| 数据挖掘(Data Mining)第七章课后习题 | 您所在的位置:网站首页 › 数据挖掘课后答案第二章 › 数据挖掘(Data Mining)第七章课后习题 |
数据挖掘(Data Mining)第七章课后习题
|
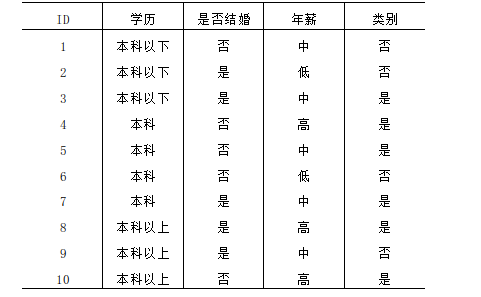
1、C4.5算法在构造决策树时使用的分裂属性是( 信息增益率 ) 2、以下两种描述分别对应的分类算法的评价标准是( Precision, Recall ) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 3、决策树中不包含的下列结点是( 外部结点(external node) ) 4、以下算法属于基于规则的分类器的是( C4.5 ) 5、以下关于随机森林算法的分析中错误的是( 在构建决策树的过程中需要剪枝 ) 6、下列哪些是分类与预测的不同之处( 分类的作用是构造一系列能描述和区分数据类型或概念的模型;预测是建立一个模型去预测缺失的或无效的并且通常是数字的数据值 ) 7、冗余属性的问题会影响决策树的准确率。( 错 ) 8、当一个数据对象同时属于多个类时,很难评估分类的准确率。通常在这种情况下,我们选择的分类器一般趋向于含有这样的特征:最小化计算开销,即使给予噪声数据或不完整数据也能准确预测,在大规模数据下仍然有效工作,提供简明易懂的结果。( 对 ) 9、分类规则的挖掘方法通常有:决策树法、贝叶斯法、人工神经网络法、粗糙集法和遗传算法。( 对 ) 10、决策树是用样本的属性作为树的结构,用样本属性的取值作为树分支的结点。( 错 ) 11、ID3算法无法避免过拟合问题,而C4.5算法则可以避免。( 错 ) 12、ID3算法在分裂节点处将信息增益作为分裂准则进行特征选择,递归地构建决策树。( 对 ) 13、为了避免决策树的欠拟合现象,提出随机森林算法。( 错 ) 14、下列是有关于是否投保的数据集,第二列至第四列为特征,表中最后一列类别代表是否投保,按照“年薪”进行划分的信息增益率为( 0.327 )
15、考虑下表中的数据集,使用贝叶斯分类预测记录X=(有房=否,婚姻状况=已婚,年收入=120k)的类标号( No )
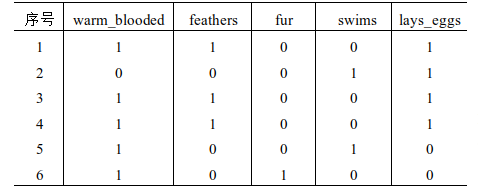
16、下表给出了一个关于动物类别的训练数据。数据集包含5个属性:warm_blooded、feathers、fur、swims、lays_eggs。 若样本按warm_blooded划分,对应的熵为( 0.809 )
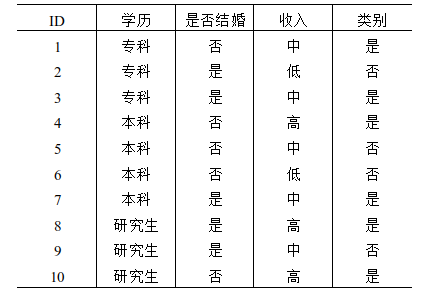
17、下列是有关于是否购买电脑的数据集,其中学历,是否结婚,收入为特征,表中最后一列类别代表是否购买电脑,则数据集的信息熵为( 0.971 )
18、决策树分类的主要包括( 对数据源进行OLAP, 得到训练集和测试集;对训练集进行训练;对初始决策树进行树剪枝;由所得到的决策树提取分类规则;使用测试数据集进行预测,评估决策树模型 ) 19、下列哪些是朴素贝叶斯分类的优缺点( 容易实现并在大多数情况下可以取得较好的结果;类条件独立在实际应用中缺乏准确性,因为变量之间经常存在依赖关系,这种依赖关系影响了朴素贝叶斯分类器的准确性 ) 20、贝叶斯信念网络(BBN)有哪些特点( 构造网络费时费力;对模型的过分问题非常鲁棒 ) 21、给定决策树,选项有:(1)将决策树转换成规则,然后对结果规则剪枝;(2)对决策树剪枝,然后将剪枝后的树转换成规则。相对于选项(1),选择(2)的优点是更能泛化规则。( 错 ) 22、给定数据集 D,具有 m 个属性和 |D| 个训练记录,决策树生长的计算时间最多为m×D ×log(|D|)。( 对 ) 23、朴素贝叶斯假设属性之间是相互独立的。( 对 ) 24、随机森林算法过程中只有一个随机过程,即每棵决策树的构建所需的特征是从整体特征集中随机选取的。( 错 ) 25、下表为两周内天气与外出购物的数据集,利用朴素贝叶斯分类预测天气情况为(天气=晴,温度=冷,湿度=高,风力=强)时的结果为不会外出购物。( 对 )
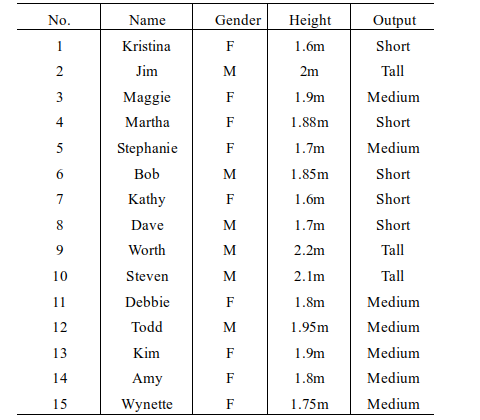
26、下面的例子被分为3类:{Short,Tall,Medium},Height属性被划分为(0,1.6),(1.6,1.7),(1.7,1.8),(1.8,1.9),(1.9,2.0),(2.0,∞),根据下表,对于t=用贝叶斯分类方法进行分类,则最终结果为( Tall )
27、分类模型的误差包括( 泛化误差 ) 28、下面的数据集包含两个属性X和Y,两个类标号"+"和"-"。每个属性取三个不同的值: 0, 1或2。"+"类的概念是Y=1, "-"类的概念是X=0或X=2。则由表构建的决策树的F1值(对"+"类定义)是( 0.5 )
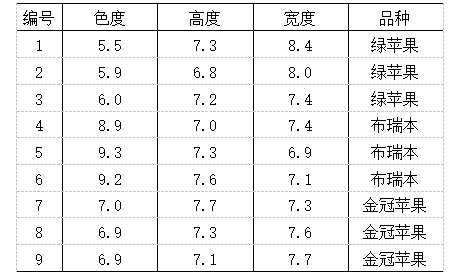
29、支持向量机模型包括( 线性可分支持向量机;线性支持向量机;非线性支持向量机 ) 30、贝叶斯信念网络(BBN)有哪些特点( 构造网络费时费力;对模型的过分问题非常鲁棒 ) 31、当一个数据对象同时属于多个类时,很难评估分类的准确率。通常在这种情况下,我们选择的分类器一般趋向于含有这样的特征:最小化计算开销,即使给予噪声数据或不完整数据也能准确预测,在大规模数据下仍然有效工作,提供简明易懂的结果。( 对 ) 32、用于分类的离散化方法之间的根本区别在于是否使用类信息。( 对 ) 33、对于SVM分类算法,待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果没有影响。( 对 ) 34、分类和回归都可用于预测,两者的区别在于分类的输出是离散的类别值,而回归的输出是连续数值。( 对 ) 35、逻辑回归算法属于回归算法。( 错 ) 36、随机森林算法过程中只有一个随机过程,即每棵决策树的构建所需的特征是从整体特征集中随机选取的。( 错 ) 37、某苹果数据集如下所示, K近邻分类法(K取3)对(色度=8.8,高度=7.1,宽度=7.0)的苹果进行分类的结果为( 布瑞本 )
38、考虑下表中的一维数据集,根据 1-最近邻、3-最近邻、5-最近邻、9-最近邻,对数据点 x=5.0分类,使用多数表决( +、-、+、- )
39、下面的例子被分为3类:{Short,Tall,Medium},Height属性被划分为(0,1.6),(1.6,1.7),(1.7,1.8),(1.8,1.9),(1.9,2.0),(2.0,∞),根据下表,对于t=用贝叶斯分类方法进行分类,则最终结果为( Tall )
40、某二分类问题的训练样本如下表所示,由此计算得的属性类别的Gini指标值为( 0.48 )
41、以下关于随机森林算法的分析中错误的是( 在构建决策树的过程中需要剪枝 ) 42、KNN的主要思想是计算每个训练数据(每个训练数据都有一个唯一的类别标识)到待分类元祖的距离,取和待分类元祖距离最近的k个训练数据集,k个数据中哪个类别的训练数据占多数,则待分类元祖就属于那个类别。( 对 ) 43、用于分类的离散化方法之间的根本区别在于是否使用类信息。( 对 ) 44、对于SVM分类算法,待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果没有影响。( 对 ) 45、分类和回归都可用于预测,两者的区别在于分类的输出是离散的类别值,而回归的输出是连续数值。( 对 ) 46、惰性学习法的“惰性”体现在它不急于在收到测试对象之前构造分类模型。( 对 ) 47、K近邻算法中K的取值对结果不会产生较大的影响。( 错 ) 48、随着训练对象数量趋向无穷,如果K同时也趋向无穷,K近邻分类器的错误率会渐进收敛到贝叶斯错误率。( 对 ) |





【本文地址】