| 四、数据挖掘中常见的挖掘模式 | 您所在的位置:网站首页 › 数据挖掘关键技术都有哪些 › 四、数据挖掘中常见的挖掘模式 |
四、数据挖掘中常见的挖掘模式
|
1.数据挖掘的模式
数据挖掘功能用于指定数据挖掘任务发现的模式:一般而言,这些任务可以分为两类:描述性和预测性。描述性挖掘任务刻画目标数据中数据的一般性质。预测性挖掘任务在当前数据上进行归纳,以便做出预测。数据挖掘的功能和模式主要包括以下内容: 特征化和区分频繁模式、关联和相关性分析挖掘分类与回归聚类分析离群点分析 2 类/概念:特征化和区分 数据可以与类或概念相关联,可以通过下述方法得到: 数据特征化:汇总所研究类(通常称为目标类)的数据;数据区分:将目标类与一个或多个可比较类(通常称为对比类)进行比较。 顾客的概念包括bigSpenders和budgetSpenders,这种汇总的、简洁的、精确的描述方式就就为类/概念描述。 数据特征化的方法 数据特征化(data characterization)通过查询来收集对应于用户指定类的数据。例如,挖掘任务“汇总一年内在某商店花费5000美元以上的顾客特征”,统计结果可能是顾客的概况,如年龄在40~50、有工作、有很好的信用等级。数据特征化的输出 可以用多种形式提供,例如饼图、条图、曲线、多维数据立方体和包括交叉表在内的多维表。结果描述可以用广义关系或规则(称作特征规则)形式提供。数据区分 数据区分(data discrimination)是将目标类数据对象的一般特性与一个或多个对比类对象的一般性进行比较。目标类和对比类可以用户指定,而对应的数据对象可以通过数据库查询检索。 例如,比较两组顾客——定期购买计算机产品的顾客和不经常购买这种产品的顾客。结果描述提供这些顾客比较的概况,例如频繁购买计算机产品的顾客80%在20-40岁之间,受过大学教育;而不经常购买这些产品的顾客60%或者年龄太大或太年轻或没有大学学位。 3 关联分析频繁模式 频繁模式(frequent pattern)是在数据中频繁出现的模式,存在多种类型的频繁模式,包括频繁项集、频繁子序列(序列模式)和频繁子结构。 频繁项集 频繁项集一般是指频繁地在事务数据中一起出现的商品的集合,如小卖部中被许多顾客频繁一起购买的牛奶和面包。 频繁子序列 类似如顾客倾向于先购买便携机,再购买数码相机,然后再购买内存卡这样的模式。 关联和相关性 关联分析又称关联挖掘,就是在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。 用于预测的分类 分类是这样的过程,它找出描述和区分数据类或概念的模型(函数),以便能够使用模型预测类标号未知的对象的类标号。 聚类分析 聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。 聚类分析和和分类的区别在于分类又已知的类别标签,而聚类没有。 数据集中可能存在一些数据对象,他们与数据的一般行为或模型不一致,这些数据对象被称为离群点(outlier)。大部分数据挖掘方法将离群点视为噪音或异常而丢弃。然而,在一些应用中(如欺诈检测),罕见的事件可能比正常出现的事件更令人感兴趣。 |
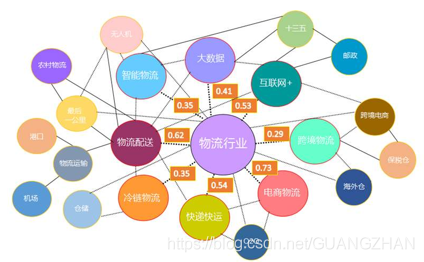
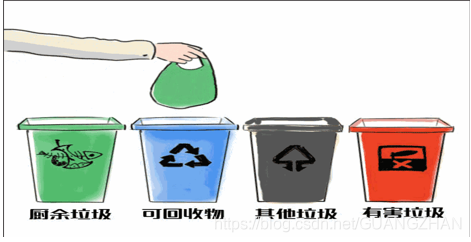 用于预测的回归 回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
用于预测的回归 回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。 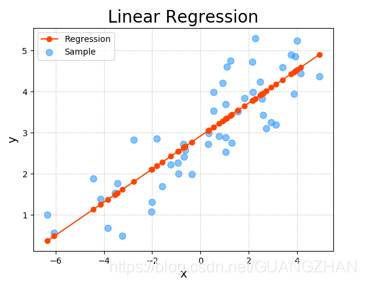
【本文地址】
公司简介
联系我们