| 基于“数字孪生”和YoLoV5的AI药物开发(技术理论实践部分) | 您所在的位置:网站首页 › 数字孪生的模拟 › 基于“数字孪生”和YoLoV5的AI药物开发(技术理论实践部分) |
基于“数字孪生”和YoLoV5的AI药物开发(技术理论实践部分)
|
阿尔茨海默病已经是威胁老年人健康最严重的疾病之一。如今我国正处在人口老龄化上升期,预防和治愈它是当下棘手问题。所以我团队基于“数字孪生”模拟大脑电场,用YoLoV5构建神经网络模型进行预测病变,进行AI药物开发。以下为我在此方面的研究 项目概述 项目将基于“数字孪生”模拟大脑电场,就当下阿尔茨海默病已经是威胁老年人健康最严重的疾病之一和我国正处在人口老龄化上升期,预防和治愈它是当下棘手问题为项目开发背景。用YoLoV5构建神经网络模型进行预测病变,进行AI药物开发,克服现在对阿尔茨海默病不能很好的克制的局面,减少阿尔茨海默病诱发率和死亡率。 项目可行性分析 硬件设备 项目基于创新实验室设备进行开发实验室已然达到了项目开发需要。实验室电脑硬件配置标准: CPU Intel(R) Core(TM) i7-10510U CPU @ 1.80GHz 2.30 GHz以上 GPU NVIDIA GeForce MX350 NVIDIA GeForce MX 350以上 SSD NVMe HFM512GDJTNG-831 NVMe HFM 512GDJTNG-831以上 软件设备 项目基于Windows10家庭版和Centos7为系统平台,项目开发中深度学习和机器学习代码编写采用python语言和pycharm专业版,大数据分析采用Java语言和Hadoop平台结合Zookeeper分布式应用程序协调服务、HBase在IntelliJ IDEA专业版开发。 项目优势及特点 项目优势 “数字孪生”取代传统试验。我们项目紧贴人工智能前沿技术,其中,我们使用“数字孪生”进行人脑的模拟取代过去传统的动物试验。“数字孪生”目前正出现在多个领域,“数字孪生”指根据真实世界获得的数据创建一个数字模型,可用于模拟任何系统或过程。在医疗领域,这一趋势包括对“虚拟患者”——那些测试药物和治疗的人进行数字模拟,目的是缩短新药从设计阶段进入通用阶段所需的时间。所以就目前的情况而言,人体器官和系统的“数字孪生”更接近现实,这使医生能够探索不同器官出现疾病的原因并开展治疗试验,而不需要开展昂贵的人体或动物试验。 利用深度学习理解医学影像。我们项目采用pytorch+YoLoV5的方式进行对医学影像的目标检测。“YOLO”是一个对象检测算法的名字,YOLO将对象检测重新定义为一个回归问题。它将单个卷积神经网络(CNN)应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框,而且YoLoV5使用Mosaic数据增强操作提升模型的训练速度和网络的精度。YOLO非常快。由于检测问题是一个回归问题,所以不需要复杂的管道。它比“R-CNN”快1000倍,比“Fast R-CNN”快100倍而且YoLoV5是目前YOLO最稳定的版本。
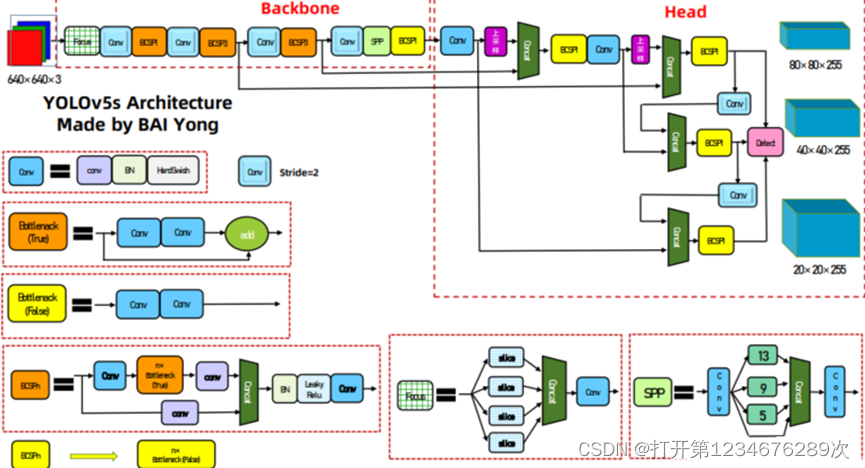
图 2‑1two stage的目标检测算法网络结构 利用AI和机器学习理解医学数据进行AI药物开发。诊断和药物外,如何进行精准治疗是医学界一直在努力的课题。包括基因组学、AI和“数字孪生”等现代医疗技术,将使医生们能采取更个性化的方法,根据患者自身的情况量身定制疗法。我们项目便是使用AI和建模软件来预测阿尔茨海默病患者用药的确切剂量。对于早期阿尔茨海默病患者来说,适量药物能有效并提升他们的生活质量,但剂量过高,则极其危险,所以AI也可成为患者的救星,并提升他们的恢复效果。 项目特点 在前面已然谈到我们项目的研究理念是“查、测、治”,那接下来介绍的便是我们项目的特点“快、准、稳”。 “快”是通过患者大脑视网膜医学影像快速进行阿尔茨海默病进行识别。YoLoV5算法不同于YoLoV3/v4,其GT可以跨层预测,即有些bbox在多个预测层都算正样本;匹配数范围可以是3-9个。预测得到的输出特征图有两个维度是提取到的特征的维度,比如13*13,还有一个维度(深度)是 B*(5+C)。当然目前目标检测领域的深度学习方法主要分为两类:two stage 的目标检测算法;one stage 的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率和定位精度上占优,后者在算法速度上占优,YoLoV5的Backbone: Focus, BottleneckCSP, SPP;Head: PANet + Detect (YoLoV3/v4 Head)。所以它兼顾了两者。
图 2‑2YoLoV5网络结构图 “准”是通过YoLoV5算法快速识别后进行的准确判断。YoLoV5之所以准确Mosaic数据增强功不可没。Mosaic数据增强利用四张图片,并且按照随机缩放、随机裁剪和随机排布的方式对四张图片进行拼接,每一张图片都有其对应的框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。该方法极大地丰富了检测物体的背景,且在标准化BN计算的时候一下子计算四张图片的数据,所以本身对batch size不是很依赖。
图 2‑3实例批处理对比图 “稳”是通过机器学习理解完医学数据后由AI稳稳地给出药物开发方案。与在其他行业一样,AI在医疗保健领域发挥的重要作用包括理解大量杂乱、非结构化数据。这些数据包括X光、CT和MRI扫描等获得的数据、有关新冠等传染病疫苗分发的数据以及活细胞基因组数据,甚至医生手写的笔记等。未来几年,人工智能将对预防医学领域产生深远影响。预防医学不通过事后提供治疗来对疾病作出反应,而是预测疾病将在何时何地发生,并在疾病发生之前制定解决方案。这包括预测传染病暴发的地点、病患的再住院率以及饮食、锻炼、运动等生活方式因素。这些工具能够比传统分析过程更有效地发现巨大数据集中的模式,从而实现更准确地预测并最终改进疗效。 项目算法实现 研究对象 观眼识病在我国古代就有历史记载。在汉代的《内经》就有对眼诊的描述,如《灵枢·大惑论》记载:“目者,心之使也。”,“五脏六腑之精气,皆上注于目而为之精。”在中医中就有论著说明了眼睛的特定部位对应着人体的一些器官,这些信息对于AI来说具有重要的价值,该书还将眼的不同部位分属于五脏,也就是后代医家沿用的五轮学说,即两眦血络属心(血轮),白珠属肺(气轮);黑珠属肝(风轮);瞳仁属肾(水轮);眼泡属脾(肉轮)。因此根据眼睛不同部位的颜色和形态的变化,可以诊察不同的疾病。我们主要研究β-淀粉样蛋白簇是否积淀在视网膜。
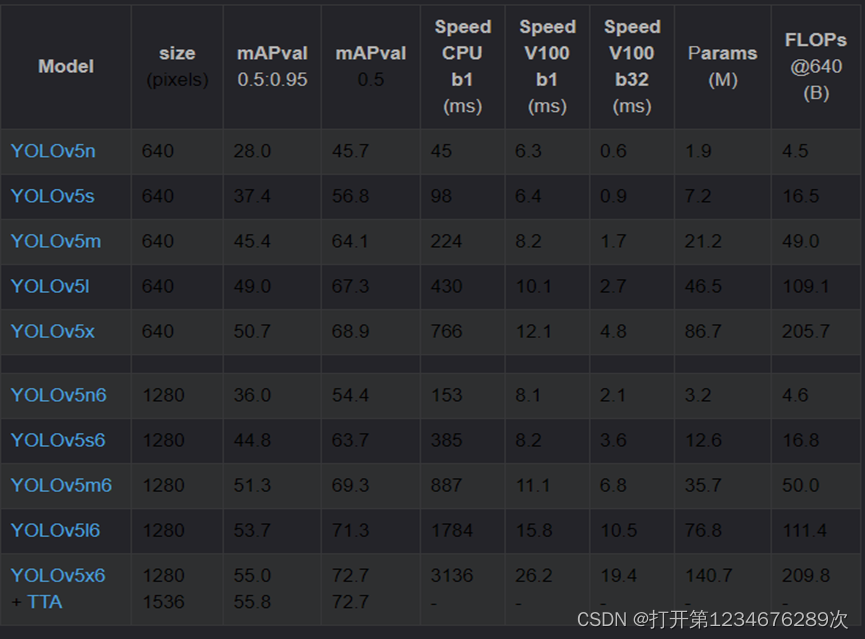
图 2‑4β-淀粉样蛋白图 研究所用框架与技术 在当今互联网上实现对人眼的识别的方法是多种多样的,在开发语言上有Python、C++和Java等。现阶段用于深度学习的语言最主流是:Python。Python在AI方面的领域是运用最多的。Python常用的深度学习框架有Theano、TensorFlow和PyTorch等。本项目主要采用的是基于Python的PyTorch框架,它是从Lua的Torch库到Python的松散端口,由于它由Facebook的人工智能研究团队(ArtificiaUntelligence Research team (FAIR))支持且它可以用于处理动态计算图。使用该框架是因为相对于TensorFlow等其它语言来说更加简单,并且YoLoV5是运用PyTorch框架的项目,这也是课题所用到的学习框架。 YoLoV5是UltralyticsLLC公司于2020年6月9日公开发布的。YoLoV5模型是基于YoLoV3模型基础上改进而来,发展到现在YoLoV5发布到现在已经有v6.1版本了,而且在GitHub上的贡献开发者共236人或组织。该算法继承自YoLoV3,在此基础上增加了很多图片增强技术以及优化了骨架网络,YoLoV5在现阶段有非常多的应用实践,对于本课题中的眼诊图像信息之心区信息识别YoLoV5是一个不错的选择。 我们项目所用的视网膜β-淀粉样蛋白簇检测算法YoLoV5采用了Python语言进行编程,Python是一种解释型的交互式和面向对象的脚本语言,它的设计哲学是“优雅”、“明确”、“简单”而这也说明了Python的特点是简单、和高可读性的。 技术方案 项目才用的技术方案为基于Python与pytorch深度学习框架下的YoLoV5,并用YoLoV5算法来实现对研究对象眼部心区的识别。YoLoV5在Github上的代码开源链在这里。运行算法之前需要先选择一个合适的模型,YoLoV5的作者给出了图2-5是当前(v6.1)官网贴出的关于不同大小模型以及输入尺度对应的mAP、推理速度、参数数量以及理论计算量FLOPs。
图 2‑5模型参数 通过表格可以看到YoLoV5提供了像素更高的模型,其他不过训练速度会因此与同规模的速度会慢很多如YoLoV5s6与YoLoV5s比CPU那一栏的速度慢了将近4倍,这是因为YoLoV5*6模型不仅像素提高到1280*1280,同时下采样到64倍,采用4个预测特征层而YoLoV5*模型只会下采样到32倍且采用3个预测特征层。因此在不考虑YoLoV5*6模型的情况下选择对比其他5种模型,包括YoLoV5n、YoLoV5s、YoLoV5m、YoLoV5l 和 YoLoV5x,模型的区别是通过调节深度倍数(depth_multiple)和宽度倍数(width_multiple)两个参数实现的。其中:深度倍数为控制BottleneckCSP数,宽度倍数:控制卷积核数量。我将YoLoV5n、YoLoV5s、YoLoV5m、YoLoV5l 和 YoLoV5x这5种模型的深度倍率与宽度倍率汇总为表1。 表1不同模型的深度 YoLoV5n YoLoV5n YoLoV5n YoLoV5n YoLoV5n depth_multiple 0.33 0.33 0.33 0.33 0.33 width_multiple 0.25 0.25 0.25 0.25 0.25 YoLoV5的网络结构大致有三部分组成,分别为骨架网络(backbone),头部(head),最后是输出(output),在图片输入骨架网络入口之前会先将图片进行处理,也就是图片增强技术,最后将图片缩放成646×640的规格送入骨架网络入口。经过了一系列算法之后会输出三种规格的数据给GPU进行训练,这样训练会有更好的效果能识别更多不同大小的物体。 训练集与权重因子 训练集 YoLoV5是分类目标检测算法,但是在我们项目中识别先用基础眼病为模型,类型选用“白内障”,“病理性近视”,“普通”,“糖尿病”,“青光眼”,“高血压”六类进行初步模拟训练。以下便是利用Anconda环境下的labelImg标注进行标注工作:
图 2‑6 labelImg工作台
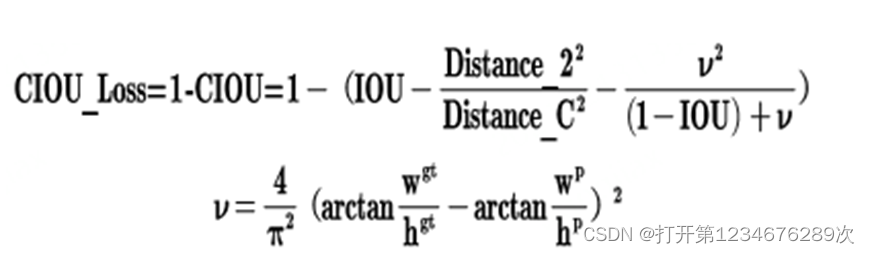
图 2‑7训练后labels回归图 每一张图片都有对应的标签(label),标签的内容是将框图框选出来的是属于哪一类,并且处于图片相对位置的哪里。假设目前有十个数据其中每一行代表一个目标,每个目标有五个数据,第一个数据是类别编号,也就是对应eye_hear这个标签另外4个数据分别表示中心横坐标与图像宽度的比值、中心纵坐标与图像宽度的比值、检测框宽度与图像宽度的比值和检测框高度与图像高度的比值。我将图片和label的第一个目标用Python进行转换,如果要框出一个矩形框只需要知道矩形框的对角的两个点就可以了。
图 2‑8计算公式 训练权重因子 在训练图片之前需要先设置一些参数以适配电脑硬件配置,以让训练达到我所理想的条件,具体比较重要的配置内容有: (1)每次神经训练的图片数(batch-size) 首先需要先测试一下GPU显存大小能承受多大的batch-size。通过多次测试发现当batch-size=4的时候刚好能跑满我的GPU,为了最大化训练速度,我选取了batch-size=4即parser.add_argument('--batch-size', type=int, default=4)这个参数进行模型训练。 (2)训练好的网络模型路径(weights) 由于我所需要的训练模型有可参考的所以需要重头开始训练因此此处为yolov5s.pt。 (3)数据集迭代次数(epochs) 通过查询一些资料发现在COCO数据集中选择模型为YoLoV5s时当迭代次数在300的时候,效果是最好的,而超过会出现过拟合的情况,虽然现在的YoLoV5会保存最优的一次训练结果,但是这样的训练会浪费很多计算机资源,由于我没有测试迭代次数是否过拟合的数据因此参考COCO数据集的最优迭代次数来作为本次实验的迭代次数,训练后的效果比较理想。 (4)网络结构(cfg) 结合我的硬件设备我选用的是YoLoV5s这种结构,该结构在满足我硬件配置的同时也提升了训练速度。因此我选择的是yolov5s.yaml这个模型。 (5)选择GPU或CPU的号数(device) 我有一张可训练的GPU显卡所以此处填0。 (6)训练数据路径与物体类的配置文件路径(data) 我将我所需要训练的数据整理好,以及所需要的检测的类的个数,和类的名称设置好了之后放入yolov5.yaml里面,因此这里填yolov5.yaml。 测试集与测试实验 测试集上我随机从阿里天池数据集挑选了1张图片进行测试。
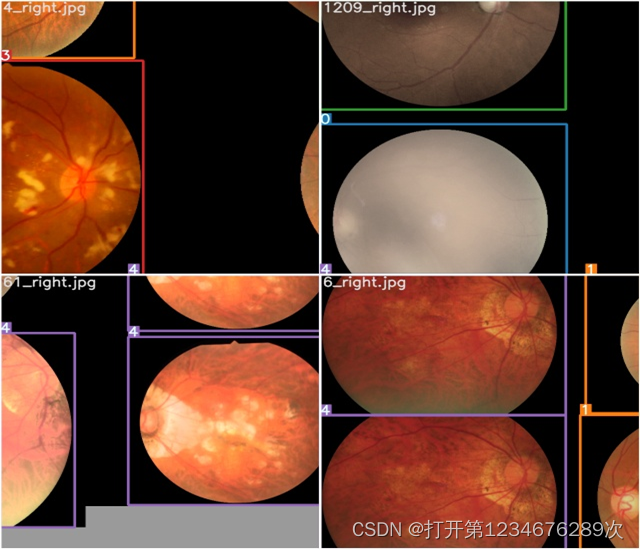
图 2‑9测试图片 另外需要配置这些参数:训练好了的模型路径(weights)、需要测试的图片路径(source)、自己的数据集模型路径(data)、置信度显示阈值(conf-thres)、图像重合度(iou-thres)等。以下为部分代码: parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='model.pt path') parser.add_argument('--data', type=str, default='data/coco.yaml', help='*.data path') parser.add_argument('--batch-size', type=int, default=32, help='size of each image batch') parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)') parser.add_argument('--conf-thres', type=float, default=0.001, help='object confidence threshold') parser.add_argument('--iou-thres', type=float, default=0.65, help='IOU threshold for NMS') parser.add_argument('--save-json', action='store_true', help='save a cocoapi-compatible JSON results file') parser.add_argument('--task', default='val', help="'val', 'test', 'study'") parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')实验结果分析及应用 结果分析 从训练结果中可以看到其中2行4列、3行2列、4行2列和4行4列几张图片测到了视网膜病变原因,从肉眼看确实观察不到视网膜病变位置,因此满足90%以上的检测到了视网膜病变位置,检测成功数29,一共肉眼能分辨的心区29。训练结果符合预期,置信度符合预期。 图 2‑10训练结果图 从硬件方面来说,我的电脑性能可提升空间大,而且也仅仅采用了YoLoV5s权重进行训练,在提高电脑性能时可训练大量的图片数据集同时实现的时间大幅缩短,在训练时增多图片人种的多样性、复杂性和实时性。YoLoV5是可以边使用边训练的,在本次实验的基础上在实际使用的过程中更换更加权威的数据并进行二次训练,可以提高训练模型的精确度和置信度。在数据充足的情况下可以识别视网膜是否存在β-淀粉样蛋白物质。 结果应用 经过初步识别处理后便是基于AI的识别判断进行,AI药物的开发,这块我们受能力限制,只能通过大数据分析给出治疗所匹配的药物方案。平台我们选用Hadoop平台进行数据挖掘、数据清洗、数据分析,最后通过Klearns算法给出药物开发方案。
图 2‑11Hadoop平台 |






【本文地址】