| 【机器学习 | 您所在的位置:网站首页 › 文本分类的模型是什么意思啊 › 【机器学习 |
【机器学习
|
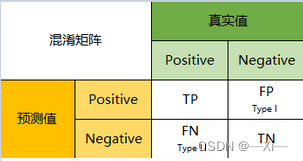
一、混淆矩阵(误差矩阵)
混淆矩阵是评判模型结果的指标,属于模型评估的一部分。此外,混淆矩阵多用于判断分类器(Classifier)的优劣,适用于分类型的数据模型,如分类树(Classification Tree)、逻辑回归(Logistic Regression)、线性判别分析(Linear Discriminant Analysis)等方法。
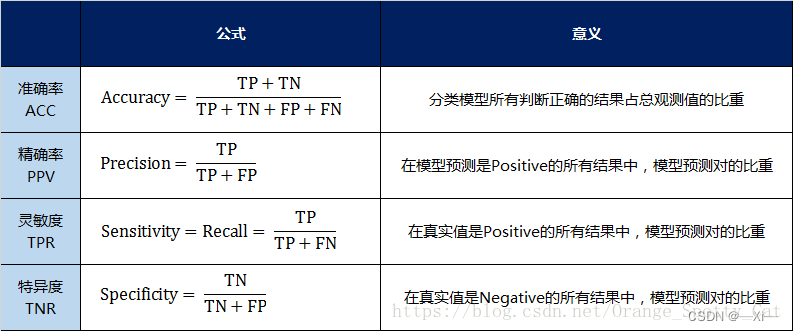
混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又延伸了如下4个指标 准确率(Accuracy)—— 针对整个模型精确率(Precision)灵敏度(Sensitivity)即召回率(Recall) 衡量了分类器对正例的识别能力特异度(Specificity)衡量了分类器对负例的识别能力
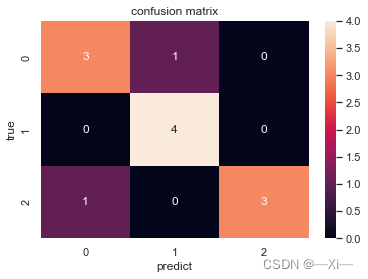
在实际场景中,有时候需要同时关注精准率和召回率。这种情况下我们有一个新的指标:F1 Score,它的计算公式为: F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。 python画混淆矩阵 import seaborn as sns from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt sns.set() f,ax = plt.subplots() y_true = [0,0,1,2,1,2,0,2,2,0,1,1]#真实的分类 y_pred = [1,0,1,2,1,0,0,2,2,0,1,1]#模型的分类结果 C2 = confusion_matrix(y_true,y_pred,labels=[0,1,2]) #打印 C2 print(C2) sns.heatmap(C2,annot=True,ax=ax) #画热力图 ax.set_titile('confusion matrix') #标题 ax.set_xlabel('predict') #x 轴 ax.set_ylabel('true') #y 轴 '''结果 [[3 1 0] [0 4 0] [1 0 3]'''
共三类:对角线值越大说明分类越正确 类1:总数为4(第一行所有元素值相加) ,有一个错误分类,将属于类1的分到类2去了 类2: 总数为4,分类正确率都正确(没有把属于类2分到其他类) ,即召回率等于1 类3:总数为4,有一个错误分类,把属于类3的分到类1去了 sklearn求评估指标 # 评估指标 from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score print('预测数据的准确率为: {:.4}%'.format(accuracy_score(y_test,y_pred)*100)) print('预测数据的精确率为:{:.4}%'.format( precision_score(y_test,y_pred)*100)) print('预测数据的召回率为:{:.4}%'.format( recall_score(y_test,y_pred)*100)) # print("训练数据的F1值为:", f1score_train) print('预测数据的F1值为:', f1_score(y_test,y_pred)) print('预测数据的Cohen’s Kappa系数为:', cohen_kappa_score(y_test,y_pred)) 二、分类报告def classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False) 该函数就是在进行了分类后,输入原始真实数据(y_true)和预测数据(y_pred)而得到分类报告,常常用来观察模型的好坏,如利用f1-score进行评判 # 打印分类报告 print('预测数据的分类报告为:',' ', classification_report(y_test,y_pred)) 使用 sklearn.metric.classification_report 工具对模型的测试结果进行评价时,会输出如下结果:(表格) 分为0/1两类0 precision recall f1-score support 0 0.99 1 0.99 155 1 0.90 0.82 0.86 11 accuracy 0.98 166 macro avg 0.94 0.91 0.92 166 weighted avg 0.98 0.98 0.98 166 类1: 召回率=1,精确率=0.99 说明,本类分类正确,其他类有错分到本类的情况 类2: 召回率 |
【本文地址】