| 基于python+协同过滤+爬虫+django框架的招聘岗位推荐系统的设计与实现 | 您所在的位置:网站首页 › 推荐系统架构招聘 › 基于python+协同过滤+爬虫+django框架的招聘岗位推荐系统的设计与实现 |
基于python+协同过滤+爬虫+django框架的招聘岗位推荐系统的设计与实现
|
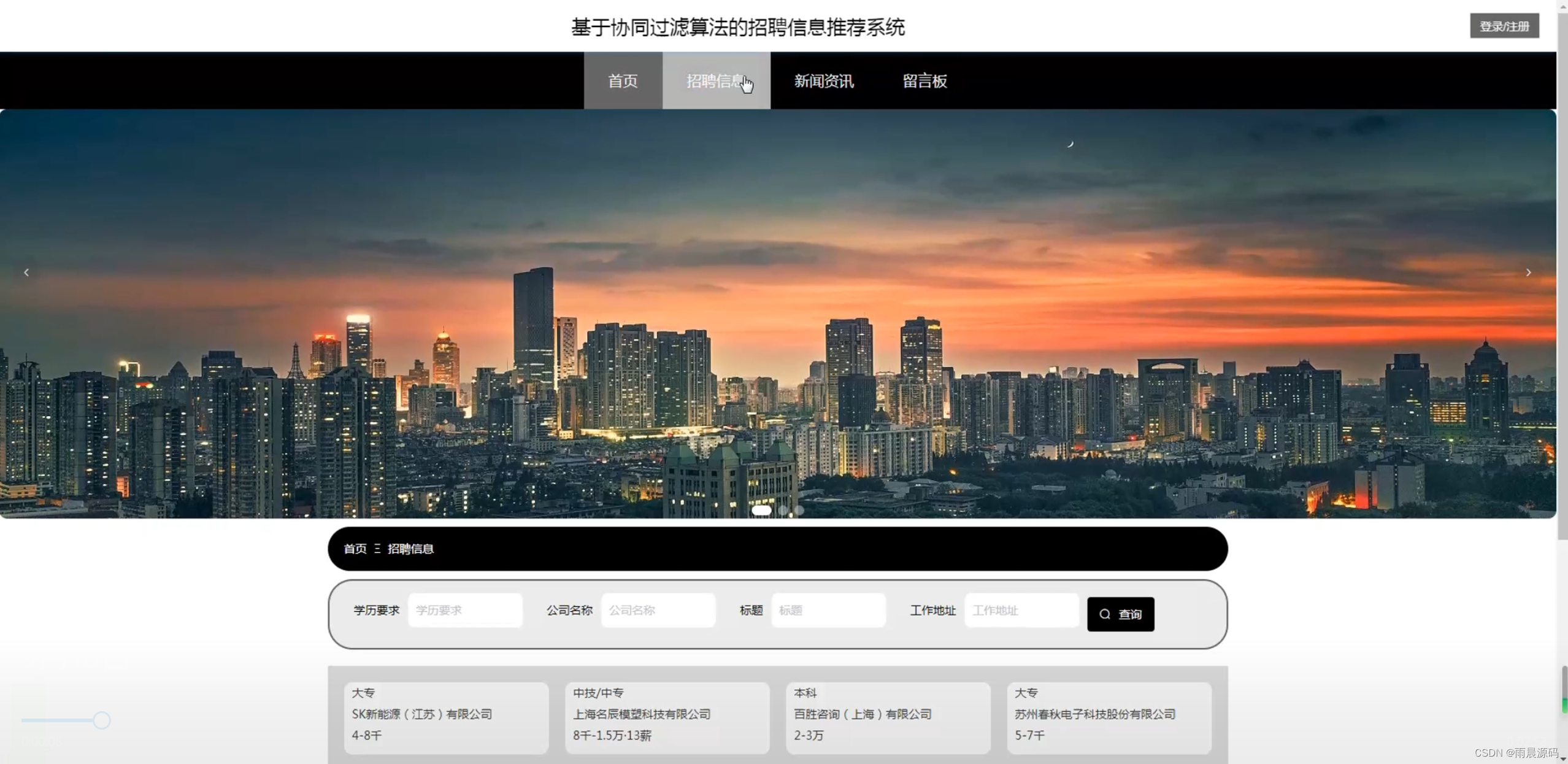
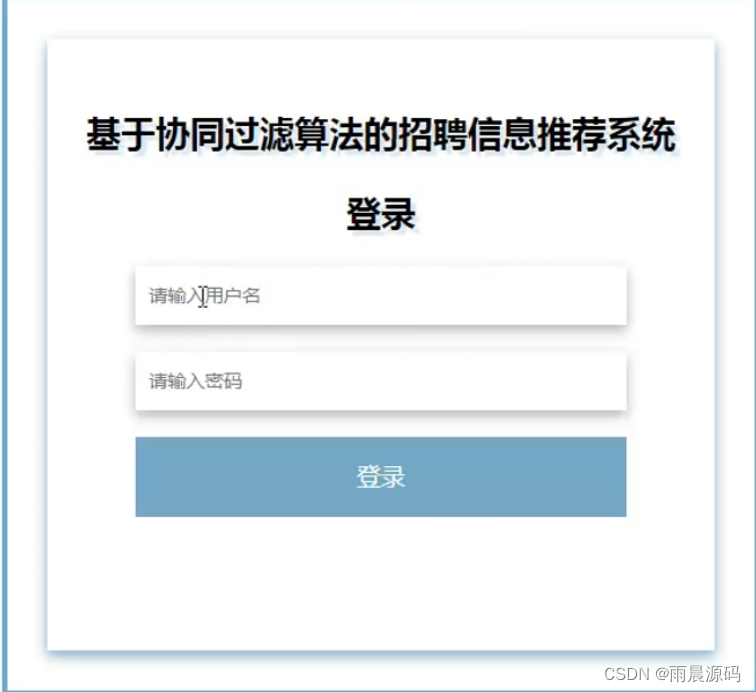
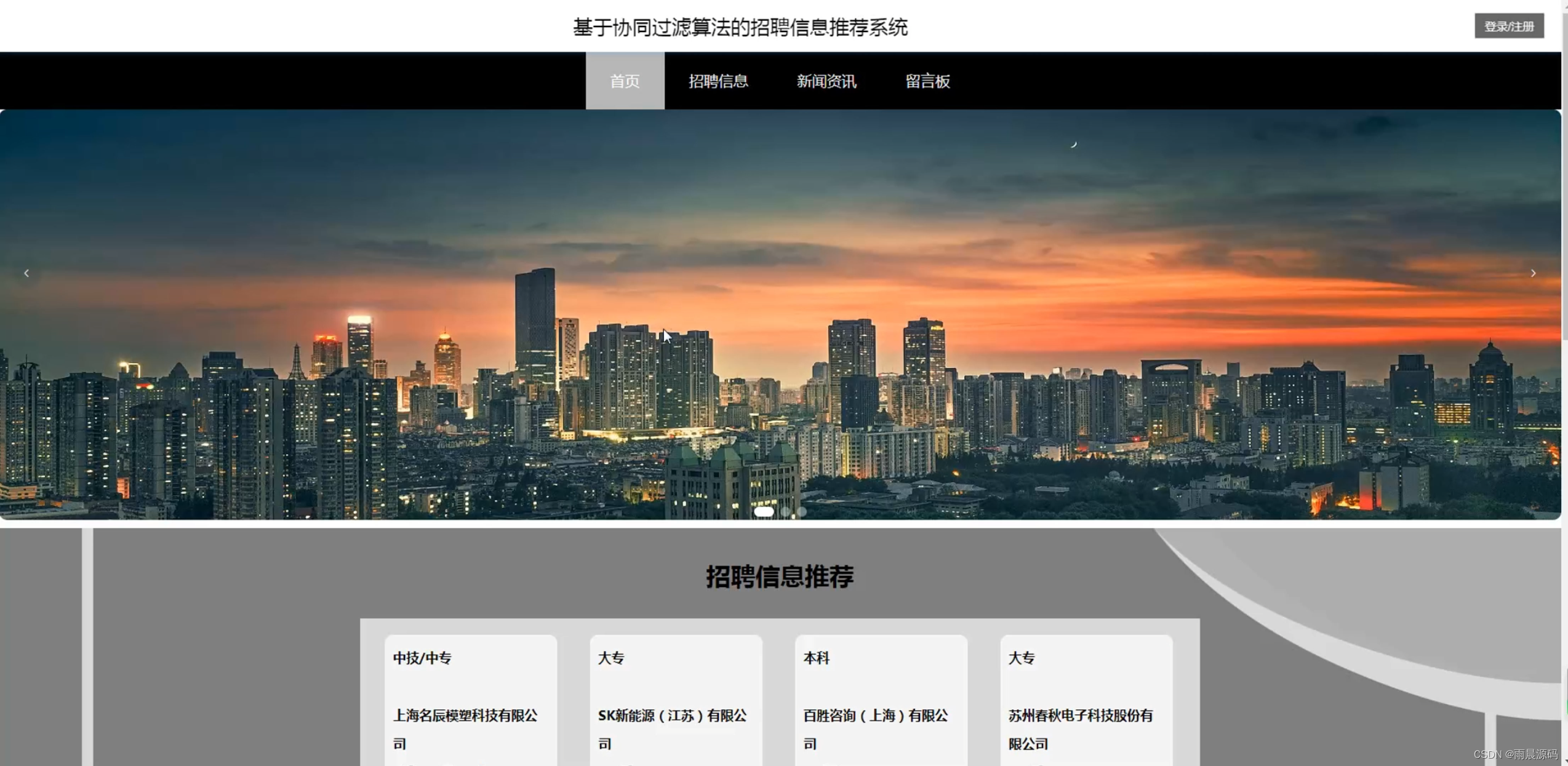
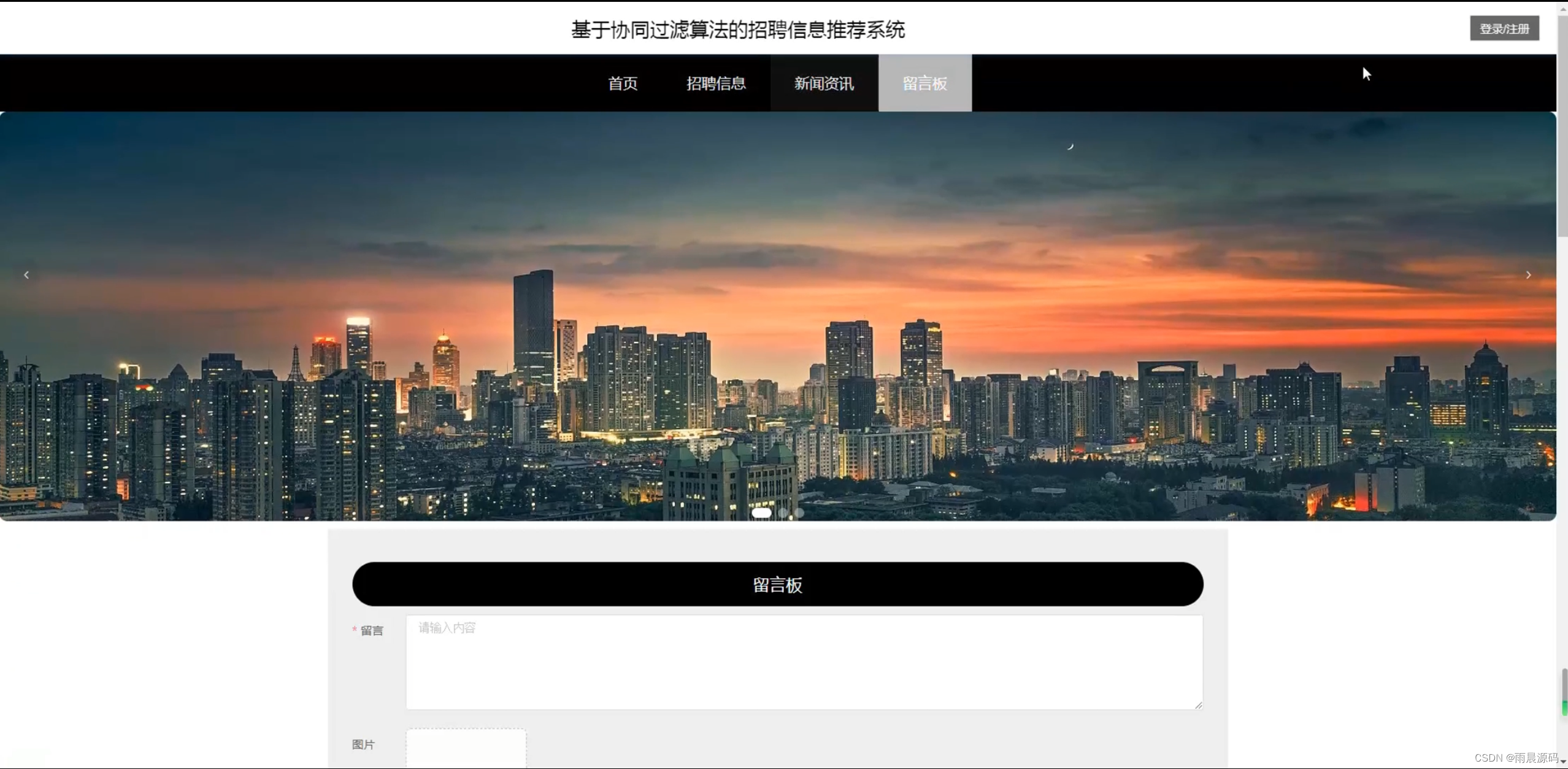
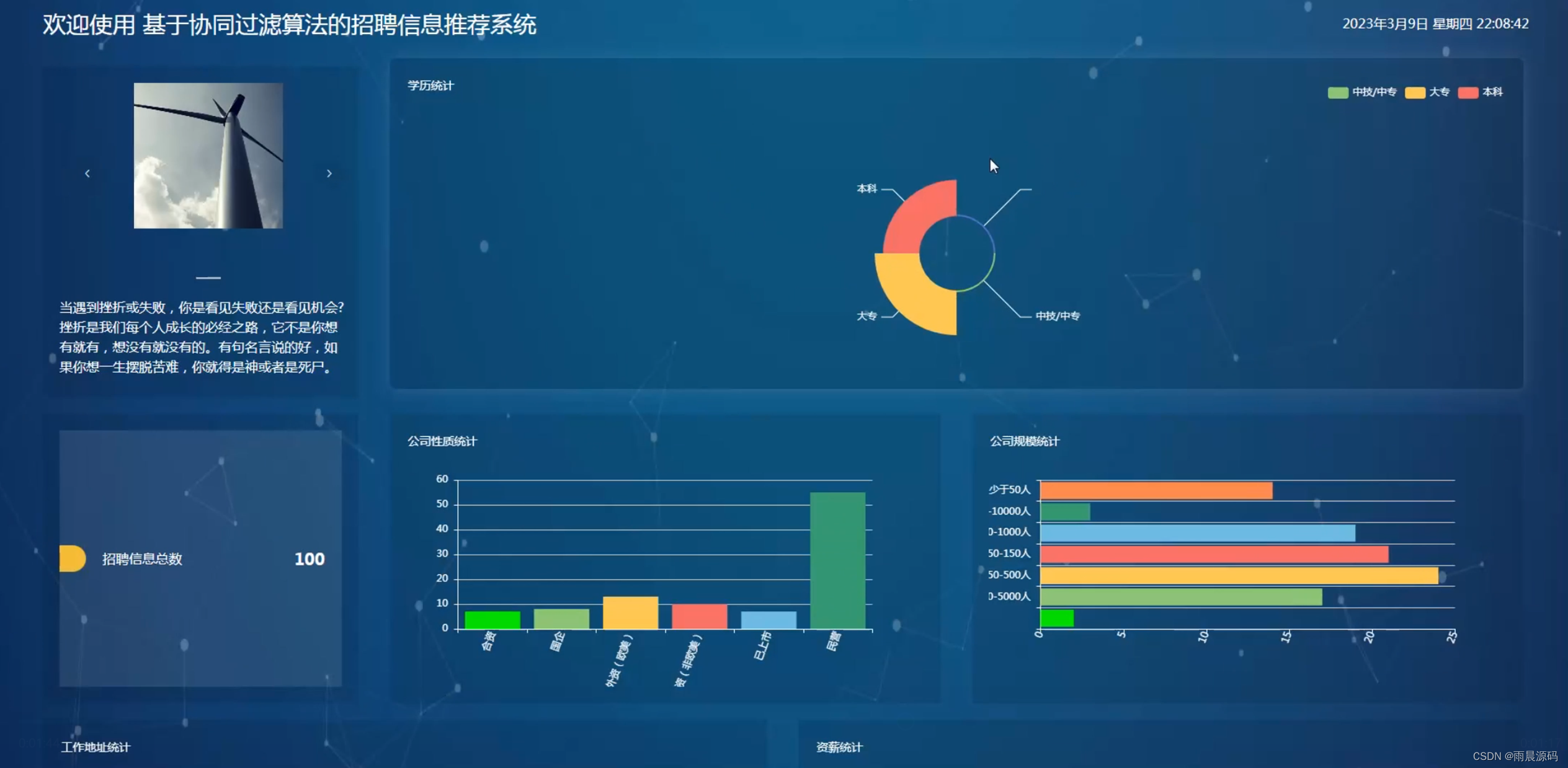
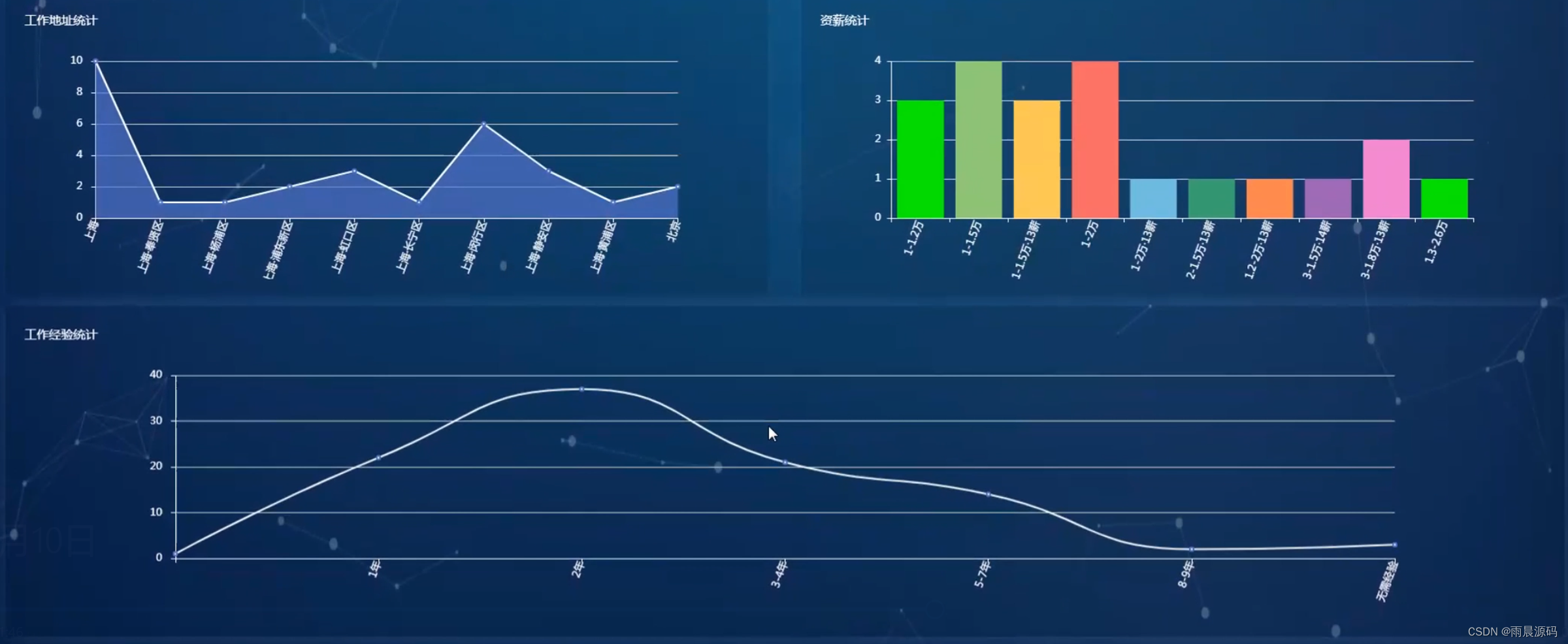
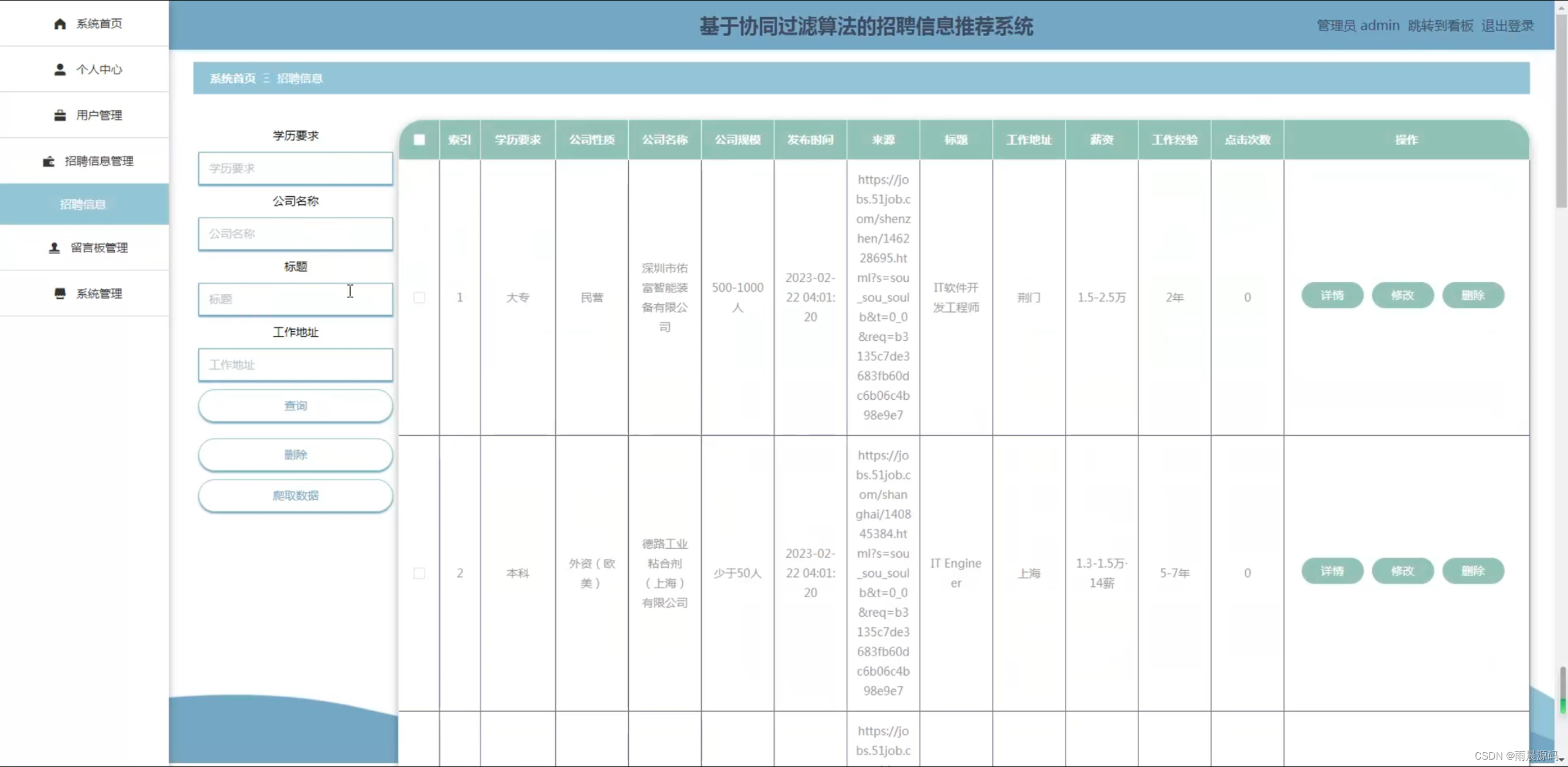
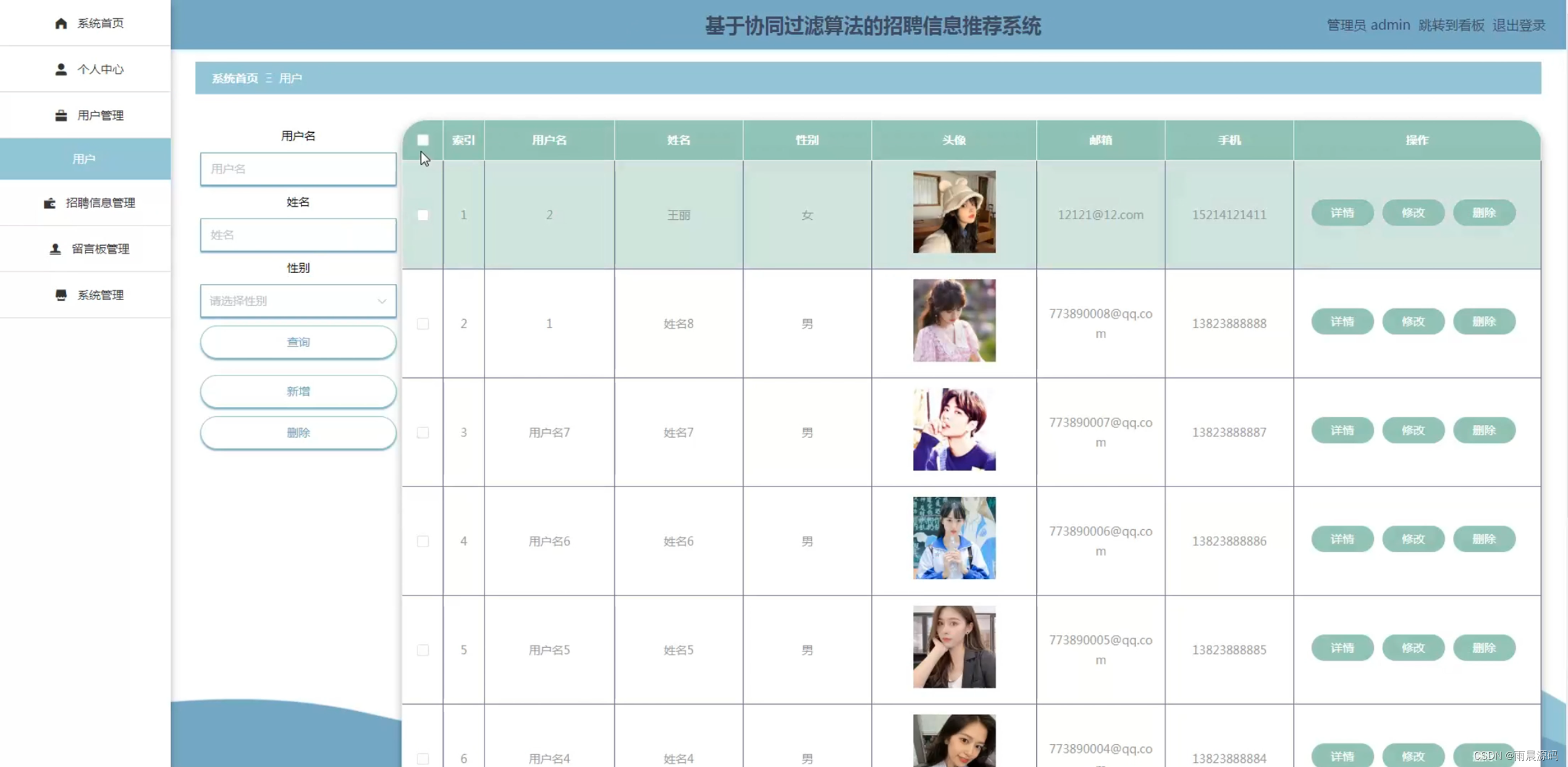
🔥作者:雨晨源码🔥 💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖 精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻 Java精彩实战毕设项目案例 小程序精彩项目案例 Python实战项目案例 💕💕文末获取源码 文章目录 招聘岗位推荐系统-系统前言简介招聘岗位推荐系统-开发技术与环境招聘岗位推荐系统-功能介绍招聘信息推荐系统-演示图片招聘岗位推荐系统-论文参考招聘岗位推荐系统-代码展示招聘岗位推荐系统-结语(文末获取源码)本次文章主要是介绍Python招聘岗位推荐系统的功能,系统分为二个角色,分别是用户和管理员 招聘岗位推荐系统-系统前言简介 在过去的几十年里,招聘一直是组织和个人生涯规划中至关重要的环节。然而,随着互联网的普及,招聘信息的数量和复杂性急剧增加,导致了信息过载和招聘效率下降的问题。传统的招聘流程涉及大量的人工干预,从发布招聘广告到筛选简历和面试候选人,都需要大量时间和精力。因此,需要一种智能化的系统来帮助企业更有效地寻找合适的候选人,同时也使求职者能够更轻松地找到符合他们需求的职位。本招聘信息推荐系统的研发具有重要的实际意义。首先,它可以帮助企业降低招聘成本,提高招聘效率,更精准地匹配职位和候选人。其次,对于求职者来说,系统将提供个性化的招聘建议,帮助他们更快地找到符合自己技能和兴趣的工作。最重要的是,这个系统将促进人才的流动,为企业和求职者之间的匹配提供更多可能性,促进经济的发展。目前,招聘信息推荐系统已经在一些大型招聘平台和企业中得到应用,但仍然存在许多挑战。现有的系统往往面临数据质量、推荐准确性和用户隐私等方面的问题。因此,本研究旨在构建一个基于Python、协同过滤、爬虫和Django的全面招聘信息推荐系统,以解决这些问题并提高招聘过程的效率。通过深入研究和创新,我们将为招聘领域的发展做出贡献,推动招聘信息推荐技术的进步,使其更好地服务于企业和求职者。 招聘岗位推荐系统-开发技术与环境 开发语言:Python后端框架:Django、爬虫前端:vue数据库:MySQL系统架构:B/S开发工具:jdk1.8、Tomcat8.5(内置)、Navicat,IDEA(Eclipse、MyEclipse )选其一 招聘岗位推荐系统-功能介绍2个角色:用户/管理员(亮点:协同过滤+爬虫+可视化分析) 用户:登录注册、招聘信息浏览、招聘推荐、新闻资讯、留言板。 管理员:系统首页数据分析(学历统计、公司性质统计、公司规模统计、工作地址统计、薪资统计、工作经验统计)、招聘管理、用户管理、个人中心、留言板管理、系统管理等。 招聘信息推荐系统-演示图片1.用户端页面: ☀️首页☀️ ☀️登录☀️ ☀️招聘信息推荐☀️ ☀️留言板☀️ 2.管理员端页面: ☀️可视化大屏☀️ ☀️岗位管理☀️ ☀️用户管理☀️ ☀️留言管理☀️
1.招聘爬虫解析【代码如下(示例):】 # 招聘信息 class ZhaopinxinxiSpider(scrapy.Spider): name = 'zhaopinxinxiSpider' spiderUrl = 'https://cupid.51job.com/open/noauth/search-pc?api_key=51job×tamp=1677042252&keyword=IT&searchType=2&function=&industry=&jobArea=000000&jobArea2=&landmark=&metro=&salary=&workYear=°ree=&companyType=&companySize=&jobType=&issueDate=&sortType=0&pageNum={}&requestId=93c1897338e6048f265dfc743365ecb2&pageSize=50&source=1&accountId=&pageCode=sou%7Csou%7Csoulb' start_urls = spiderUrl.split(";") protocol = '' hostname = '' headers = { "Referer":"https://we.51job.com/", "sign":"1b6fc833afc4bbdfeb814c2d29fd34a1015e8d21eb0f1e7d61f45cd504c12f5f" } def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) def start_requests(self): plat = platform.system().lower() if plat == 'linux' or plat == 'windows': connect = self.db_connect() cursor = connect.cursor() if self.table_exists(cursor, '05zp2_zhaopinxinxi') == 1: cursor.close() connect.close() self.temp_data() return pageNum = 1 + 1 for url in self.start_urls: if '{}' in url: for page in range(1, pageNum): next_link = url.format(page) yield scrapy.Request( url=next_link, headers=self.headers, callback=self.parse ) else: yield scrapy.Request( url=url, callback=self.parse ) # 列表解析 def parse(self, response): _url = urlparse(self.spiderUrl) self.protocol = _url.scheme self.hostname = _url.netloc plat = platform.system().lower() if plat == 'windows_bak': pass elif plat == 'linux' or plat == 'windows': connect = self.db_connect() cursor = connect.cursor() if self.table_exists(cursor, '05zp2_zhaopinxinxi') == 1: cursor.close() connect.close() self.temp_data() return data = json.loads(response.body) list = data["resultbody"]["job"]["items"]2.招聘智能推荐功能【代码如下(示例):】 def zhaopinxinxi_autoSort(request): ''' .智能推荐功能(表属性:[intelRecom(是/否)],新增clicktime[前端不显示该字段]字段(调用info/detail接口的时候更新),按clicktime排序查询) 主要信息列表(如商品列表,新闻列表)中使用,显示最近点击的或最新添加的5条记录就行 ''' if requesthod in ["POST", "GET"]: msg = {"code": normal_code, "msg": mes.normal_code, "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}} req_dict = request.session.get("req_dict") if "clicknum" in zhaopinxinxi.getallcolumn(zhaopinxinxi,zhaopinxinxi): req_dict['sort']='clicknum' elif "browseduration" in zhaopinxinxi.getallcolumn(zhaopinxinxi,zhaopinxinxi): req_dict['sort']='browseduration' else: req_dict['sort']='clicktime' req_dict['order']='desc' msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \ msg['data']['pageSize'] = zhaopinxinxi.page(zhaopinxinxi,zhaopinxinxi, req_dict) return JsonResponse(msg) def zhaopinxinxi_list(request): ''' 前台分页 ''' if requesthod in ["POST", "GET"]: msg = {"code": normal_code, "msg": mes.normal_code, "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}} req_dict = request.session.get("req_dict") if req_dict.__contains__('vipread'): del req_dict['vipread'] #获取全部列名 columns= zhaopinxinxi.getallcolumn( zhaopinxinxi, zhaopinxinxi) #表属性[foreEndList]前台list:和后台默认的list列表页相似,只是摆在前台,否:指没有此页,是:表示有此页(不需要登陆即可查看),前要登:表示有此页且需要登陆后才能查看 try: __foreEndList__=zhaopinxinxi.__foreEndList__ except: __foreEndList__=None if __foreEndList__=="前要登": tablename=request.session.get("tablename") if tablename!="users" and 'userid' in columns: try: req_dict['userid']=request.session.get("params").get("id") except: pass #forrEndListAuth try: __foreEndListAuth__=zhaopinxinxi.__foreEndListAuth__ except: __foreEndListAuth__=None #authSeparate try: __authSeparate__=zhaopinxinxi.__authSeparate__ except: __authSeparate__=None if __foreEndListAuth__ =="是" and __authSeparate__=="是": tablename=request.session.get("tablename") if tablename!="users": req_dict['userid']=request.session.get("params",{"id":0}).get("id") tablename = request.session.get("tablename") if tablename == "users" and req_dict.get("userid") != None:#判断是否存在userid列名 del req_dict["userid"] else: __isAdmin__ = None allModels = apps.get_app_config('main').get_models() for m in allModels: if m.__tablename__==tablename: try: __isAdmin__ = m.__isAdmin__ except: __isAdmin__ = None break if __isAdmin__ == "是": if req_dict.get("userid"): # del req_dict["userid"] pass else: #非管理员权限的表,判断当前表字段名是否有userid if "userid" in columns: try: pass except: pass #当列属性authTable有值(某个用户表)[该列的列名必须和该用户表的登陆字段名一致],则对应的表有个隐藏属性authTable为”是”,那么该用户查看该表信息时,只能查看自己的 招聘岗位推荐系统-结语(文末获取源码)💕💕 Java精彩实战毕设项目案例 小程序精彩项目案例 Python实战项目集 💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。 |

【本文地址】
公司简介
联系我们