| 【精选】机器学习SVM | 您所在的位置:网站首页 › 支持向量机实验原理 › 【精选】机器学习SVM |
【精选】机器学习SVM
|
机器学习实验报告
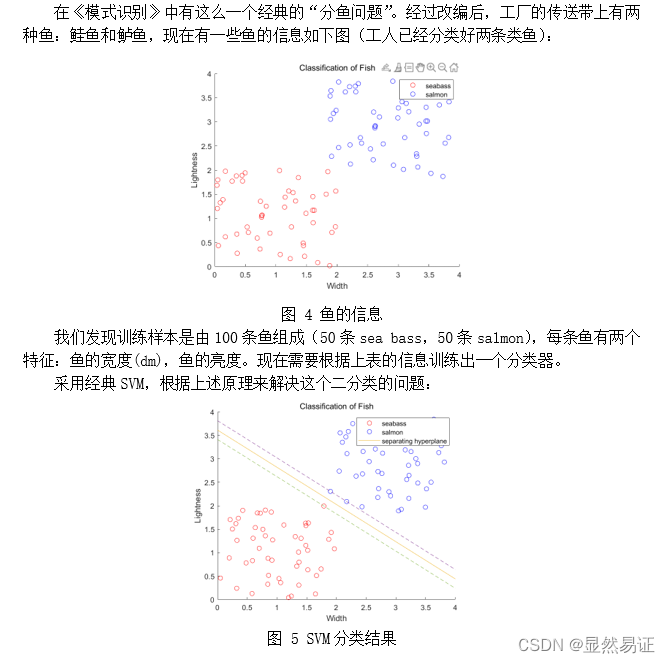
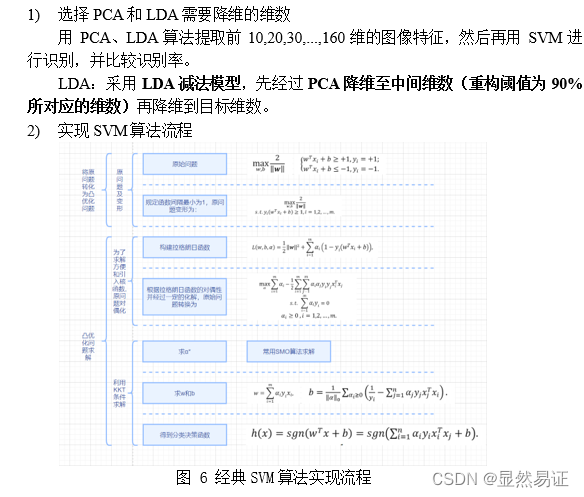
〇、实验报告pdf可在该网址下载一、实验目的与要求二、实验内容与方法2.1 SVM的基础概念2.2 经典SVM的优化问题及其推导2.3 核技巧SVM的优化问题及其推导2.4 软间隔SVM的优化问题及其推导2.5 MATLAB函数求解上述优化问题2.6 例子:经典SVM对二维平面对二类问题进行分类
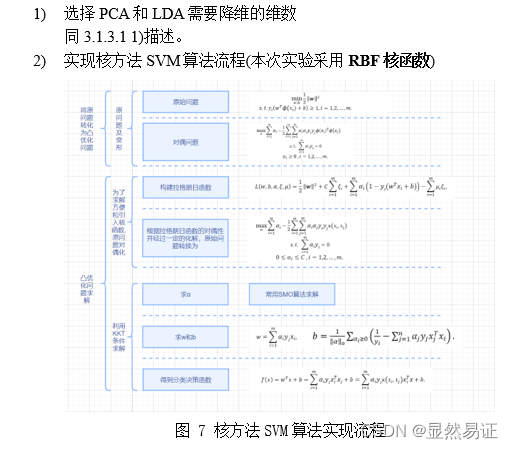
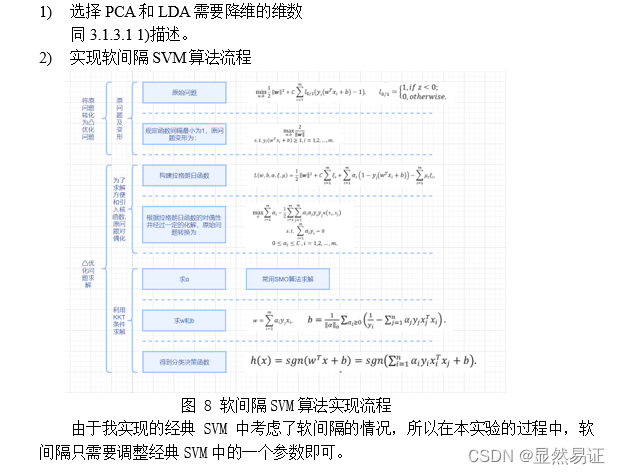
三、实验步骤与过程3.1 比较现有分类算法在人脸识别中的性能3.1.1 实验数据集与训练集、测试集的划分3.1.2 SVM多分类器3.1.3 实验步骤1. PCA/LDA算法+SVM分类器进行人脸识别2. PCA/LDA算法+核方法SVM进行人脸识别3. PCA/LDA算法+软间隔SVM进行人脸识别
3.1.4 实验结果1. ORL数据集的识别率和效率2. AR数据集的识别率和效率(中间维度:33)3. FERET数据集的识别率和效率(中间维度:75)
3.1.5 结果分析
3.2 对比已学人脸识别方法3.2.1 实验说明3.2.2 实验结果3.2.3 实验结果分析
四、实验结论或体会4.1遇到的问题以及解决方法:4.2感受:
〇、实验报告pdf可在该网址下载
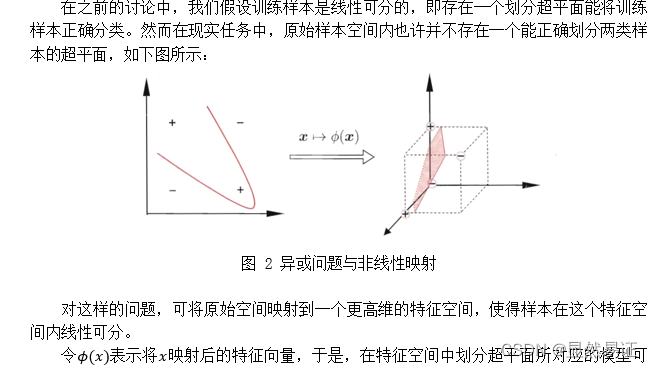
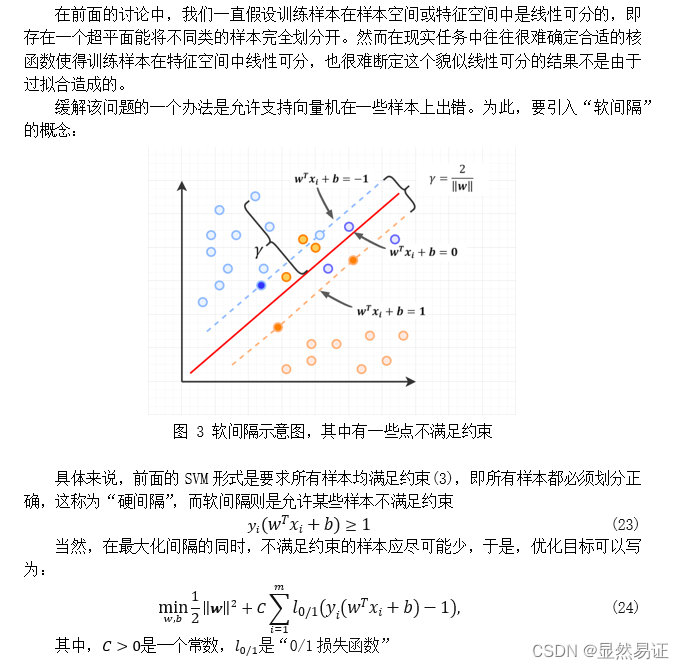
机器学习实验四:SVM 这个需要积分下载(因为实验报告后台查重,不建议直接白嫖)。 建议看博客,博客里面会有很多实验报告小说明会用【…】加粗注释。 一、实验目的与要求实验目的 掌握SVM的原理,熟悉SVM(包括软间隔和核技巧)的优化问题,并掌握其公式推导过程。能使用SVM解决实际问题,如:人脸识别等。能大概了解SVM的优化方向核现阶段基于经典SVM的优化算法,并有自己的理解。在此基础上,力求给出自己的创新点。实验要求 分别给出经典的/软间隔/核-SVM的优化问题并推导其求解优化过程,实现经典的SVM算法进行图像识别;在二维平面对二类问题给出support vector的一个示例。用PCA、LDA算法提取前 10,20,30,…,160维的图像特征,然后再用SVM进行识别,并比较识别率。另起一节同时设计一个创新的SVM算法,内容简要写在实验报告中,并与经典SVM比较。(详细内容可另写成一篇论文提交到“论文提交处”。) 二、实验内容与方法 2.1 SVM的基础概念
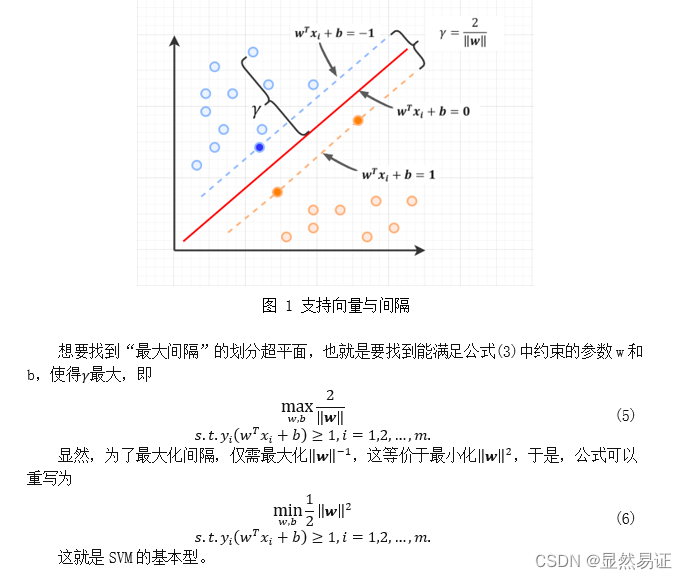
求解思路: 采用对偶问题来求解SVM基本型的优化问题。 求解步骤:
ORL56_46人脸数据集 该数据集共有40个人,每个人10张图片。每张图片像素大小为56×46。本次实验该数据集每个类划分为5张训练集,5张测试集,使用40个类。 AR人脸数据集 该数据库由3个以上的数据库组成;126名受试者面部正面图像的200幅彩色图像。每个主题有26张不同的图片。对于每个受试者,这些图像被记录在两个不同的时段,间隔两周,每个时段由13张图像组成。所有图像均由同一台摄像机在严格控制的照明和视点条件下拍摄。数据库中的每个图像都是768×576像素大小,每个像素由24位RGB颜色值表示。本次实验该数据集每个类划分为13张训练集,13张测试集,使用前16类。 FERET人脸数据集 该数据集一共200人,每人7张,已分类,灰度图,80x80像素。第1幅为标准无变化图像,第2,5幅为大幅度姿态变化图像,第3,4幅为小幅度姿态变化图像。第7幅为光照变化图像。本次实验该数据集每个类划分为4张训练集,3张测试集,使用200类。 3.1.2 SVM多分类器因为在人脸识别的时候,不可能只识别两个人。理论上SVM解决的是二分类的问题,所以对于人脸识别这种多分类问题来说,就需要考虑多分类SVM方法。 根据阅读有关资料:目前,构造SVM多分类器的方法主要有两种: (1) 直接法:直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”多分类。但是计算复杂度较高。 (2) 间接法:主要是通过多个二分类器来实现多分类器的构造,常见方法也有两种。 这里对于SVM多分类器的构造就不过多赘述。 因为人脸识别往往类别数会非常多,所以我采用了以下相对计算量较小的“一对多法”:
注意到:LDA算法只能降维至[1,类别数-1]这个区间内。所以目标维数不能过高。且先进行PCA降维至中间维数(重构阈值为90%)所对应的维数。所以LDA最终维数要低于PCA的中间维数。 1. ORL数据集的识别率和效率
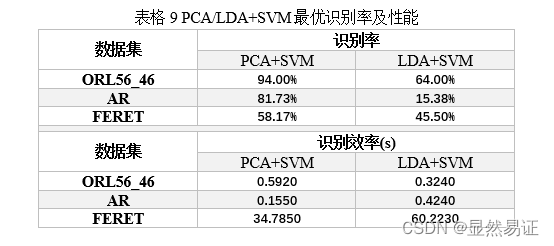
整理上述实验结果,汇总记录一下最优情况,并与没有进行任何降维直接采用SVM算法进行比较(此处的SVM为经典SVM算法)。 采用PCA、LDA、LRC、PCA+SVM、LDA+SVM五种目前学习的人脸识别方法的对比(识别率)。为了避免重复工作,下表是参考以前实验报告中的数据。 PCA:目标维度为重构阈值90%所对应的维度; LDA:中间维度为PCA重构阈值90%所对应的维度,最终维度采用枚举法得到识别率最高的维度; LRC:线性回归在人脸识别中的应用; PCA+SVM:识别率为维度范围10~160中最高的识别率; LDA+SVM:识别率为维度范围10~(class-1)中最高的识别率。 3.2.2 实验结果
从上表可以看出,识别率最高的人脸识别方法是PCA+SVM。我们通常认为LDA在分类问题上会优于PCA,但是在与SVM配合的过程中,由于LDA降维的有限性,目标维数只能在[1,(class-1)]之间,这会导致类别数比较少的样本会在降维的时候损失掉大量的信息,对于SVM而言无疑是一个极大的负面影响。 四、实验结论或体会 4.1遇到的问题以及解决方法:LDA除法模型+SVM的时候,需要先PCA降维,再进行LDA降维。但是当LDA最终维数过高的时候,PCA中间维数也会相对变得更大,这会导致PCA降维并不充分,导致除法模型Sb/Sw矩阵趋于奇异,进一步造成了函数quadprog报错。 在我实验的过程中出现了以下的问题: 本次实验的代码感觉跑起来非常慢,尤其是FERET数据集,一共200个类,非常难跑,很容易卡机。然后本次实验报告个人感觉内容十分充实,不仅在于大量的公式推导上,而且实验的代码特别容易出错,尤其在编写SVM的优化问题的时候。因为SVM是一个有约束的优化问题,一般没有显示解,所以这就需要在实现的过程中非常的细心。 SVM不亏是传统机器学习领域独当一面的有效分类算法,这个算法的思想也非常优美,当然。在我汇报的论文中,作者提出目前的SVM求解方法有两种,课堂上更多的是第一种:利用对偶问题求解;还有一种是基于几何解释的求解。SVM的领域还是非常宽泛的,应用场景也非常广泛,在此,对科研工作表达敬意! |






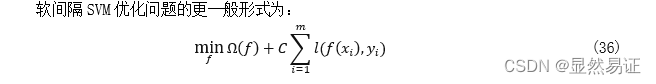


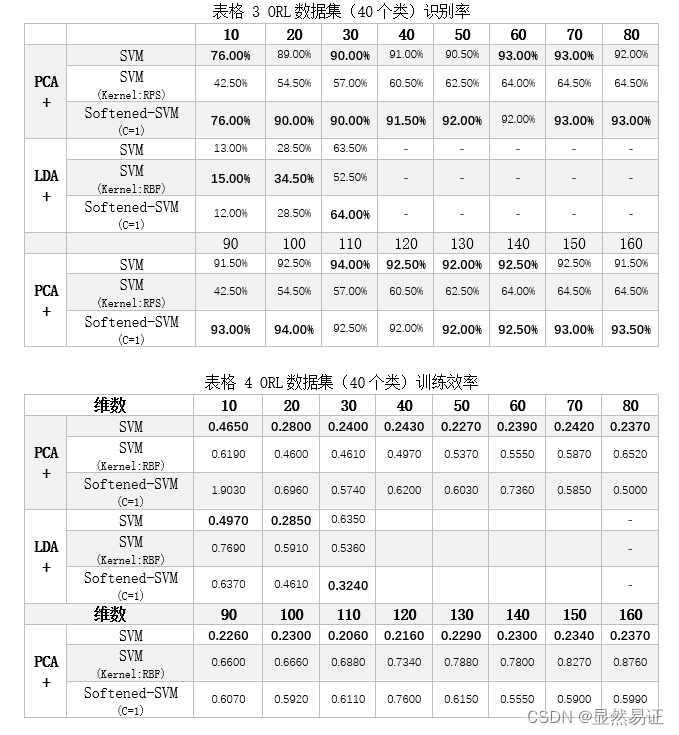
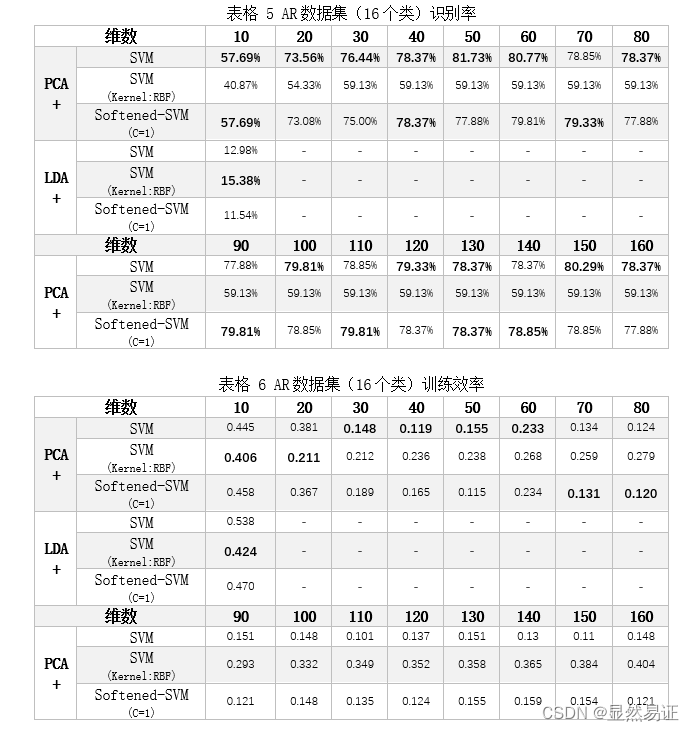
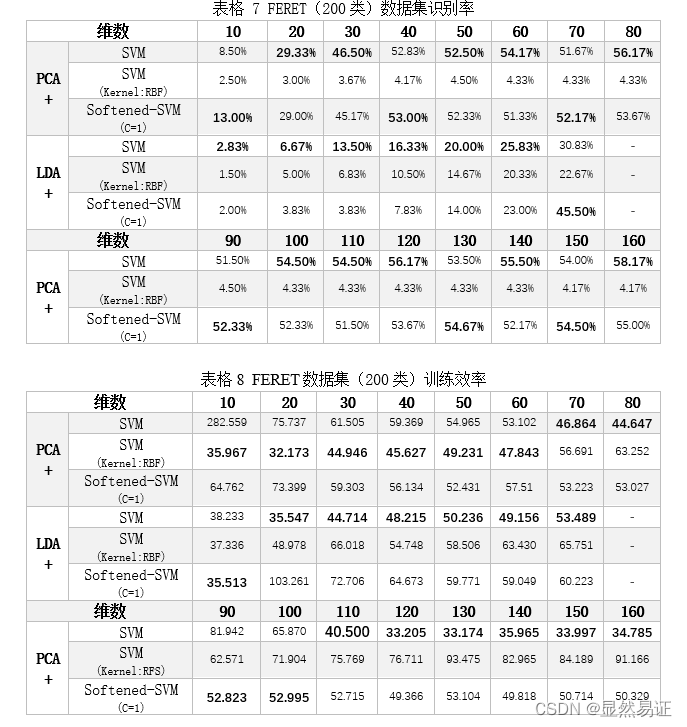
 上表可见:数据降维对于SVM分类器而言是非常必要的。对SVM分类器而言,运算的时间复杂度取决于输入数据的维数n,不同的解法有不同的时间复杂度,常见的解法都在O(n)- O(n^3)之间。如果直接将局部特征提取的结果作为输入,那么SVM的训练时间会非常巨大。在本实验中,经过测试将400张112*92的图像输入到SVM分类器中进行训练,单次迭代的训练时间超过2小时,通过这种暴力训练的方式是非常不合理。因此,需要对图像进行降维。 在实验过程中可以发现:识别率会随着维度的升高达到高值,然后又会随着维度的升高有所降低,然后趋于稳定。这个原因可能是高维数据存在一些噪声,这会对SVM分类器的训练产生一定的影响,进而导致识别率的下降。当然,这也证明了SVM分类器不是越高维的数据分类越准确,要训练出效果很好的SVM分类器,还需要重点考量一下目标维数的问题。 通过每个数据集的识别率横向比较:对于高维数据,软间隔SVM比硬间隔SVM更具有优势,识别率更高。
上表可见:数据降维对于SVM分类器而言是非常必要的。对SVM分类器而言,运算的时间复杂度取决于输入数据的维数n,不同的解法有不同的时间复杂度,常见的解法都在O(n)- O(n^3)之间。如果直接将局部特征提取的结果作为输入,那么SVM的训练时间会非常巨大。在本实验中,经过测试将400张112*92的图像输入到SVM分类器中进行训练,单次迭代的训练时间超过2小时,通过这种暴力训练的方式是非常不合理。因此,需要对图像进行降维。 在实验过程中可以发现:识别率会随着维度的升高达到高值,然后又会随着维度的升高有所降低,然后趋于稳定。这个原因可能是高维数据存在一些噪声,这会对SVM分类器的训练产生一定的影响,进而导致识别率的下降。当然,这也证明了SVM分类器不是越高维的数据分类越准确,要训练出效果很好的SVM分类器,还需要重点考量一下目标维数的问题。 通过每个数据集的识别率横向比较:对于高维数据,软间隔SVM比硬间隔SVM更具有优势,识别率更高。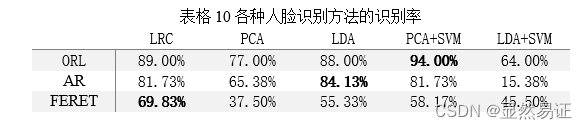
 解决方法就是可以LDA减法模型,减法模型中没有求逆的操作,所以不会报错。
解决方法就是可以LDA减法模型,减法模型中没有求逆的操作,所以不会报错。
【本文地址】