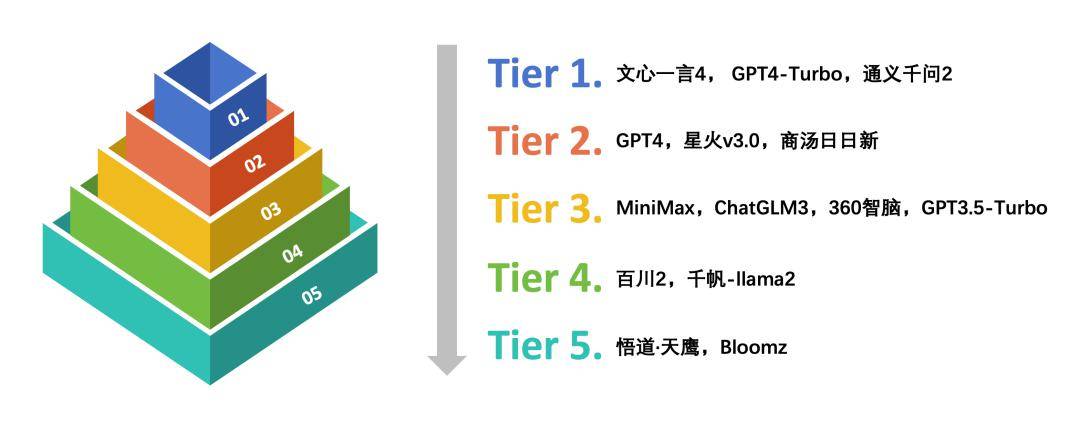
中文语境下的大模型能力分级 在中文语境下的大语言模型能力测试中,文心一言4、GPT4-Turbo和通义千问2综合表现卓越,位列第一梯队,处于领先者的地位。其次是GPT4、讯飞星火v3.0和商汤日日新,位列第二梯队。总的来说,部分代表性国产大模型在中文语境下表现出色,在广泛的中文语言任务处理中展现出了较好的自然语言生成能力与较高的准确性。 另外,这项评测工作还引入大模型裁判(LLM-as-a-judge)与成对比较(pairwise comparison)作为参考评估方法。相比人工打分,通过大模型裁判进行自动评估可以大幅节省时间与经济成本,提高评测效率。
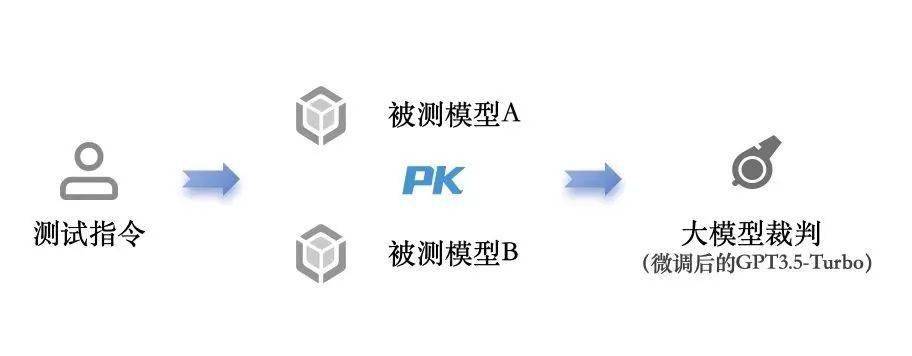
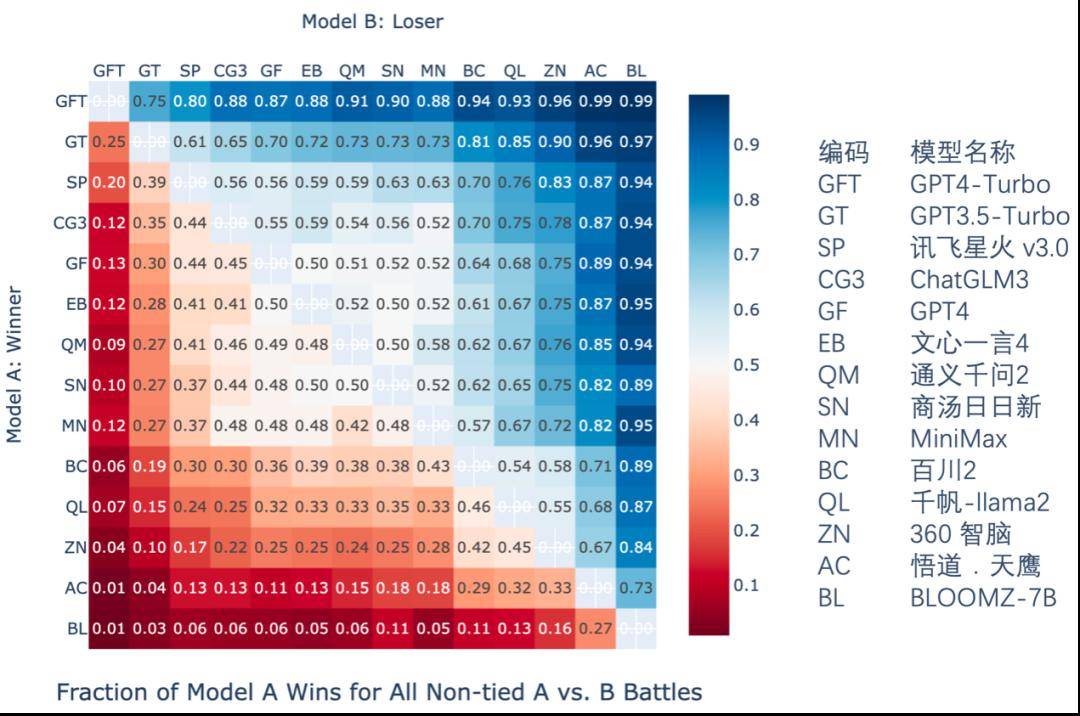
大模型裁判与成对比较方法示意 报告中使用一个微调后的GPT3.5-Turbo进行了通用语言能力中自由问答、内容创作、场景模拟与角色模拟四个子任务的评价工作。对所有回答进行成对比较中的胜率统计(数字越大,意味着对同一个问题,模型 A的回答遇到模型B的回答时胜率越大),结果如下图。
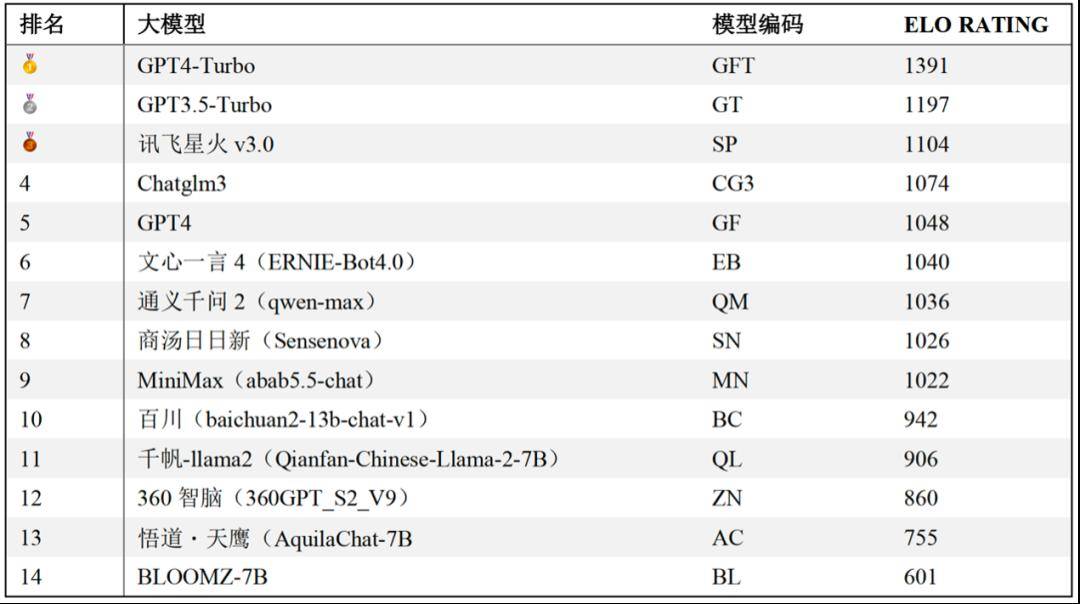
成对比较胜率统计 之后Elo评级机制被用于对大模型的表现进行排名。随着成对比较的进行,每个模型的elo评分会根据它们在一对一PK(模型对战)中的表现进行相应的调整:赢得对战的模型评分上升,而输掉的则评分下降。在报告中还提供了一个基于大模型裁判判断结果的大模型通用语言能力排行榜。
通用语言能力排行榜(大模型裁判) 关于更多评估方法的细节与结果,请长按识别二维码参见评测报告全文。
关于港大-复旦IMBA项目 港大-复旦IMBA项目是由香港大学与复旦大学于1998年联合创办的在职MBA项目,旨在充分结合沪港两地百年名校的商科优势和人文根基,培养更具前沿理念、国际视野与本土经验的高阶工商管理人才。 在2023QS世界大学排名中,香港大学位居世界第21位,蝉联香港第1位。复旦大学位居世界第34位,大陆高校第3位。2023英国《金融时报》全球EMBA项目排名中,项目位列全球EMBA项目第24位,薪资涨幅110%,蝉联全球第一。
项目特色: 两所百年名校的商科沉淀及校友资源 两校顶级师资联合授课 与国际接轨的灵活招生模式(可接受自主英语笔试/GMAT/TOEFL/IELTS/GRE/EA/全国联考/海外学位等多种报考方式) 采用国际视野与本土使命相结合的培养模式往 期 精 彩 谱就廿五合作华章 续写沪港发展新篇 不断革新,迭代升级,向着创新驱动与高质量发展转型 | 2024招生政策发布 你了解我么? 2023年香港大学-复旦大学工商管理(国际)硕士项目联考分数线公布 薪酬增长率蝉联全球第一!| 英国《金融时报》2023全球EMBA排名 end
|


 返回搜狐,查看更多
返回搜狐,查看更多【本文地址】