| 大型数据仓库缩容、扩容及数据重分布方案 | 您所在的位置:网站首页 › 数据库迁移详细实施方案模板 › 大型数据仓库缩容、扩容及数据重分布方案 |
大型数据仓库缩容、扩容及数据重分布方案
|
引子:我们时常讲”我们要把阿里巴巴最佳实践和行业业务结合为客户做数字化转型“,本文涉及的案例就是这个方向的实践。 1. 背景介绍1.1 产品扩缩容功能 众所周知,很多公司的数据仓库是构建在MPP架构(大规模并行计算,Massive Parallel Processing)的数据库之上。MPP架构特征:任务并行执行;数据以分布键分布式存储(本地化);分布式计算;横向扩展,支持集群节点的扩容;Shared Nothing(完全无共享)架构。大致架构图如下 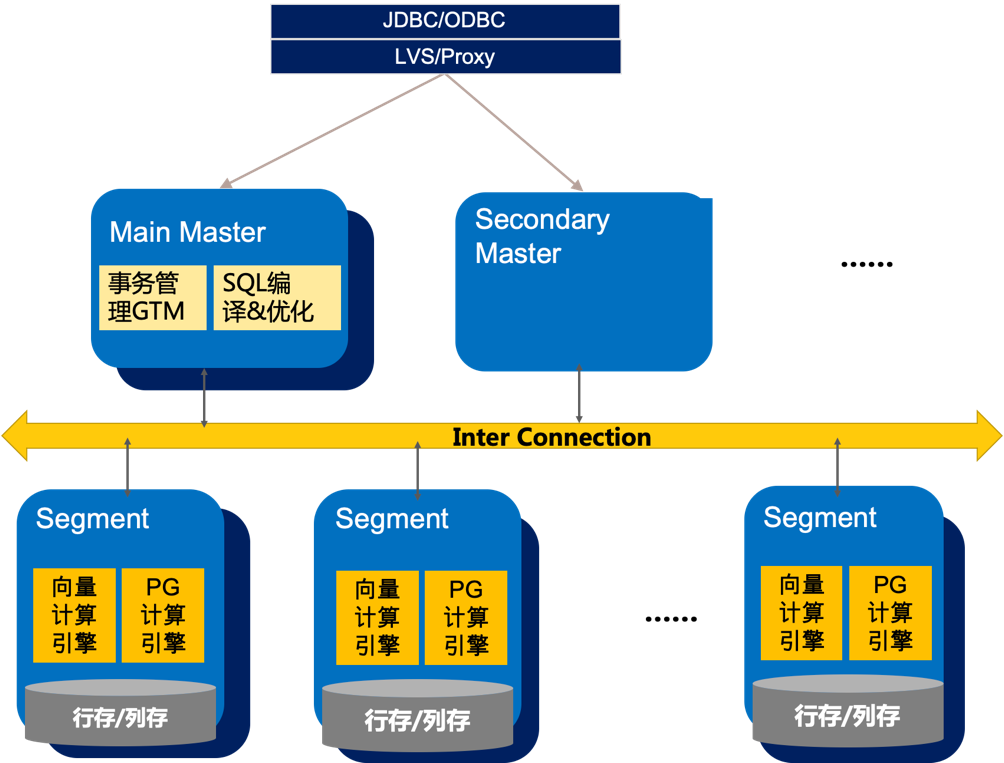
图1:ADB PG的MPP架构示意图 从以上特征可以看出,MPP架构的数据库如果遇到容量不足,通常是走Scale Out的扩容,即在计算节点层面增加服务器并部署Segment。由于数据是本地化存储在各个Segment上,新增加的Segment如果要均衡承载数据和计算,势必涉及已经在原集群“均衡分布”的数据,需要resharding,即数据重分布。 因此,扩(缩)容和数据重分布是MPP数据库普遍存在的运维管理操作。弹性伸缩本身也是云原生数仓的卖点之一,我们的ADB PG也实现了弹性伸缩,但大型数据仓库的扩容往往不能完全交给自动化任务,为什么呢?本文就一个SKA客户的扩容方案进行说明。 1.2 案例场景 本文的案例介绍缩容、扩容、数据重分布的方案,是3个大步骤的方案组合。客户的DBstack集群上有5个实例,扩容的原因是实例5的空间不足。实例5承载最大的数据仓库,扩容前数据360T,上线前还有40T的额外空间需求,如果空间不能扩大,业务无法上线!由于是新业务带来的空间需求,那只有扩容这条路了。 扩容前需要缩容的原因是客户已经没有空闲服务器了(即便客户有空闲服务器,也会有license限制,这是商务问题,也比较难解),只能释放部分实例的服务器资源给实例5;经过评估,实例5需要扩容N台服务器,实例1-4的资源消耗不高,可以合并这4个实例,实现服务器缩容,释放服务器资源给实例5。 缩容也有两种方式:一是每个实例缩容部分机器,达到实例5的N台机器扩容需求;二是直接释放某个完整实例的机器资源。经过评估,我们认为方式一太复杂、可行性较低,选择了方式二:把实例1按databse级别拆分后合并到实例2-4,所以实例1在整个DBstack集群中相当于做一次缩容,把机器资源释放出来再扩容到实例5。所以整个案例是先缩容再扩容。 2. 整体实施方案2.1 方案概览 如上所述,该案例的方案分3个大阶段:缩容(实例1拆分和迁移、释放服务器资源),扩容服务器,数据重分布。大致的示意图如下: 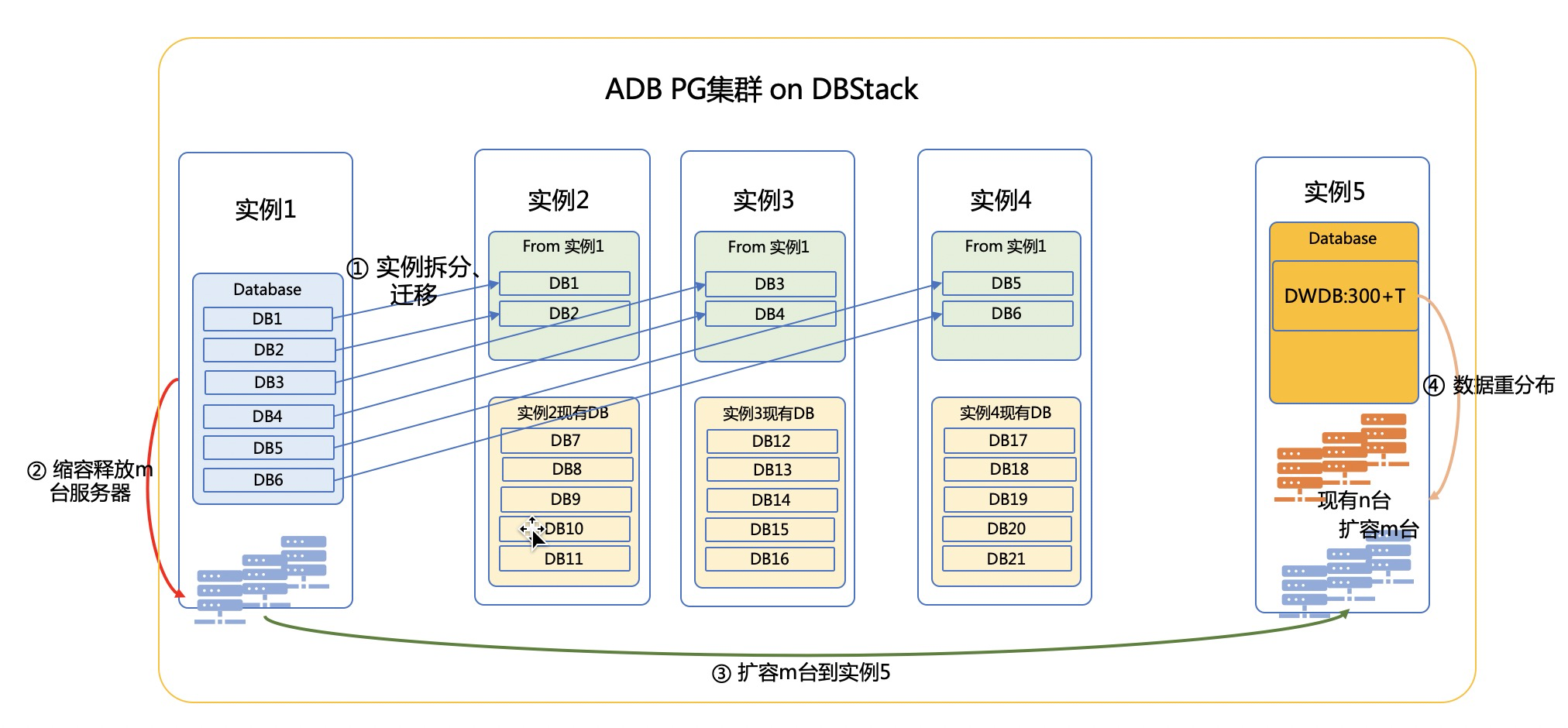
图2:整体方案示意图 2.2 方案执行计划 由于ADB PG承载了生产数据集市和数仓业务,而整个实施方案比较复杂,涉及的库较多,有大有小,为了保证不影响业务,我们大致按照“灰度发布”的策略步步为营。每个大的方案先试点小库或小表的实施,通过实施把该踩的坑填平,业务稳定后,再扩大到其他库表。整体方案实施历时2个月,计划执行情况如下图: 
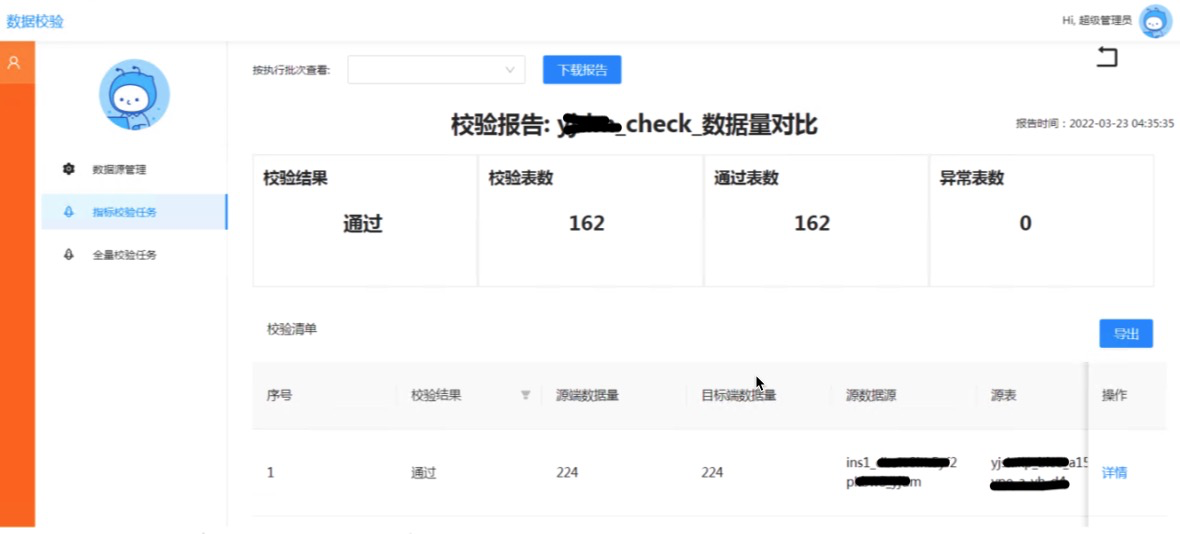
图3:整体实施计划执行图 下面我们按照前后逻辑关系,详细讲述下方案。 3. 缩容方案缩容的第一步是做实例合并,实例合并就必须要做数据库的迁移。大型数据仓库,每个库基本都10T起;数据集市也在1T以上,因此,数据迁移方案选型非常重要! 3.1 数据库迁移方案选型 跨ADBPG实例的数据库迁移的方式,有如下几种常见的数方案: pg_dump + pg_restore, GPTransfer, GPcopy,数据导出OSS再导入、DTS等方案,详细对比如下: 表1:数据库迁移方案选型 编号 方式 优势 劣势 最佳实践 1 pg_dump + pg_restore ①原生的备份恢复方式,最稳定; ②操作简单,不需要过多集群间配置 ③表结构迁移非常方便 ① 导出和导入都需要过adb的master,master会成为性能瓶颈; ② 速度慢,导出大概200MB/s, 导入大概50MB/s左右; alter resource group user_group_1 set CPU_RATE_LIMIT 15; psql> alter resource group user_group_1 set memory_limit 15; ● (2). 在目标实例2创建租户new_pro_group1 -- 这里只给基本的资源保障,迁移完成后按照最终的生产规划再做一次调整 CREATE RESOURCE GROUP new_pro_group1 WITH (CPU_RATE_LIMIT=5,memory_limit=5, concurrent=20,MEMORY_SHARED_QUOTA=40);● (3). 从实例1迁移用户到目标实例2 pg_dumpall --roles-only -f role.sql #生成后筛选role.sql中对应租户去实例2执行创建用户3.2.4 迁移表结构 首先建表就需要先建database;由于数仓或数据集市,肯定有分区表。而gptransfer迁移分区表时,需要提前建好子分区,因此建议整个库(比如图1的db1)的所有表结构,都通过pg_dump先导出,再导入目标实例。 ● 1. 在目标实例2创建数据库db1 ● 2. 迁移表结构 #源端导出 ~ pg_dump -Uadbpgadmin -w -p3013 -d db1 -s -Fp -f db1.sql #目标端导入 ~ psql -Uadbpgadmin -w -p3013 -d db1 -f db1.sql3.2.5 GPtransfer迁移数据 迁移注意点 ● gptransfer不擅长迁移大量的小表和空表。空表太多,要采取业务上删除空表再到目标库创建的方式;小表太多,就用pg_dump单独迁移小表的方式。 ● gptransfer发现目标库有表,有几种模式:skip (直接跳过迁移数据)或 truncate(先截断表清理数据) 由于我们的方案是先建表,因此肯定不能跳过迁移,选择truncate(命令选项--truncate) ● 外键存在导致表同步时truncate 失败 1. 迁移前drop外键 ALTER TABLE ONLY schema1.special_table_name drop CONSTRAINT fk_xxxxx;外键可以通过视图查询,或者直接从dump出的表结构sql文件中根据“FOREIGN ”筛选出来。 2. 正式迁移数据 gptransfer -a --base-port=9000 --source-host=source_hostname --source-user=adbpgadmin --source-port=3013 -d db1 --dest-host=dest_hostname --dest-port=3011 --dest-user=adbpgadmin --truncate --batch-size=5 --sub-batch-size=25 --max-gpfdist-instances=4 --work-base-dir=/home/adbpgadmin/db1 --source-map-file=/home/adbpgadmin/db1/gptransfer.conf --validate=count --no-final-count --timeout=600 --max-line-length=268435456 -l /home/adbpgadmin/db1/trans_log注意:-a选项是关闭交互;-d 指定数据库;gptransfer.conf配置所有目标实例的segment的IP映射关系,配置形式IP,IP 10.xx.xx.1,10.xx.xx.1 #文中所有IP都是虚构的 这里和开源GreenPlum有区别,开源GP是配置IP,hostname3.查看迁移进度 #执行gptransfer时-l选项指定了日志目录,可以进去查看即可 ~ tail -f /home/adbpgadmin/db1/trans_log/gptransfer_{date}.log整体迁移速度大概是600MB/s。 3.2.6 数据稽核 数据迁移后,源库和目标库一定要做数据稽核。对于数仓的校验,我们一般使用全量count+指标校验的方法结合。使用工具可以大大提效。我们建议使用KOC-数据稽核工具(名字:青天鉴),它是一个支持多源异构数据源的数据校验工具组件,适用于解决数据迁移前后数据一致性校验的问题。目前已经支持MySQL、Oracle、DB2、SQL_SERVER、ODPS、OB(MySQL), ADB(PG)之间的互相校验。
图5:KOC稽核结果示意图 3.2.7 恢复配置 配置恢复千万别忘,涉及pg_hba白名单、租户资源、超级用户连接数,上文已提及,这方法就不赘述了。 3.2.8 业务验证 数据库迁移和稽核完成后,业务割接到新库,并进行验证。 3.3 集群缩容-实例释放 实例释放,通过DBStack控制台上的实例释放功能即可。实例释放后,宿主机会重新回到DBStack集群的服务器资源池。通过控制台的“主机列表”查看主机资源使用情况,可以确认实例释放是否成功。如下图,只要实例1所在的服务器,显示实例数=0,且状态=开启分配,则表示实例释放成功。 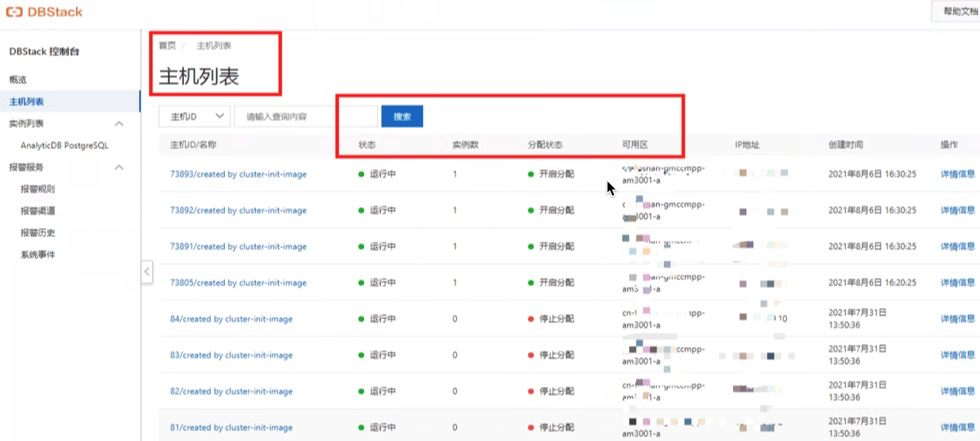
图6:DBStack的机器资源列表 以上,对于实例1-4的缩容实施就完成了。后续的扩容是针对另一个实例进行。 4. 扩容方案DBStack有服务器资源,就可以通过控制台对实例5进行扩容了。 4.1 精确指定服务器 在DBStack控制台的主机列表中,可以把不希望调度的服务器,修改状态为禁止分配,只保留期望的服务器列表。 4.2 扩容segment 在实例详情页点击新增计算节点,页面上的计算组一般就是服务器数量,每个计算组包含多个segment节点(kubernetes的Pod);如果扩容8台机器,选择扩容后的计算组数量(假如目前52,最终计算组加到60)为60,提交确认,便自动开始扩容。数据重分布时间选择“立即执行”即可。 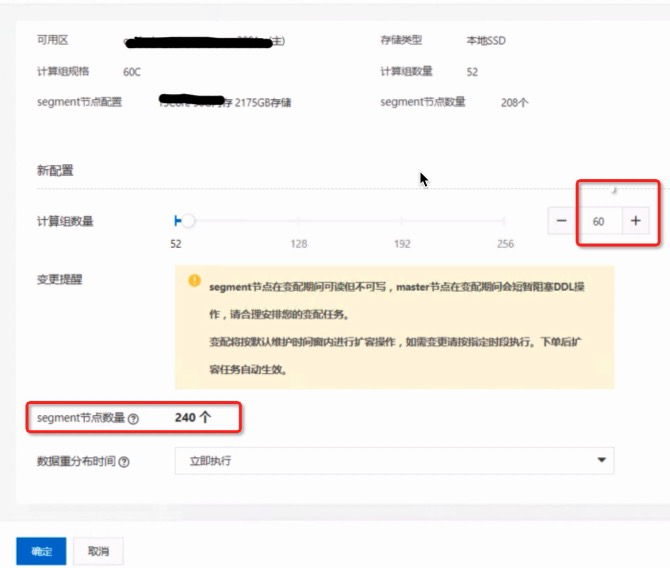
图7:扩容功能界面 产品扩容实现的逻辑 ● 准备新节点 i. lock catalog ii. pg_basebackup准备模板 ===> 具备相同元数据 iii. 从master节点复制文件(configureation files)到新主机 iv. 在新主机使用模板与配置文件启动新节点 v. 清理模板文件 ● 新节点加入集群 i. 更新gp_segment_configuration, 此时新节点对集群可见 ii. unlock catalog ● 准备扩容元数据 i. create gpexpand schema ii. create status/status_detail/expansion_progress 4.3 扩容进度监控 登录杜康系统,根据目标实例ID,进入任务监控页面,大致分为如下步骤 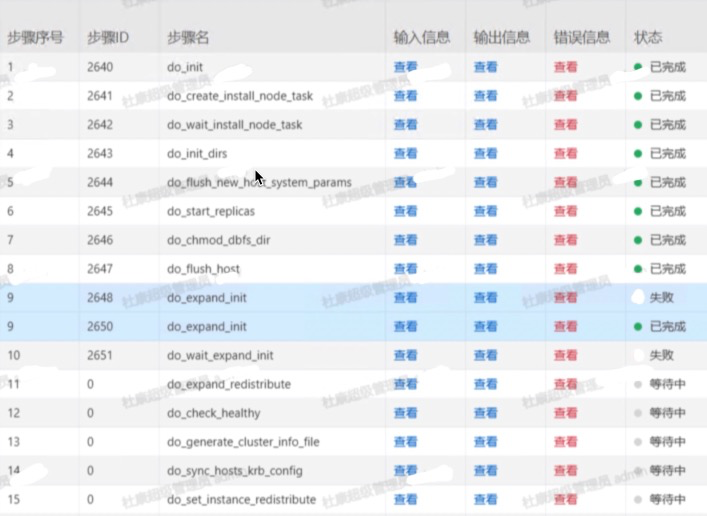
图8:扩容的任务流程 工作流是全流程自动化,包括segment扩容,集群信息刷新,数据重分布等。如上图,do_expand_init就是生成表的重分布计划,假如1万张表,这一步是产生重分布优先级,即并不会所有表同时处理;这一步的时间会跟数据仓库中表的数量强相关。上图中,do_expand_redistribute就是执行数据重分布,扩容默认是按照从小表到大表进行数据重分布。由于数仓数据一般都是TB数量级,不可能瞬间完成,直接自动重分布影响业务(可读不可写)。这里就是前文提到的,并不是一股脑自动化完成即可。这一步通常需要结合业务运行时间进行精细化控制,就是以下介绍的重分布方案。 5.重分布方案重分布方案最大的挑战就是不能影响业务,有点“开着飞机换螺旋桨”的意思。最重要的是与客户调研澄清表的重分布优先级,可以参考几个点进行评估: 1. 近期归档到外部存储(比如HDFS、OSS)上的数据表清单;不需要执行重分布 2. 按天、按周滚动删除再新建表、重新加载数据的表清单;不需要执行重分布 3. 业务同时强依赖的N个表;同一时段执行重分布 原因是如果1个SQL join了多个表,这些表分布的节点不一样,会发生数据在不同节点之间shuffle,造成额外开销。 4. 某个时段(09:00~24:00或00:00~09:00)一定有业务写入的表清单。错开该时段执行重分布 5.1 重分布的原理介绍 MPP节点增加后,表的分布规则按照新的节点数计算,因此数据也要重分布。重分布实际上类似按照新的分布规则建立一个新表,然后把旧表数据全量插入新表(再删除旧表),以达到数据按照新的节点数分布的目的。 上文提到的do_expand_init步骤,会生成一个扩容详情表gpexpand.status_detail,表包含了有关系统扩容操作所涉及的表的状态的信息。该表的定义参考: https://gp-docs-cn.github.io/docs/ref_guide/system_catalogs/gp_expansion_tables.html 最关键的status_detail.status的数据字典,ADB PG有修改, 表示扩容完成的状态值FINISHED==>COMPLETED -- 查看扩容已完成的表 psql> select * from gpexpand.status_detail where status = 'COMPLETED';其中,status_detail.rank 为int数值 ,值越小,优先级越高; 默认值为1。设置为0 后会优先对设置的表进行重分布。 因此,我们可以通过更新rank的值来制定重分布的优先级和顺序,int范围内的值都支持。 另外,重分布启动后,可以通过视图gpexpand.expansion_progress查询整体实例扩容进度(数据量维度)。 psql> select * from gpexpand.expansion_progress; 主要field解释如下: -- Bytes Done:已完成的字节数 -- Bytes Left:剩余未扩容的字节数 -- Tables Expanded:扩容完成的表数量 -- Tables In Progress:正在扩容中的表(为1表示扩容正常进行) -- Tables Left:剩余未扩容的表数量 -- Estimated Expansion Rate:预估扩容速度 -- Estimated Time to Completion:预估剩余时间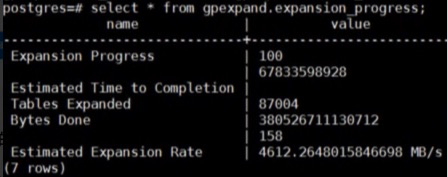
图9:整体扩容进度和速度示意图 5.2 制定精细方案 5.2.1 不需要重分布的表更新为重分布已完成 目的是为了精确控制重分布优先级。 psql> update gpexpand.status_detail set status = ‘COMPLETED’ where dbname = ‘db14’ and fq_name like ‘hist%’; -- dbname 数据库名 -- fq_name 表的名字 -- status 状态, update 为COMPLETED 就不会再进行重分布5.2.2 提高下一批重分布的表优先级 做完一批表之后,下一批要做的表,更新一下状态和优先级=0,表示下一批优先处理。 psql> update gpexpand.status_detail set status = ‘NOT STARTED’,rand = 0 where dbname = ‘db14’ and fq_name in (tab1,tab2,table3);5.2.3 重启扩容进程 以adbpgadmin用户登录adb的master; # 先kill ${gpexpand pid} ps aux | grep gpexpand|awk '{print $2}'|xargs kill # 然后后台启动。之后观察gpexpand日志确认Expanding的表是刚才设置的表。 # 强烈推荐使用此方法,-R 参数表可读不可写。 ~ nohup gpexpand -R & #nohup gpexpand & --注意此方法重新开始重分布会锁表,不可读不可写,不推荐。5.2.4 观察扩容日志 ~ tail -f /home/adbpgadmin/gpexpand_{date}.log若日志输出某张表正在扩容:“Expanding {database.schema.table}”,表示已开始重分布。 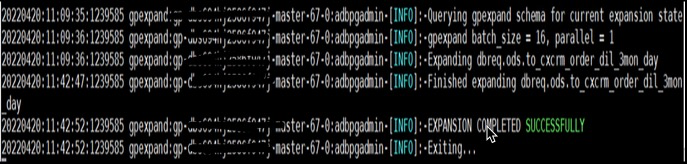
图10:重分布完成示意图 上图表示扩容重分布完成。 5.2.5 删除增加节点生成的schema 不删除以后则无法扩容。 ~ gpexpand -c 后记以上方案的落地和总结,结合了产品功能和实际业务场景,不一定尽善尽美,如果读者有更好的方案,欢迎一起讨论。 |
【本文地址】