| 毕业设计:基于python的论文文章数据分析与可视化系统 | 您所在的位置:网站首页 › 数据可视化实现界面时钟 › 毕业设计:基于python的论文文章数据分析与可视化系统 |
毕业设计:基于python的论文文章数据分析与可视化系统
|
前言
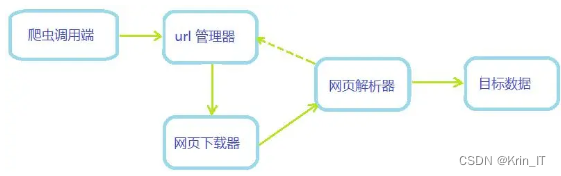
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。 🚀对毕设有任何疑问都可以问学长哦! 选题指导: 最新最全计算机专业毕设选题精选推荐汇总 大家好,这里是海浪学长毕设专题,本次分享的课题是 🎯基于python的论文文章数据可视化系统 设计思路 一、课题背景与意义随着学术研究的深入发展,论文文章数据的可视化成为了一个重要的研究方向。通过数据可视化,研究人员可以更加直观地理解论文中的数据、趋势和关联,从而更好地提取信息、分析规律和发现新知识。Python作为一种功能强大的编程语言,为论文文章数据的可视化提供了丰富的工具和库。基于Python的论文文章数据可视化系统可以帮助研究人员高效地处理和分析论文数据,将复杂的数据转化为直观、易于理解的图形和图表,促进学术研究的进步和创新。 二、算法理论原理 2.1 网络爬虫网络爬虫技术是一种自动化工具,用于从互联网上抓取、解析和提取数据。它根据预设的规则和算法,模拟人类浏览网页的行为,自动获取网页内容,并通过解析技术提取出有用的信息。网络爬虫在搜索引擎、数据挖掘、网站优化等领域有着广泛的应用。网络爬虫一般分为两种类型:传统爬虫和聚焦爬虫。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。而聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
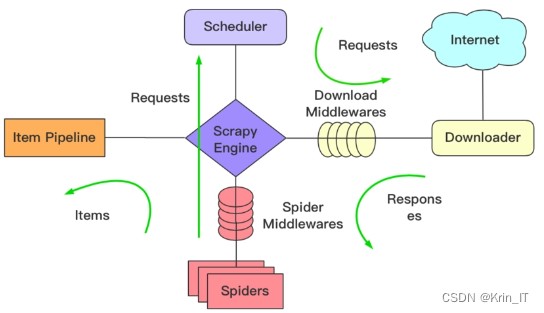
Scrapy的原理组成主要包括引擎(Engine)、调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)、项目管道(Item Pipelines)和中间件(Middlewares)等组件。引擎负责控制数据流在组件之间的传输;调度器负责管理待爬取的请求队列;下载器负责根据请求下载网页内容;爬虫负责解析网页内容并提取结构化数据;项目管道负责处理爬虫提取的数据,如清洗、存储等;中间件则提供了对请求和响应处理的扩展点,用于实现如代理、重试、日志等功能。 使用Scrapy进行论文文章数据爬取的流程通常包括以下几个步骤:首先,定义爬虫类并指定初始URL;然后,在爬虫类中编写解析逻辑,提取网页中的论文信息;接着,通过项目管道对提取的数据进行处理和存储;最后,配置并运行Scrapy项目,启动爬虫开始爬取数据。在爬取过程中,Scrapy会根据需要自动处理请求调度、页面下载、内容解析等任务,并将结果通过管道输出到指定的存储系统或进行进一步的数据分析与可视化处理。
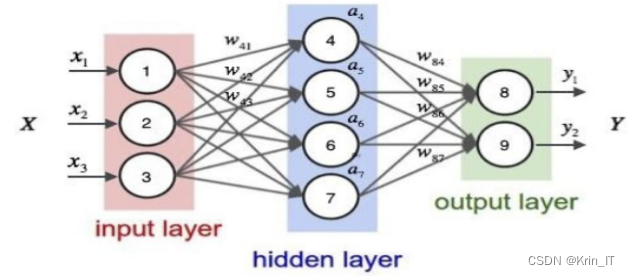
文本生成技术是一种利用自然语言处理和机器学习算法来自动创建文本内容的技术。它通过分析大量文本数据,学习语言模式和规律,然后生成新的、连贯的、有意义的文本。文本生成技术可以应用于各种场景,如自动写作、机器翻译、聊天机器人、智能问答系统等。自动写作是指计算机能够自动生成文章、新闻、小说等文本内容。这种技术通常基于深度学习和自然语言生成模型,如循环神经网络(RNN)、变分自编码器(VAE)和生成对抗网络(GAN)等。这些模型通过学习大量文本数据中的语言结构和语义信息,能够生成具有逻辑连贯性、语法正确性和内容多样性的文本。
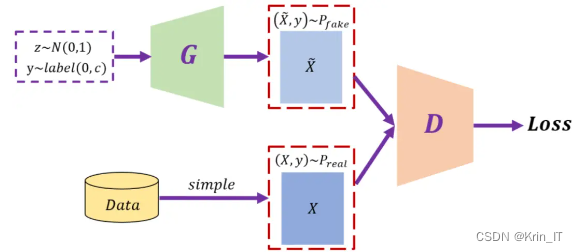
生成对抗网络(GAN)以其独特的优势在许多领域展现出巨大的潜力。其最显著的优势在于能够生成高质量、高清晰度的样本,如逼真的图像和音频,这主要归功于其通过对抗训练过程使生成器和判别器相互竞争、相互进步。此外,GAN无需标签数据进行训练,使其在无监督学习场景中表现突出,特别是在数据稀缺或标签获取困难的情况下。更重要的是,GAN能够学习输入数据的概率分布,从而生成与真实数据分布相似的新数据,这在图像风格迁移、超分辨率和图像补全等任务中尤为有用。尽管GAN面临训练不稳定和模式缺失等挑战,但其广泛的应用前景和不断的研究进展使其在人工智能领域持续受到关注和研究。
鉴于网络上缺乏适用于该系统的现有数据集,我决定利用Python自行爬取并制作一个全新的数据集。通过编写定制化的爬虫脚本,我能够精确地提取学术网站上的论文数据,包括文章标题、作者、摘要、引用次数等关键信息。这个过程涉及到了解目标网站的页面结构、使用Python爬虫库进行自动化抓取、以及利用正则表达式和XPath等技术来精确提取数据。同时,我还通过模拟用户行为来绕过反爬虫机制,确保数据的顺利爬取。 经过清洗和处理后的数据集将包含大量的论文数据,覆盖了多个学科领域和研究方向。这个自制的数据集将为我的论文文章数据可视化研究提供坚实的数据基础,帮助我深入了解学术论文的分布情况、研究热点、引用关系等信息。 3.2 技术思路以下是基于 Python 的论文文章数据分析与可视化系统的一些技术思路: 数据获取:使用适当的 Python 库或工具,从数据源(如数据库、文件或网络)中获取论文文章数据。数据清洗:对获取的数据进行清洗和预处理,包括去除噪声、处理缺失值、规范化数据等。数据分析:运用各种数据分析方法和算法,对论文文章数据进行分析。例如,词频统计、情感分析、关键词提取、文本分类等。数据可视化:选择合适的 Python 可视化库,将分析结果以直观的图形形式展示。这可以帮助用户更好地理解数据和发现趋势。模型构建:如果需要,可以使用机器学习或深度学习算法构建模型,对论文文章数据进行预测或分类。交互式可视化:实现交互式的数据可视化,使用户能够通过与图形的交互来探索数据。相关代码示例: import pandas as pd import matplotlib.pyplot as plt # 读取数据集 data = pd.read_csv('processed_data.csv') # 替换为你的数据集文件路径 # 绘制论文数量的学科领域分布 plt.figure(figsize=(10, 6)) data.groupby('Subject Area')['Paper ID'].nunique().plot(kind='bar') plt.xlabel('Subject Area') plt.ylabel('Number of Papers') plt.title('Distribution of Papers by Subject Area') plt.show() # 绘制研究热点的词云 plt.figure(figsize=(10, 6)) wordcloud = data['Keywords'].str.join(' ').str.findall(r'\b\w+\b') wordcloud = ' '.join(wordcloud) plt.imshow(WordCloud(wordcloud).generate()) plt.axis('off') plt.title('Research Hotspots Word Cloud') plt.show() # 绘制引用关系的网络图谱 plt.figure(figsize=(10, 6)) citations = data[['Paper A', 'Paper B']].values G = nx.Graph() G.add_edges_from(citations) nx.draw_networkx(G, pos=nx.spring_layout(G), with_labels=False, node_size=50) plt.axis('off') plt.title('Citation Relationship Network') plt.show()实现效果图样例:
创作不易,欢迎点赞、关注、收藏。 毕设帮助,疑难解答,欢迎打扰! 最后 |



【本文地址】