| chatgpt赋能python:Python分词:从原理到实践 | 您所在的位置:网站首页 › 文本分词方法有哪些 › chatgpt赋能python:Python分词:从原理到实践 |
chatgpt赋能python:Python分词:从原理到实践
|
Python分词:从原理到实践
分词是自然语言处理中的关键步骤之一,它是指将一句话或一段文本分成若干个词语(token)并进行标注。Python作为一种非常流行的编程语言,具备强大的文本处理能力,而分词也是它的强项之一。本文将介绍Python中常用的分词方法和实现原理,以及如何利用Python进行分词。 什么是分词分词是指将一个连续的文本按照一定规则切分成有意义的词汇序列的过程。在自然语言处理中,分词是必要的步骤之一,因为大部分自然语言处理任务都需要先对输入文本进行分词处理,如文本分类、信息检索、机器翻译等。 一个好的分词方法应该能够充分考虑中文语言的特殊性,如单个汉字的意义较小,而多个汉字组合而成的词语则更具有意义,因此在分词时应该优先考虑词语的整体性(例如“北京大学”比“京大”更加准确)。 常用的Python分词方法目前,有许多开源的Python分词库可供选择。下面是介绍一些常用的Python分词方法: 1. jiebajieba是一款开源的中文分词库,是最流行的Python分词库之一。它具有良好的分词速度和准确度,并且支持中文分词、词性标注、关键词提取、新词发现等功能。 2. SnowNLPSnowNLP是由哈工大自然语言处理实验室开发的一个Python库,它提供了中文分词、情感分析、文本分类等功能,其中中文分词效果较好。 3. HanlpHanlp是由中国人民大学自然语言处理实验室开发的一个Java库,但同样也可以通过Python进行调用。它具有较好的中文分词和实体识别效果,在处理专业领域文本时表现优异。 Python分词的实现原理目前,中文分词技术主要有两种实现方法:基于规则的方法和基于统计方法。 1. 基于规则的方法基于规则的分词方法是指通过一定的规则和规则集来进行分词的方法。这种方法需要先编写一些规则,例如设定好一个词语字典,然后按照规则逐步进行分词。由于是通过人工制定规则来进行分词,因此其准确度较高。但当遇到新词或规则不够完善时,其效果会受到影响。 2. 基于统计的方法基于统计的分词方法是指通过大量的文本数据来学习词语的出现频率和分布情况,并根据一定的规则进行分词。这种方法的优点在于能够自动识别新词,但缺点在于需要大量的数据进行训练,而且某些新出现的文本可能无法进行准确的分词。 利用Python进行分词在Python中,我们可以使用刚刚介绍的一些分词库进行分词。下面是使用jieba进行分词的简单例子: import jieba text = "我爱北京天安门" words = jieba.cut(text) print(list(words))其中,jieba.cut()函数将文本分成一个个单独的词语,并返回一个生成器(generator)。最后,我们将它转换为一个列表进行输出,得到的结果如下: ['我', '爱', '北京', '天安门']在进行分词时,我们可以指定jieba的分词模式来进行更加详细的分词,例如: import jieba text = "天之道,损有余而补不足" words = jieba.cut(text, cut_all=True) print(list(words))其中,cut_all=True表示使用全模式进行分词,得到的结果如下: ['天', '之', '道', ',', '损', '有', '余', '而', '补', '不足'] 结论Python分词是自然语言处理领域中的重要技术之一,而且在分词库的支持下,Python分词表现卓越。在分词方法的选择上,需要根据实际应用场景选择合适的分词方法和库。最后,Python分词需要充分考虑中文语言的特殊性,以便得到更加高效和精确的结果。 最后的最后本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。 对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。 🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。 下图是课程的整体大纲 |
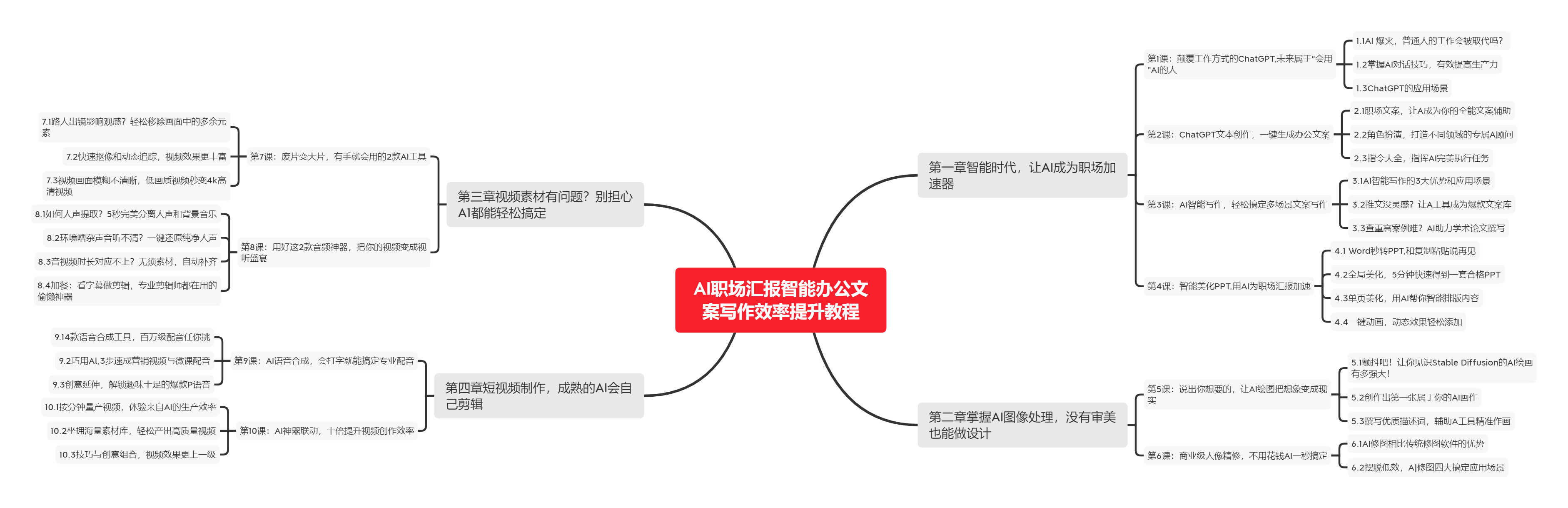
 下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具
下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具 
【本文地址】