| 数据分析学习总结笔记09:文本分析 | 您所在的位置:网站首页 › 数据结构文本格式化 › 数据分析学习总结笔记09:文本分析 |
数据分析学习总结笔记09:文本分析
|
数据分析学习总结笔记09:文本分析
1 文本分析1.1 文本分析概述1.2 结构/非结构化数据1.3 文本数据特点1.4 自然语言处理——NLP1.5 文本挖掘的应用
2 文本分词2.1 英文分词——KNIME2.2 中文分词2.2.1 中文分词工具2.2.2 分词的方法2.2.3 中文分词实操——pynlpir2.2.3.1 pynlpir准备2.2.3.1 操作步骤
3 中文关键词提取3.1 关键词提取概述3.2 关键词提取方法3.2.1 TF-IDF3.2.2 TextRank
3.3 关键词提取实操——pynlpir
4 中文停用词过滤4.1 停用词概述4.2 停用词实操——pynlpir
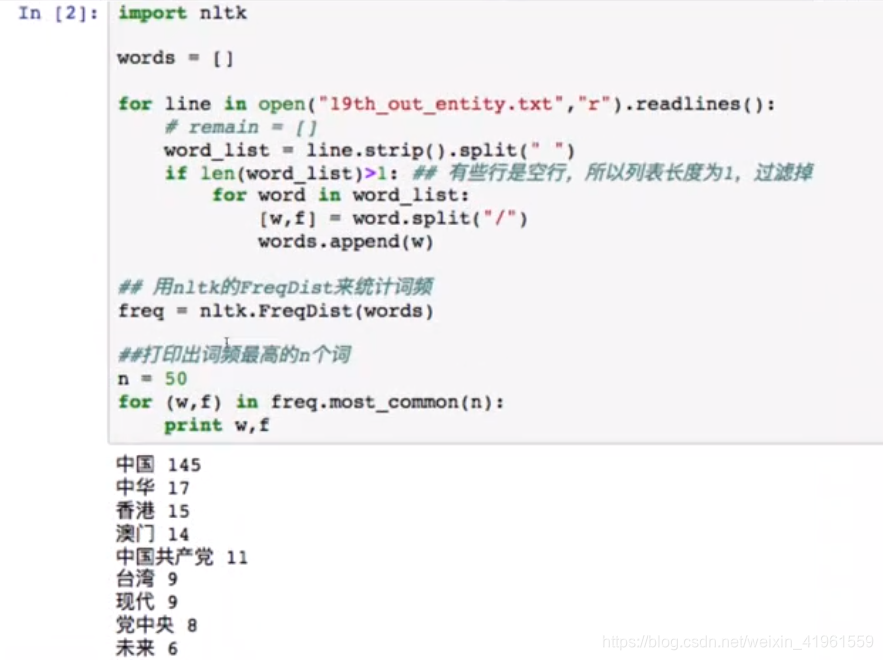
5 中文词频统计5.1 NLTK简介5.2 词频统计实操——NLTK
6 中文命名实体识别6.1 命名实体识别概述6.2 命名实体识别类型6.3 命名实体识别方法6.4 命名实体识别实操——pynlpir6.4.1 pynlpir实体分类结构6.4.2 pynlpir实操
1 文本分析
1.1 文本分析概述
文本分析是指对文本的表示及其特征项的选取;文本分析是文本挖掘、信息检索的一个基本问题,它把从文本中抽取出的特征词进行量化以表示文本信息1。 1.2 结构/非结构化数据 结构化数据:指的就是可以用二维表组织、分析处理过程较为明确的信息,可以将这种结构化的二维表组织方式理解为一个表格,表格里的每一个元素都被明确标记并很容易被识别。数字、符号等属于结构化数据。非结构化数据:指多种信息的无结构混合,通常无法直接知道或明确理解其内部结构,只有经过识别、有条理的存储分析后才能体现其结构化特征,通过文本挖掘,发现价值。文本、图片、声音、视频等属于非结构化数据。半结构化数据:介于结构化数据和非结构化数据两者之间的数据称为半结构化数据,大多数文本,既包含标题、作者、分类等结构字段,又包含非结构化的文字内容,这类文本均属于半结构化数据。如,新闻等。 1.3 文本数据特点(1)非结构化(非结构化数据占绝大部分) (2)海量数据 (3)高维稀疏性 (4)语义/情感 1.4 自然语言处理——NLP自然语言处理(Natural Language Processing,NPL)作为计算机科学领域与人工智能领域中的一个重要方向,是处理文本信息的一种重要手段。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。主要包括以下内容: 机器翻译自动摘要文本分类信息检索信息抽取自动问答情感分析…… 1.5 文本挖掘的应用 词频分析关键词提取语义网文本分类情感分析主题模型…… 2 文本分词分词,是将连续字符组成的语句按照一定规则划分成一个个独立词语的过程。 停用词:“This”,“that”,“的”、“地”、“啊”,……歧义词:我们需要有自主权→自主/主权未登录词:“喜大普奔”,“洪荒之力”,……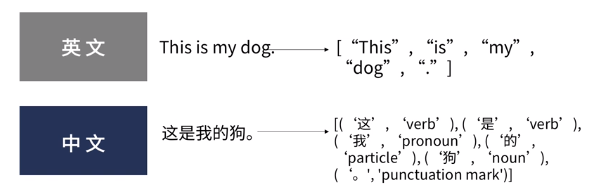 2.1 英文分词——KNIME
2.1 英文分词——KNIME
(1)软件官方下载地址:KNIME.org。 (2)推荐原因:开源;具有丰富的案例;支持多种语言(Python,R等)。 (3)处理步骤: 分词:去除标点符号→删除特定字符→英文大小写规范→去停用词→英文时态规范…… 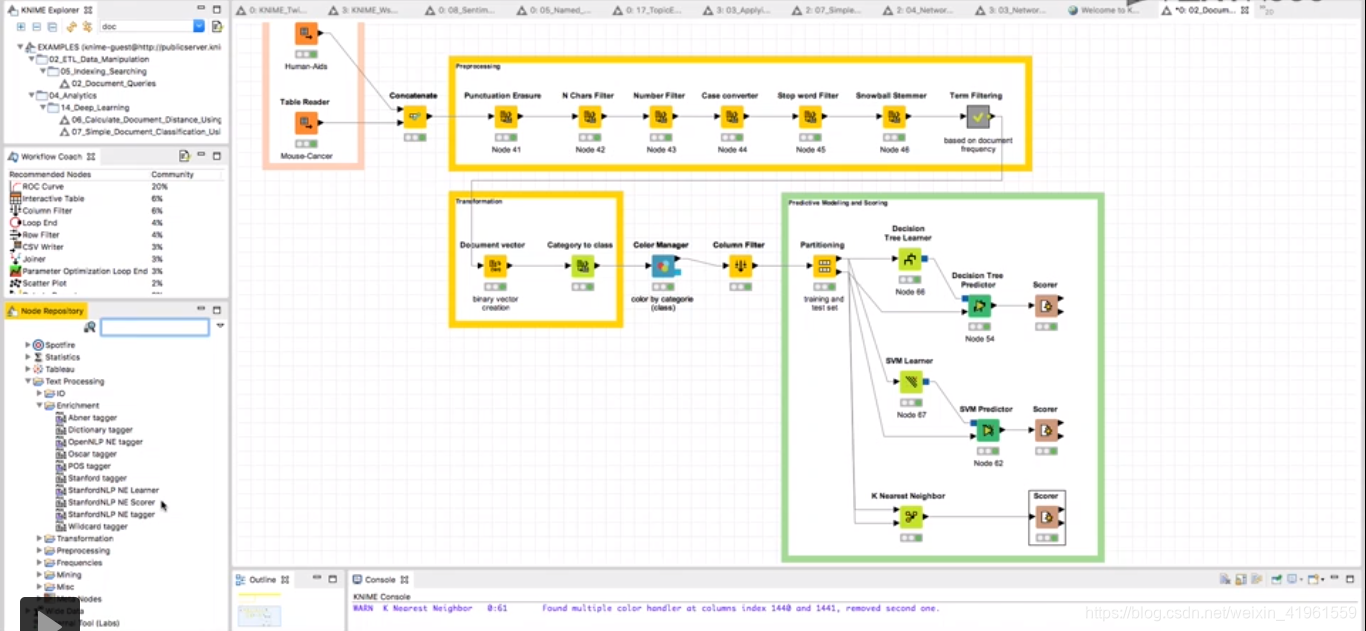 分词处理结果 分词处理结果 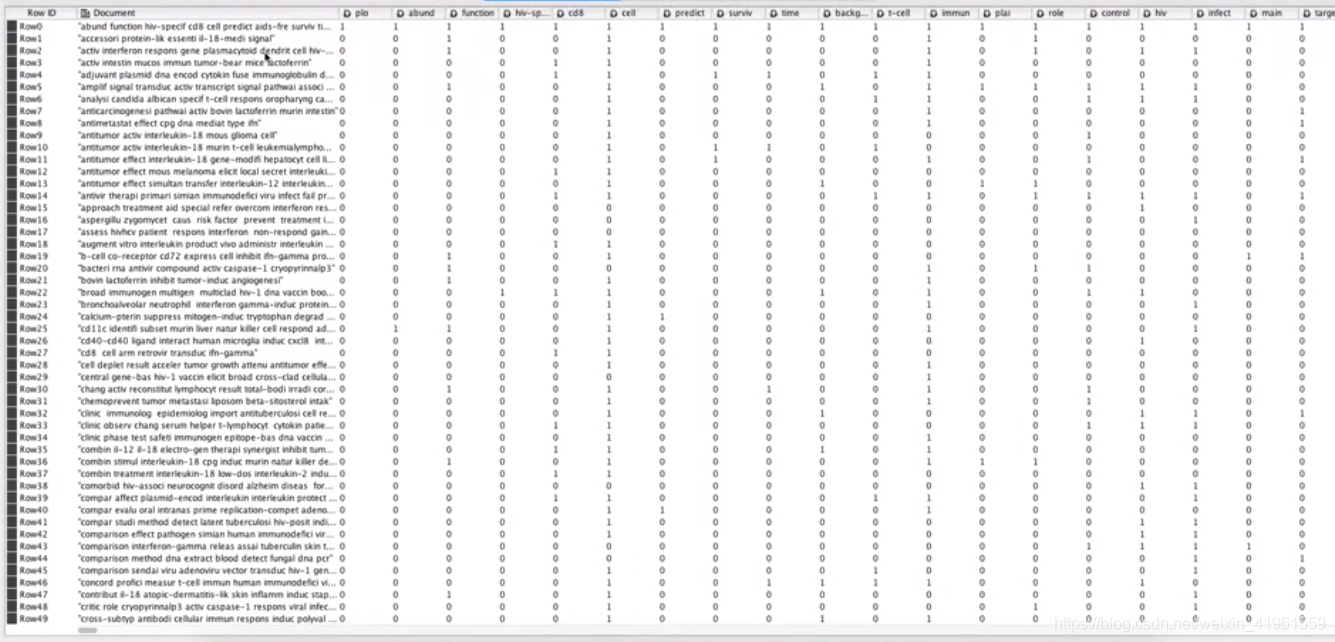 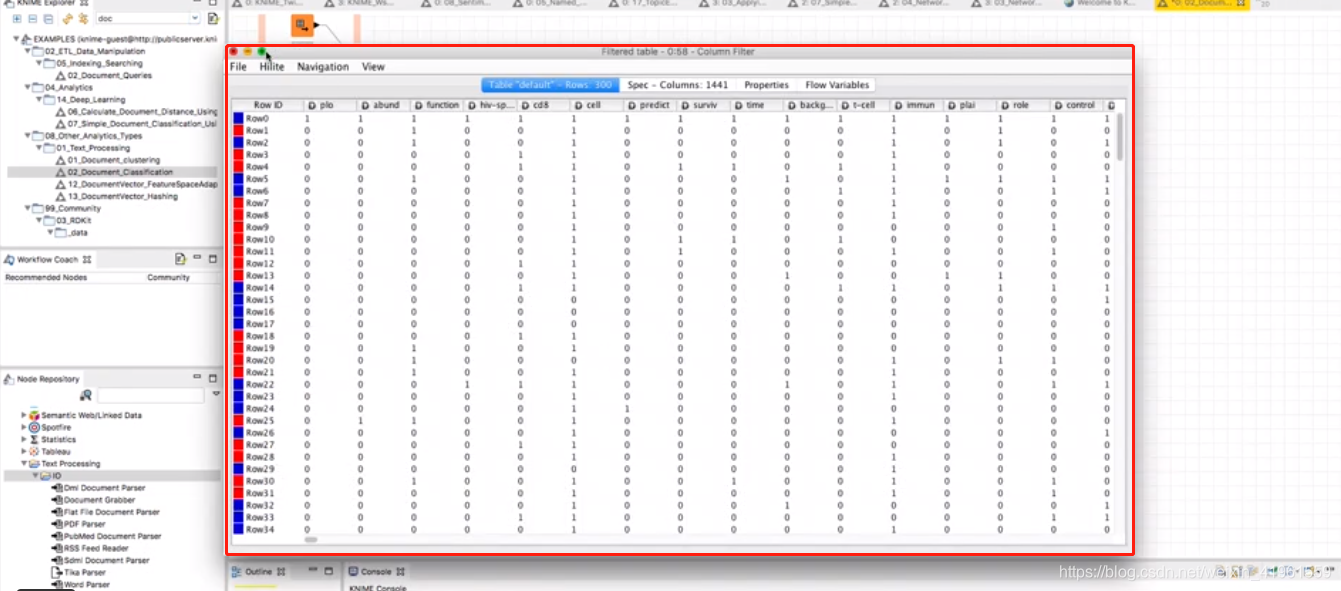 文本挖掘:分类(决策树,SVM支持向量机,K最近邻法)等
2.2 中文分词
2.2.1 中文分词工具
软件:NLPIR(ICTCLAS)、ROST、FudanNLP在线应用:SCWS、FudanNLP、LTP、NLPCN、Bosonnlp 文本挖掘:分类(决策树,SVM支持向量机,K最近邻法)等
2.2 中文分词
2.2.1 中文分词工具
软件:NLPIR(ICTCLAS)、ROST、FudanNLP在线应用:SCWS、FudanNLP、LTP、NLPCN、Bosonnlp  程序源码:LTP、CRF、smallseg、mmseg4j、盘古分词、Paoding、pynlpir、jieba、Rwordseg 程序源码:LTP、CRF、smallseg、mmseg4j、盘古分词、Paoding、pynlpir、jieba、Rwordseg  2.2.2 分词的方法
基于规则:指基于人工标注的词性和统计特征对中文语料进行训练,得到对每一个字的类别标注,根据标注结果来进行分词,同时通过模型计算各种分词结果出现的概率,将概率最大的分词结果作为最终结果。基于统计:关注文本本身的词项构成,其基本思想是字符串频数分析。分词过程:将文本中所有相邻汉子按照某一长度构成字符串,遍历所有字符串组合并统计其出现的频数,字符串出现的频数越高表明其为固定搭配词的可能性越大,设定某一频数阈值,超过阈值时则将该字符串换分为固定搭配词。基于词典:指应用词典匹配、汉语词法或其他汉语语言知识进行分词的方法,使用的词典可以是庞大的统一化词典,或者是分行业的垂直词典,如中科院开发的汉语语法分析系统ICTCLAS等。其基本分词原理是,在文本输入后,依据一定策略将待分析的文本与词典进行词项匹配,匹配成功则提取该词。
2.2.3 中文分词实操——pynlpir
2.2.3.1 pynlpir准备
简介:Pynlpir是对中文分词软件NLPIR/ICTCLAS做的Python封装,其本质是调用NLPIR/ICTCLAS的分词程序。项目地址:https://github.com/tsroten/pynlpir安装方法: (1)pip install pynlpir (2)python setup.py install调用方法: import pynlpir
2.2.3.1 操作步骤
2.2.2 分词的方法
基于规则:指基于人工标注的词性和统计特征对中文语料进行训练,得到对每一个字的类别标注,根据标注结果来进行分词,同时通过模型计算各种分词结果出现的概率,将概率最大的分词结果作为最终结果。基于统计:关注文本本身的词项构成,其基本思想是字符串频数分析。分词过程:将文本中所有相邻汉子按照某一长度构成字符串,遍历所有字符串组合并统计其出现的频数,字符串出现的频数越高表明其为固定搭配词的可能性越大,设定某一频数阈值,超过阈值时则将该字符串换分为固定搭配词。基于词典:指应用词典匹配、汉语词法或其他汉语语言知识进行分词的方法,使用的词典可以是庞大的统一化词典,或者是分行业的垂直词典,如中科院开发的汉语语法分析系统ICTCLAS等。其基本分词原理是,在文本输入后,依据一定策略将待分析的文本与词典进行词项匹配,匹配成功则提取该词。
2.2.3 中文分词实操——pynlpir
2.2.3.1 pynlpir准备
简介:Pynlpir是对中文分词软件NLPIR/ICTCLAS做的Python封装,其本质是调用NLPIR/ICTCLAS的分词程序。项目地址:https://github.com/tsroten/pynlpir安装方法: (1)pip install pynlpir (2)python setup.py install调用方法: import pynlpir
2.2.3.1 操作步骤
1. 分词 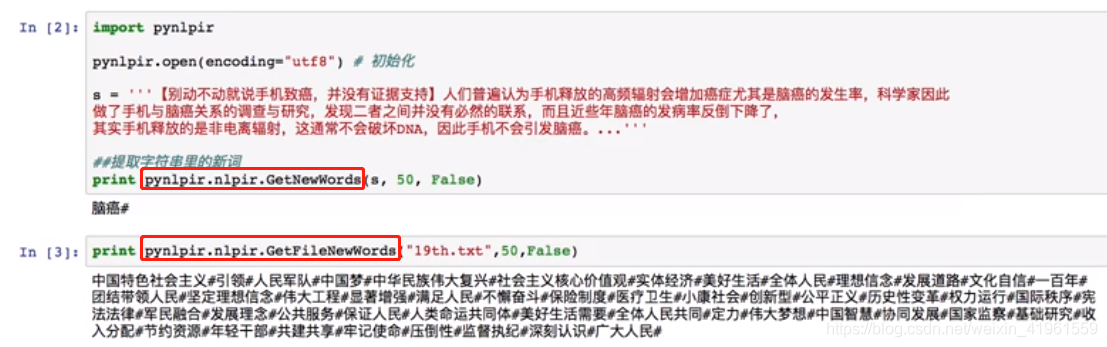 3. 添加用户词典 3. 添加用户词典 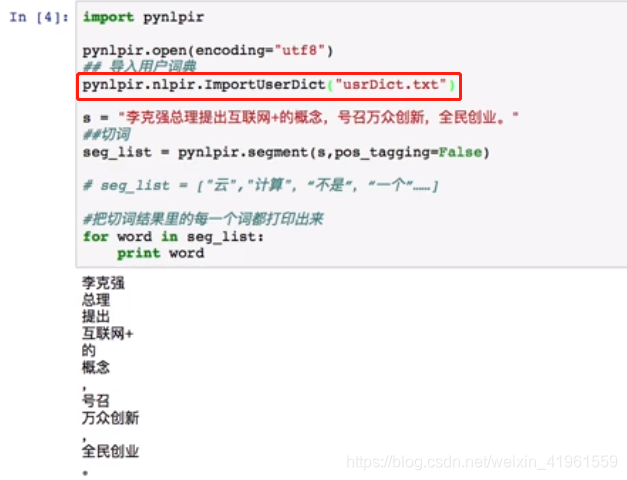 4. 文件分词 4. 文件分词 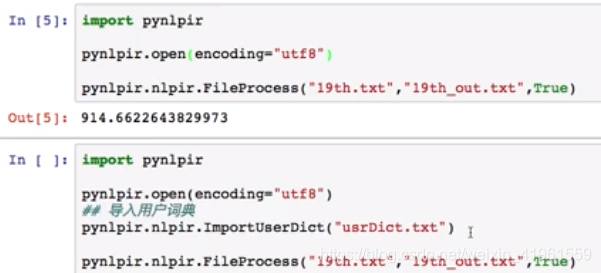 3 中文关键词提取
3.1 关键词提取概述
3 中文关键词提取
3.1 关键词提取概述
关键词提取就是从文本里面把跟这篇文章意义最相关的一些词抽取出来。最早可追溯到文献检索初期,目前依然需要在论文中使用关键词。 关键词在文本聚类、分类、摘要等领域发挥着重要作用。如,新闻关键词标签;淘宝评论标签;将某段时间中几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论些什么话题。 3.2 关键词提取方法 3.2.1 TF-IDFTF-IDF是一种用于信息检索与数据挖掘的常用加权技术,用以评估一字词对于一个文件集及或一个语料库中的其中一份文件的重要程度。 TF(Term Frequency)词频,某个词在文章中出现的次数或频率。如果某篇文章中的某个词出现多次,那这个词可能是比较重要的词。IDF(Inverse Document Frequency)逆文档频率,指词语“权重”的度量。在词频的基础上,如果一个词在多篇文档中词频较低,也就表示这是一个比较少见的词,但却在某一篇文章中出现了很多次,则这个词IDF值越大,在这篇文章中的“权重”越大。即,当一个词越常见,其IDF值越低。当计算出TF和IDF值后,两数相乘即为TF-IDF:某词的TF-IDF值越高,说明其在这篇文章中的重要性越高,越有可能是文章的关键词。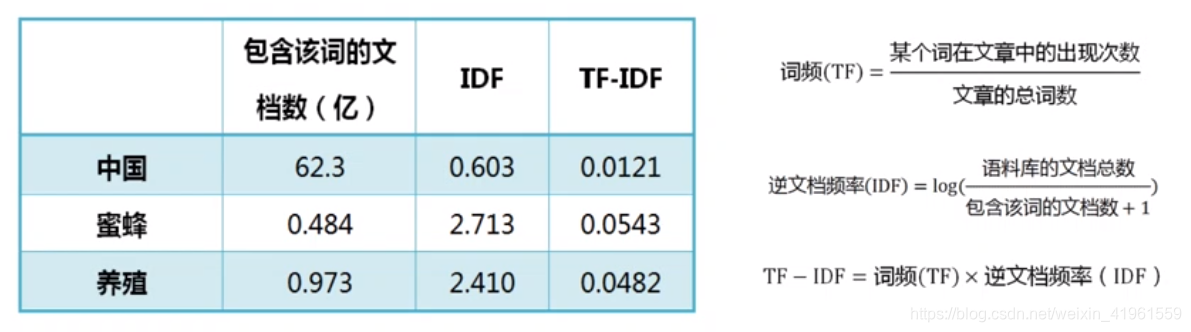 3.2.2 TextRank
3.2.2 TextRank
TextRank算法是一种用于文本的基于图的排序算法。 基本思想:来源于谷歌的PageRank算法,通过把文本分割成若干组成单元(单词、句子)并建立图模型,利用投票机制对文本中的重要成分进行排序。优点:不需要事先对多篇文档进行学习训练,仅利用单篇文档本身的信息即可实现关键词提取、文摘,因其简洁有效而得到广泛应用。PageRank: PageRank最开始用来计算网页的重要性。整个互联网可以看做一张有向图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页B指向网页A的有向边。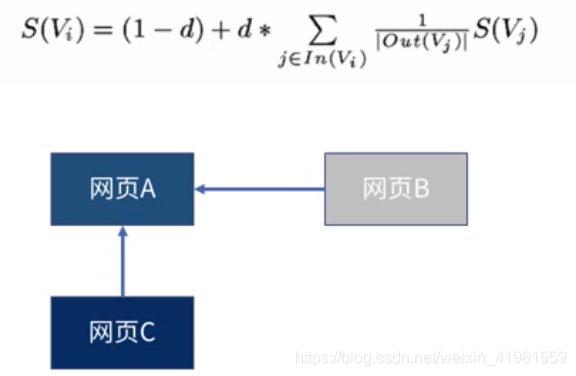 其中,S(Vi)是网页i的重要性(PR值),d是阻尼系数,一般设置为0.85,In(Vi)是存在指向网页i的链接的网页集合,Out(Vi)是网页j中的链接存在的链接指向网页的集合,|Out(Vi)|是集合中元素的个数。
3.3 关键词提取实操——pynlpir 其中,S(Vi)是网页i的重要性(PR值),d是阻尼系数,一般设置为0.85,In(Vi)是存在指向网页i的链接的网页集合,Out(Vi)是网页j中的链接存在的链接指向网页的集合,|Out(Vi)|是集合中元素的个数。
3.3 关键词提取实操——pynlpir
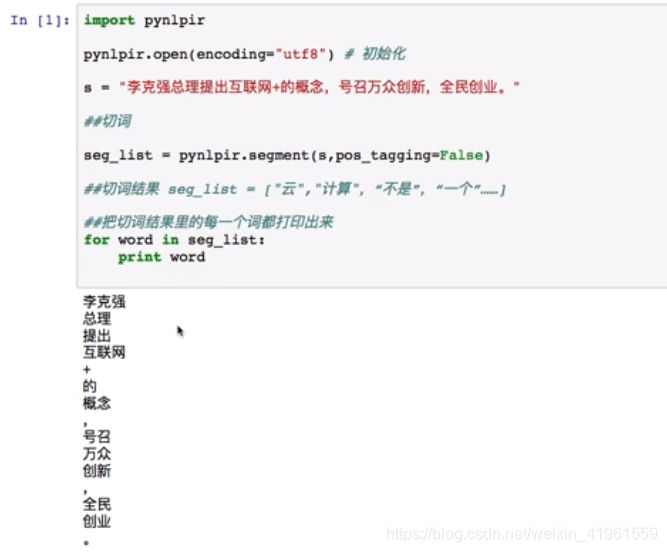
1. 提取关键词 停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。 这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的2。 4.2 停用词实操——pynlpir1. 过滤停用词 NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。 提供了易于使用的接口,通过这些接口可以访问超过50个语料库和词汇资源(如WordNet);用于分类、标记化、词干标记、解析和语义推理的文本处理库,以及工业级NLP库的封装器;活跃的讨论论坛。 5.2 词频统计实操——NLTK
命名实体识别(Named EntitiesRecognition,NER)指识别文中具有特定意义的实体,如人名、机构名、地名等专有名词和有意义的时间等,是信息检索、问答系统等技术的基础任务。 举例:《华尔街日报》报道称,苹果公司CEO库克声称中国也在首批预售名单中。 6.2 命名实体识别类型 模板元素任务(Template Element) 指提取文本中相关的命名实体,包括各种专有名词、时间表达式、数量表达式等。模板关系任务(Template Relation) 指提取命名实体之间的各种关系事实等。如,“Location of, Employee of, Product of”等关系。脚本模板任务(Scenario Template) 指提取指定的事件,包括参与这个事件的各个实体、属性或关系。 6.3 命名实体识别方法 隐马尔可夫模型(Hidden Markv Model, HMM)支持向量机(Supper Vector Machine, SVM)最大熵(Maximum Entropy, ME)条件随机场(Conditional Random Field, CRF) 6.4 命名实体识别实操——pynlpir 6.4.1 pynlpir实体分类结构 7个一级实体类型:人、职能、地点、产品、组织机构、数量、时间。32个二级实体类型。 6.4.2 pynlpir实操1. 显示词性 相关笔记: Python相关实用技巧01:安装Python库超实用方法,轻松告别失败!Python相关实用技巧02:Python2和Python3的区别Python相关实用技巧03:14个对数据科学最有用的Python库Python相关实用技巧04:网络爬虫之Scrapy框架及案例分析Python相关实用技巧05:yield关键字的使用Scrapy爬虫小技巧01:轻松获取cookiesScrapy爬虫小技巧02:HTTP status code is not handled or not allowed的解决方法数据分析学习总结笔记01:情感分析数据分析学习总结笔记02:聚类分析及其R语言实现数据分析学习总结笔记03:数据降维经典方法数据分析学习总结笔记04:异常值处理数据分析学习总结笔记05:缺失值分析及处理数据分析学习总结笔记06:T检验的原理和步骤数据分析学习总结笔记07:方差分析数据分析学习总结笔记07:回归分析概述数据分析学习总结笔记08:数据分类典型方法及其R语言实现数据分析学习总结笔记09:文本分析数据分析学习总结笔记10:网络分析本文主要根据个人学习(媒体大数据挖掘与案例实战MOOC),并搜集部分网络上的优质资源总结而成,如有不足之处敬请谅解,欢迎批评指正、交流学习! 媒体大数据挖掘与案例实战MOOC ↩︎ 停用词百度百科 ↩︎ |
 2. 发现新词
2. 发现新词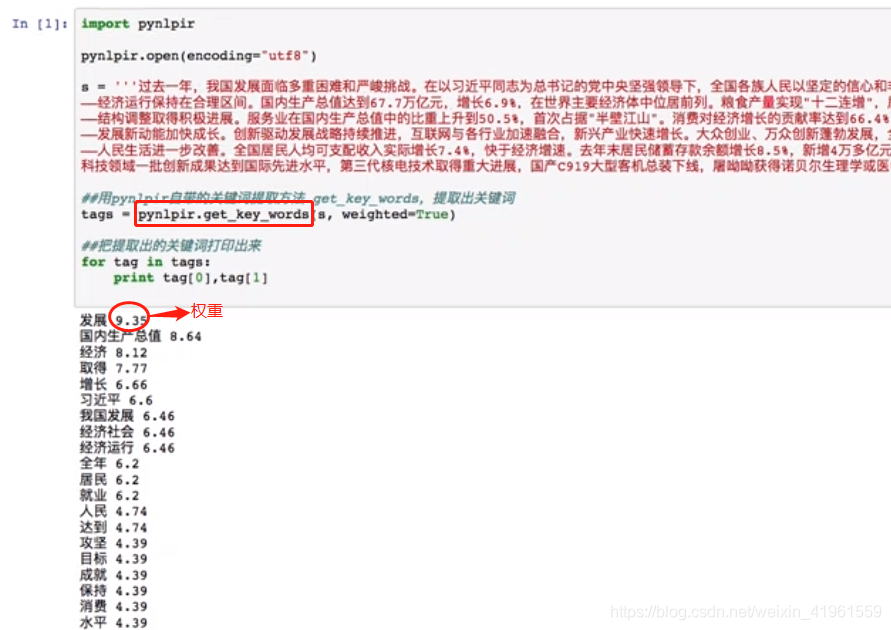 2. 抽取文件关键词
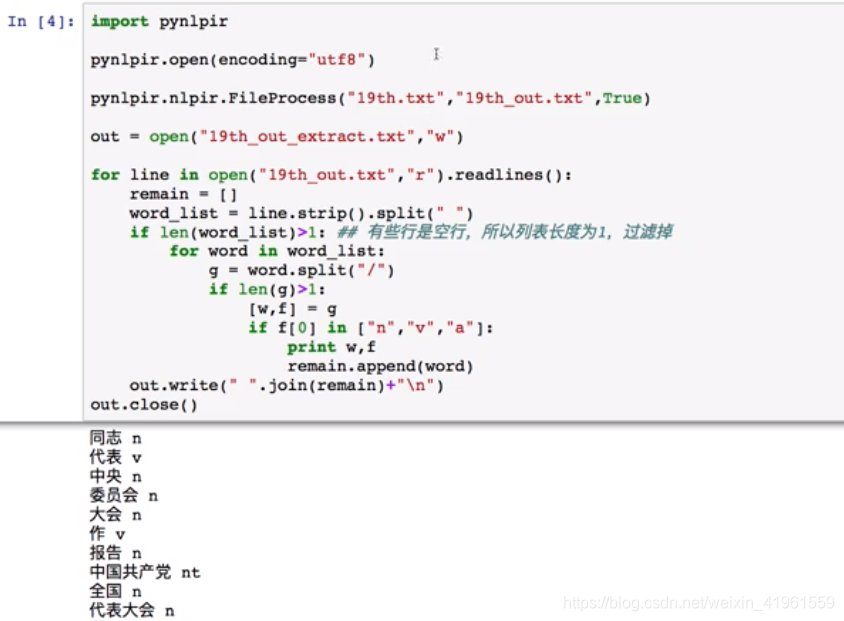
2. 抽取文件关键词 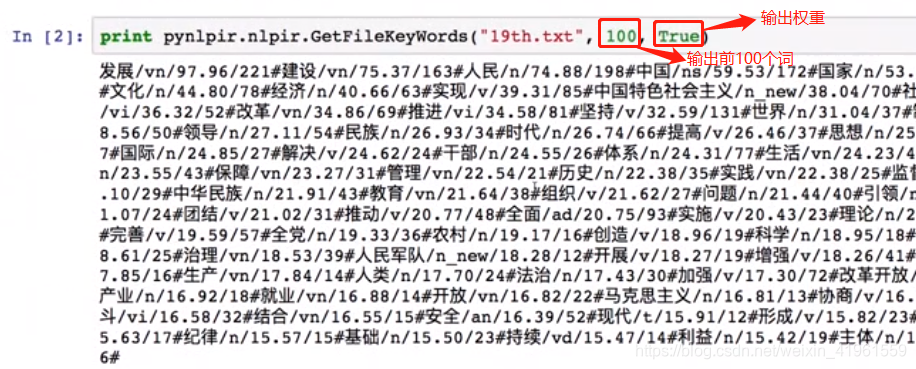 优化输出结果:
优化输出结果: 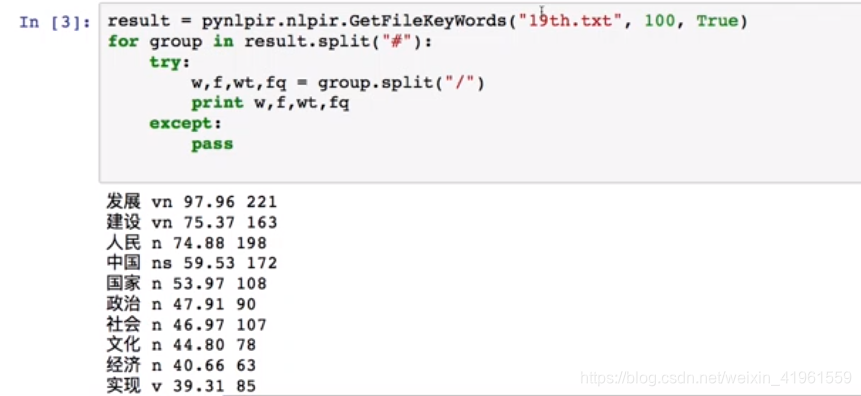
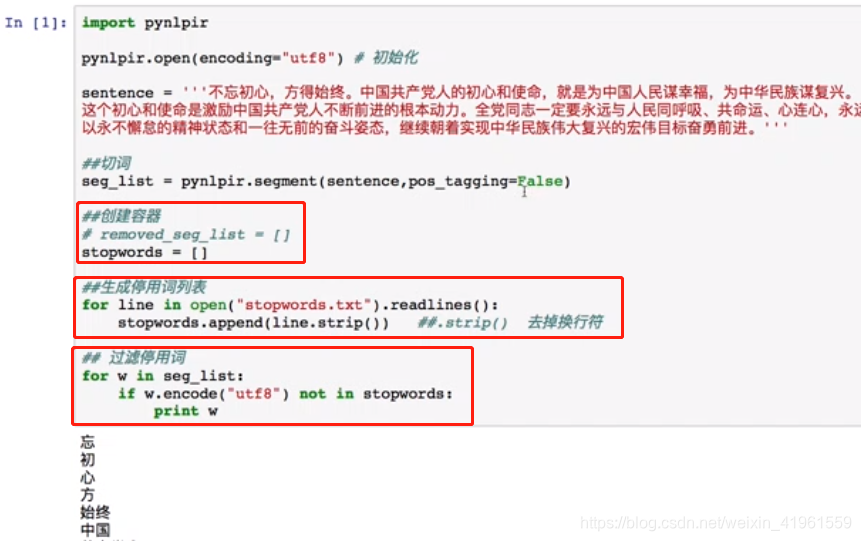 2. 文件过滤停用词
2. 文件过滤停用词 
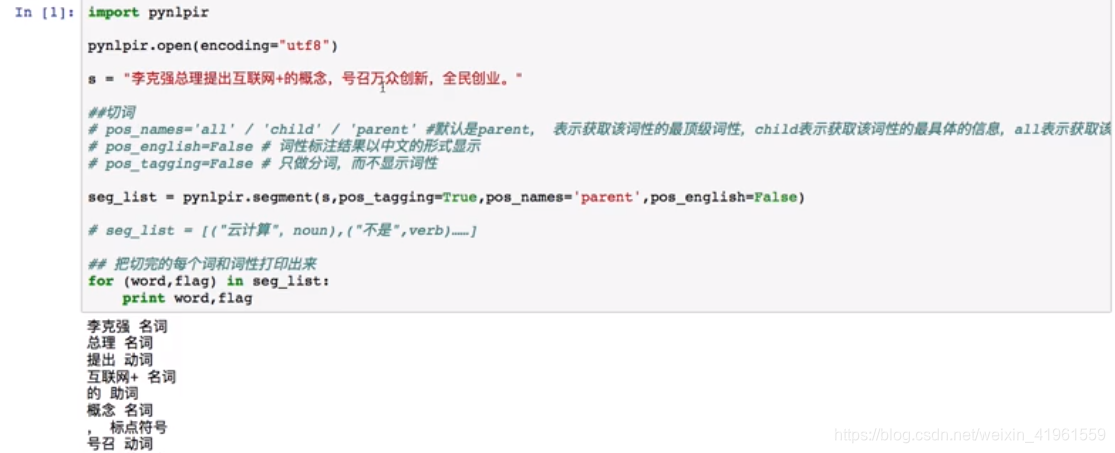 2. 提取特定词性
2. 提取特定词性 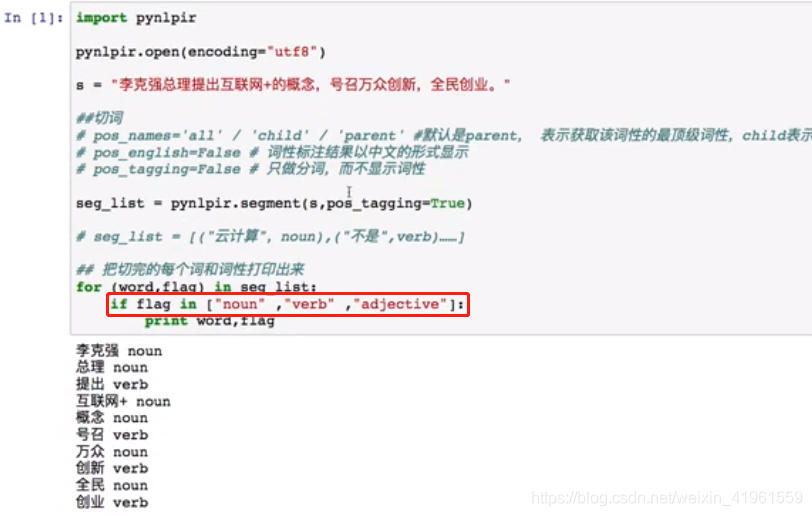 3. 提取命名实体
3. 提取命名实体  4. 文件的命名实体识别
4. 文件的命名实体识别 
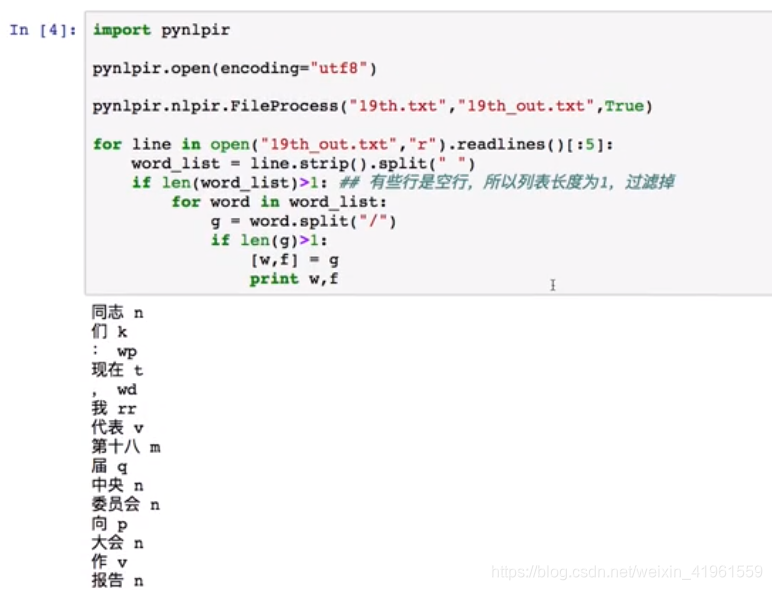
【本文地址】