| Pandas透视表大揭秘:从基础到高级技巧的完整指南 | 您所在的位置:网站首页 › 数据透视表常用函数 › Pandas透视表大揭秘:从基础到高级技巧的完整指南 |
Pandas透视表大揭秘:从基础到高级技巧的完整指南
|
👽发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 Pandas透视表大揭秘:从基础到高级技巧的完整指南在数据处理和分析中,Pandas是一个强大的Python库,提供了丰富的功能来处理和转换数据。其中,透视表(Pivot Table)是一项非常有用的功能,可以帮助我们轻松地对数据进行汇总和分析。在本文中,我们将深入探讨Pandas中的透视表基础,并通过实战案例演示如何使用pivot_table函数进行数据分析。
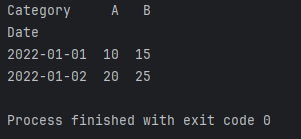
透视表是一种数据汇总工具,能够根据一个或多个键对数据进行聚合,形成一个新的表格。Pandas中的pivot_table函数是实现透视表功能的利器。让我们从基础开始,了解如何使用pivot_table函数。 1.1 pivot_table函数基础语法 import pandas as pd # 创建示例数据 data = {'Date': ['2022-01-01', '2022-01-01', '2022-01-02', '2022-01-02'], 'Category': ['A', 'B', 'A', 'B'], 'Value': [10, 15, 20, 25]} df = pd.DataFrame(data) # 使用pivot_table函数 pivot_result = pd.pivot_table(df, values='Value', index='Date', columns='Category', aggfunc='sum') print(pivot_result)上述代码中,我们首先创建了一个包含日期、类别和数值的示例数据框。然后,通过pivot_table函数,我们根据日期和类别对数值进行汇总,使用aggfunc参数指定了聚合函数(在这里使用了sum)。
现在,让我们通过一个实际案例来展示pivot_table函数的强大功能。假设我们有一份包含日期、产品类别和销售额的数据,我们想要分析每个产品类别在不同日期的销售情况。 2.1 实战代码 import pandas as pd # 创建销售数据示例 sales_data = {'Date': ['2022-01-01', '2022-01-01', '2022-01-02', '2022-01-02', '2022-01-01', '2022-01-02'], 'Category': ['A', 'B', 'A', 'B', 'A', 'B'], 'Sales': [100, 150, 200, 250, 120, 180]} sales_df = pd.DataFrame(sales_data) # 使用pivot_table进行销售数据分析 sales_pivot = pd.pivot_table(sales_df, values='Sales', index='Date', columns='Category', aggfunc='sum', fill_value=0) print(sales_pivot) 2.2 代码解析在这个案例中,我们首先创建了一个包含日期、产品类别和销售额的示例数据框。然后,通过pivot_table函数,我们将数据按日期和产品类别进行汇总,使用sum作为聚合函数,并使用fill_value参数填充缺失值为0。 3. 进阶应用:透视表的更多功能pivot_table函数不仅仅局限于基本的行列聚合,还支持更多高级功能,例如多层索引、自定义聚合函数等。下面通过一个案例来展示这些进阶应用。 3.1 多层透视表 # 多层透视表示例 multi_pivot = pd.pivot_table(sales_df, values='Sales', index=['Date', 'Category'], aggfunc='sum') print(multi_pivot)在这个例子中,我们将透视表的行索引设置为日期和产品类别的组合,实现了多层透视表。这有助于更细粒度地了解销售数据的分布情况。 3.2 自定义聚合函数 # 自定义聚合函数示例 def weighted_average(data): values = data['Sales'] weights = data['Quantity'] return (values * weights).sum() / weights.sum() custom_agg = pd.pivot_table(sales_df, values=['Sales'], index='Date', aggfunc={'Sales': weighted_average}) print(custom_agg)在这个案例中,我们定义了一个自定义聚合函数weighted_average,用于计算加权平均销售额。通过aggfunc参数,我们传递了一个字典,指定了每个列应该使用哪种聚合函数。 4. 数据可视化透视表的结果通常可以通过数据可视化进一步呈现。例如,可以使用Matplotlib或Seaborn库创建条形图、热力图等图表,更生动地展示数据分析的结果。 import matplotlib.pyplot as plt import seaborn as sns # 利用Seaborn绘制热力图 plt.figure(figsize=(10, 6)) sns.heatmap(sales_pivot, annot=True, cmap="YlGnBu", fmt=".0f", linewidths=.5) plt.title('Sales Heatmap by Date and Category') plt.show()这段代码使用Seaborn库创建了一个销售数据的热力图,直观地展示了不同日期和产品类别的销售额情况。 5. 处理缺失值和透视表参数详解在实际数据分析中,我们经常会遇到缺失值的情况。pivot_table函数允许我们通过fill_value参数来填充缺失值。同时,我们还可以通过margins参数添加行和列的总计信息。 5.1 缺失值处理 # 处理缺失值示例 sales_df.loc[2, 'Sales'] = None # 模拟缺失值 # 使用pivot_table处理缺失值 sales_pivot_fillna = pd.pivot_table(sales_df, values='Sales', index='Date', columns='Category', aggfunc='sum', fill_value=0) print(sales_pivot_fillna)在这个例子中,我们故意在数据中引入了一个缺失值,并通过fill_value=0参数将缺失值填充为0,确保透视表的计算不受影响。 5.2 添加总计信息 # 添加总计信息示例 sales_pivot_totals = pd.pivot_table(sales_df, values='Sales', index='Date', columns='Category', aggfunc='sum', fill_value=0, margins=True, margins_name='Total') print(sales_pivot_totals)通过设置margins=True,我们在透视表中添加了行和列的总计信息,并通过margins_name参数指定了总计的名称为’Total’。 7. 性能优化和更多实际场景在大规模数据集上使用透视表时,性能可能成为一个重要的考虑因素。Pandas提供了一些性能优化的选项,可以加速透视表的计算。 7.1 使用pd.crosstab替代pivot_table在某些情况下,使用pd.crosstab可能比pivot_table更快速。它专门用于计算交叉表,语法类似但更简单。 # 使用pd.crosstab替代pivot_table cross_tab_result = pd.crosstab(index=sales_df['Date'], columns=sales_df['Category'], values=sales_df['Sales'], aggfunc='sum', margins=True, margins_name='Total') print(cross_tab_result) 7.2 使用numpy加速计算当处理大规模数据时,通过使用numpy库的函数可以提高透视表的计算速度。 import numpy as np # 使用numpy加速计算 sales_pivot_numpy = pd.pivot_table(sales_df, values='Sales', index='Date', columns='Category', aggfunc=np.sum, fill_value=0) print(sales_pivot_numpy) 8. 实际场景应用透视表在实际场景中有广泛的应用,例如在销售、金融、医疗等领域。以下是一些可能的实际场景: 销售分析: 透视表可以用于分析不同产品在不同地区和时间的销售情况。财务报表: 透视表可用于生成财务报表,汇总不同账户或部门的收入和支出。医疗数据分析: 透视表可用于分析患者的医疗数据,了解不同病症的发病率和治疗效果。 10. 高级应用:透视表进阶技巧在数据分析的复杂场景中,透视表的进阶技巧变得尤为重要。本节将介绍一些高级应用和技巧,以更灵活地处理多维数据。 10.1 自定义筛选条件透视表允许我们根据自定义的筛选条件对数据进行过滤,以满足特定的分析需求。 # 自定义筛选条件示例 filtered_pivot = pd.pivot_table(sales_df, values='Sales', index='Date', columns='Category', aggfunc='sum', fill_value=0) # 仅保留销售额大于150的数据 filtered_pivot = filtered_pivot[filtered_pivot['A'] > 150] print(filtered_pivot)在这个例子中,我们在透视表的基础上添加了一个自定义的筛选条件,仅保留了销售额大于150的数据。 10.2 多表连接与透视表有时候,我们需要将多个数据表连接起来,然后进行透视分析。这可以通过使用merge函数实现。 # 多表连接与透视表示例 additional_data = {'Date': ['2022-01-01', '2022-01-02'], 'Holiday': ['New Year', 'Weekend']} additional_df = pd.DataFrame(additional_data) merged_df = pd.merge(sales_df, additional_df, on='Date', how='left') merged_pivot = pd.pivot_table(merged_df, values='Sales', index='Date', columns=['Category', 'Holiday'], aggfunc='sum', fill_value=0) print(merged_pivot)在这个案例中,我们将销售数据表和额外信息表通过Date字段进行左连接,然后在连接后的数据上进行透视分析,结合了两个数据表的信息。 11. 导出和保存透视表结果完成透视分析后,我们可能需要将结果导出保存供他人查看或进一步分析。 # 导出透视表结果示例 pivot_result.to_csv('pivot_result.csv') pivot_result.to_excel('pivot_result.xlsx', sheet_name='Sheet1')通过上述代码,我们可以将透视表的结果保存为CSV或Excel文件,以便后续使用或分享。 总结:通过本篇文章,我们全面探讨了Pandas中透视表的基础用法和高级应用技巧。从基础的语法结构出发,我们学习了pivot_table函数的基本用法,包括指定数值列、行索引、列索引以及聚合函数的选择。随后,我们深入了解了透视表的更多功能,包括处理缺失值、添加总计信息、使用numpy加速计算等。 在实战案例中,我们以销售数据分析为例,演示了透视表在实际业务场景中的应用。通过案例,我们展示了如何通过透视表清晰地汇总和分析数据,为决策提供有力支持。 进一步,我们探讨了性能优化、实际场景应用以及透视表的高级技巧。这些包括使用pd.crosstab替代pivot_table、使用numpy加速计算、自定义筛选条件、多表连接等。这些技巧使得透视表在处理大规模数据和复杂场景时更为灵活高效。 最后,我们介绍了如何导出和保存透视表的结果,以便后续分享和进一步利用。透视表的灵活性和功能丰富性使其成为数据分析中的重要工具,能够满足各种分析需求。 通过学习本文,读者将更全面地了解Pandas中透视表的应用,能够灵活运用透视表处理和分析数据,为数据科学和分析工作提供更多的工具和技巧。希望本文对读者在数据分析领域的学习和实践有所帮助。 |

【本文地址】