| 数据挖掘考题汇总(填空题与计算题)带答案 | 您所在的位置:网站首页 › 数据仓库关联规则例题 › 数据挖掘考题汇总(填空题与计算题)带答案 |
数据挖掘考题汇总(填空题与计算题)带答案
|
目录 一、填空题 二、计算题 求项集I和事务D 计算置信度 求取所有频繁项集 求取最大频繁项目集 推理强关联规则 Close算法解题步骤 FP - 树算法的计算步骤 序列模式发现算法 K-近邻分类算法 ID3 算法实例 C4.5 算法实例 CART 算法实例 朴素贝叶斯分类方法 K-means算法 一、填空题❃随着信息技术的高速发展,数据库应用的规模、范围和深度不断扩大,网络环境成为主流等等。产生“数据丰富而信息贫乏”现象。 ❃“数据丰富而信息贫乏”现象导致大数据概念。 ❃数据(Data)、信息(Information)和知识(Knowledge)是广义数据表现的不同形式。 ❃大数据时代的数据挖掘技术需求分析的流派:数据论、方法论、环境论、特征论。 ❃4V属性 :数据规模大(Volume) 、数据聚集快(Velocity) 、数据类型多(Variety) 、数据价值大(Value)。 ❃数据挖掘从本质上说是一种新的商业信息处理技术。 ❃数据库中的知识发现(KDD: Knowledge Discovery in Databases)是比数据挖掘出现更早的一个名词 ❃KDD在人工智能界更流行,而Data Mining在数据库界使用更多; 在研究领域被称作KDD,在工程领域则称之为数据挖掘。 ❃数据挖掘的目的是发现知识,知识要通过一定的模式给出。 ❃主要知识模式类型有:广义知识、关联知识、类知识、预测型知识、特异型知识。 ❃有两个基本的方法来挖掘类知识:分类、聚类。 ❃知识发现的基本过程可以简单地概括为:首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 ❃一般地说,KDD 是一个多步骤的处理过程,一般分为问题定义、数据抽取、数据预处理、数据挖掘以及模式评估等基本阶段。 ❃数据清洗是指去除或修补源数据中的不完整、不一致、含噪音的数据。 ❃数据库中的知识发现处理过程模型:阶梯处理过程模型、螺旋处理过程模型、以用户为中心的处理模型、联机KDD模型、支持多数据源多知识模式的KDD处理模型。 ❃关联规则挖掘是数据挖掘研究的基础。 ❃大于或等于 minsupport 的 ❃ ❃关联规则挖掘问题可以划分成两个子问题:发现频繁项目集和生成关联规则。 ❃置信度计算规则为: 同时购买商品A和商品B的交易次数÷购买了商品A的次数 ; 支持度计算规则为: 同时购买了商品A和商品B的交易次数÷总的交易次数。 ❃Appriori 属性1:如果项目集 X 是频繁项目集,那么它的所有非空子集都是频繁项目集。 Appriori 属性2:如果项目集 X 是非频繁项目集,那么它的所有超集都是非频繁项目集。 ❃Appriori 算法的两个性能瓶颈:多次扫描事务数据库需要很大的I/O负载,可能产生庞大的候选集。 ❃提高 Appriori 算法效率的技术:基于数据分割的方法、基于散列的方法、基于采样的方法等。 ❃分类分析的三个步骤:挖掘分类规则、分类规则评估、分类规则应用。 ❃决策树包含三种结点:根结点(矩形表示)、内部结点(矩形表示)、叶结点/终结点(椭圆表示)。 ❃决策树是一棵有向树,因有向边始终朝下,故省略表示方向的箭头。 ❃ID3算法以信息论的信息熵为基础,以信息增益度为“属性测试条件” ❃一组数据越有序,熵值越低;一组数据越无序,熵值越高。 ❃熵值越小所蕴含的不确定信息越小,越有利于数据的分类。 ❃ID3算法的优点:模型理解容易、噪声影响较小、分类速度较快。 缺点:只能处理离散属性数据、不能处理有缺失数据、仅是局部最优的决策树、偏好取值种类多的属性。 ❃C4.5算法不仅继承了ID3算法的优点,并增加了对连续型属性和属性值空缺情况的处理。 ❃C4.5算法采用基于信息增益率作为选择分裂属性的度量标准。 ❃CART(分类与回归树)本质是对特征空间进行二元划分(即CART生成的决策树是一颗二叉树) ❃CART采用Gini指数来度量分裂时的不纯度。Gini指数越大,样本集合的不确定性程度越高。 ❃聚类分析:每个子集内部数据对象之间相似度很高,而不同子集的对象之间不相似或相似度很低。 ❃明可夫斯基距离:r=1时曼哈顿距离,r=2时欧几里得距离,r→∞切比雪夫距离。 ❃二次型距离:A=I(单位矩阵)时欧氏距离,A为对角矩阵时加权欧氏距离。 ❃簇的形状主要分为类球状(凸形)的簇,非球状的簇。 ❃簇间关系:明显分离的簇、基于原型的簇、基于连片的簇、基于密度的簇、基于概念的簇。 ❃聚类框架及性能要求:对数据集的伸缩能力、处理混合属性的能力、发现任意形状簇的能力、聚类参数自适应能力、噪声数据的处理能力、数据输入顺序的适应能力、处理高维数据的能力、带约束条件的聚类能力。 ❃DBSCAN算法时间复杂性O(n²) 二、计算题 求项集I和事务D❃对于下表所示的交易数据库T,请给出项集和其中的事务。 ❃对于下表所示的交易数据库T,如果令X={b, c},Y={d},试计算其置信度。 ❃对于下表所示的交易数据库,其项集 ❃对于上题求得的频繁项集构成的集合L,请求出它的最大频繁项集集合。 解:根据定义,L中的最大频繁项集一定不是其他任何频繁项集的子集。 因此采取枚举法来寻找L中的最大频繁项集。 具体过程就是逐一找寻是否是其他频繁项集的子集,是就弃掉,不是就留下。 因为比较简单,这里就不再赘述了。 给出最后答案: ❃给定下面的一个事务数据库{(a,c,d,e,f),(b,c,f),(a,d,f),(a,c,d,e),(a,b,d,e,f)}完成: (1)写出 Apriori算法生成频繁项目集的过程及最大频繁项目集的结果(设MinSupport=50%)。 (2)写出由最大频繁项目集推理出强关联规则的过程。(设Minconfidence=60%)。 解:(1)第一问求解办法参见上题,这里给出答案: ❃使用Close算法作用到下表数据集的执行过程(假如minsup_count=3): ❃某超市经营a,b,c,d,e等5种商品,即超市的项集I={a,b,c,d,e},下表是其交易数据库T。 |
 解:项集
解:项集  解:
解: 解:
解: 
 由上表易得,所有规则均为强关联规则。
由上表易得,所有规则均为强关联规则。 解:(注:一个项目集C是闭合的,当且仅当对于在C中的任何元素,不可能在C中存在小于或等于它的支持度的子集。 例如,C1={AB3,ABC2}是闭合的; C2={AB2,ABC2}不是闭合的) ①计算候选1-项目集FCC1各个产生式的闭合和支持数。(假如minsup_count=3) FCC1的产生式:{A}, {B} , {C}, {D}, {E} 具体而言,对应的闭合求法是每一个产生式在样本数据库中出现的所有Itemset的交集。
解:(注:一个项目集C是闭合的,当且仅当对于在C中的任何元素,不可能在C中存在小于或等于它的支持度的子集。 例如,C1={AB3,ABC2}是闭合的; C2={AB2,ABC2}不是闭合的) ①计算候选1-项目集FCC1各个产生式的闭合和支持数。(假如minsup_count=3) FCC1的产生式:{A}, {B} , {C}, {D}, {E} 具体而言,对应的闭合求法是每一个产生式在样本数据库中出现的所有Itemset的交集。  ②裁剪后频繁闭合1-项目集FC1与候选1-项目集FCC1相同。 ③利用FCC1的产生式生成FCC2,连接生成FCC2={AB,AC,AD,AE,BC,BD,BE,CD,CE,DE} 修剪生成FCC2,与上式同。 再进行筛选 :对于FCCi+1的每个产生式,若为FCi的产生式的闭合的子集,删去 则FCC2={AD, AE,CD,CE,DE} ④计算FCC2各产生式的闭合及支持数
②裁剪后频繁闭合1-项目集FC1与候选1-项目集FCC1相同。 ③利用FCC1的产生式生成FCC2,连接生成FCC2={AB,AC,AD,AE,BC,BD,BE,CD,CE,DE} 修剪生成FCC2,与上式同。 再进行筛选 :对于FCCi+1的每个产生式,若为FCi的产生式的闭合的子集,删去 则FCC2={AD, AE,CD,CE,DE} ④计算FCC2各产生式的闭合及支持数  ⑤将支持度小于最小支持度的候选闭合项删除,频繁闭合2-项目集FC2为空。算法结束。 将所有不重复的闭合加入到FC中,得到FC={{ABC},{B},{BC},{BD},{BE}}。 ⑥统计项目集元素数。 将所有的闭合项募集按元素个数统计,得到L3 ={ABC}, L2 ={BC,BD,BE}, L1 ={B}。 ⑦将L3 的频繁项分解 先分解{ABC}的2-项子集, {AB}, {AC}, {BC},并把不存在的{AB}, {AC}加入到L2中,支持数和{ABC} 的支持数相同。 L2={AB,AC,BC,BD,BE} ⑧将L2 的频繁项分解 方法同上,得到L1 ={A,B, C,D,E}
⑤将支持度小于最小支持度的候选闭合项删除,频繁闭合2-项目集FC2为空。算法结束。 将所有不重复的闭合加入到FC中,得到FC={{ABC},{B},{BC},{BD},{BE}}。 ⑥统计项目集元素数。 将所有的闭合项募集按元素个数统计,得到L3 ={ABC}, L2 ={BC,BD,BE}, L1 ={B}。 ⑦将L3 的频繁项分解 先分解{ABC}的2-项子集, {AB}, {AC}, {BC},并把不存在的{AB}, {AC}加入到L2中,支持数和{ABC} 的支持数相同。 L2={AB,AC,BC,BD,BE} ⑧将L2 的频繁项分解 方法同上,得到L1 ={A,B, C,D,E}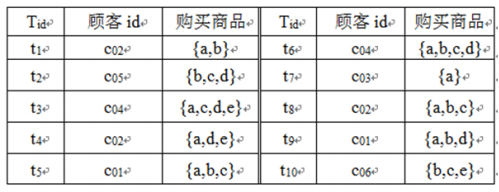 借用这个事务数据库来介绍FP-树的构造方法,这里假设最小支持数MinS=2。 解:第一步:构造FP-树 ①生成事务数据库的头表H(按支持数递减排列) 对于上表的事务数据库T,其头表H={(a:8),(b:7),(c:6),(d:5),(e:3)},即T中的每个项都是频繁的。 ②生成事务数据库的FP-树
借用这个事务数据库来介绍FP-树的构造方法,这里假设最小支持数MinS=2。 解:第一步:构造FP-树 ①生成事务数据库的头表H(按支持数递减排列) 对于上表的事务数据库T,其头表H={(a:8),(b:7),(c:6),(d:5),(e:3)},即T中的每个项都是频繁的。 ②生成事务数据库的FP-树  第二步:生成频繁项目集 (1)生成e的条件FP-树 ① 确定项目e。搜索头表H={(a:8),(b:7),(c:6),(d:5),(e:3)}的最后一项,其项目名称为e。 ② 生成以e结尾的前缀路径。它们分别是null-a-c-d-e、null-a-d-e和null-b-c-e,得到以e结尾的前缀路径。
第二步:生成频繁项目集 (1)生成e的条件FP-树 ① 确定项目e。搜索头表H={(a:8),(b:7),(c:6),(d:5),(e:3)}的最后一项,其项目名称为e。 ② 生成以e结尾的前缀路径。它们分别是null-a-c-d-e、null-a-d-e和null-b-c-e,得到以e结尾的前缀路径。 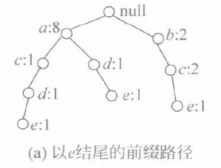 ③ 更新项目支持数。将以e结尾的前缀路径上所有项的支持数改为e的支持数。如果一个结点在多条路径中重复出现,则每重复1次,该结点的支持数增1。得到更新后以e结尾的前缀路径。
③ 更新项目支持数。将以e结尾的前缀路径上所有项的支持数改为e的支持数。如果一个结点在多条路径中重复出现,则每重复1次,该结点的支持数增1。得到更新后以e结尾的前缀路径。 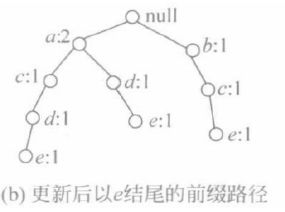 ④ 生成e的条件FP-树。因为b的支持数
④ 生成e的条件FP-树。因为b的支持数【本文地址】