| RecHub推荐项目学习1:Torch | 您所在的位置:网站首页 › 推荐模型定义 › RecHub推荐项目学习1:Torch |
RecHub推荐项目学习1:Torch
|
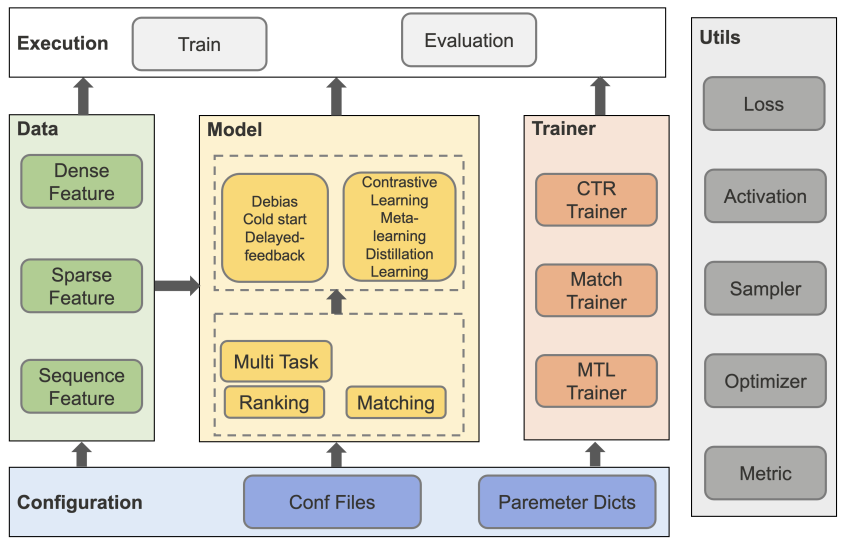
Task01 Task01:熟悉Torch-RecHub框架设计与使用方法 参考资料:0613晚直播讲解,直播ppt,RecHub源码 Torch-RecHub 简介一句话概括:一个轻量级的pytorch推荐模型框架(详见ppt)。 比较认可的一点是:“模型训练与模型定义解耦,无basemodel概念,易拓展”,因为之前接触过 RUC 的开源框架 Recbole ,emm只能说对新手不是很友好(但不否认是一个伟大的开源项目),不友好主要就体现在各种 basemodel 的封装继承导致比较难修改。 Torch-RecHub 框架框架图
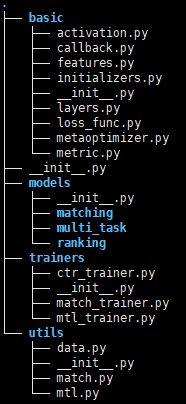
从框架图可以看出,数据(特征工程、预处理)、模型定义、模型训练三部分是完全解耦的,除此之外还有 utils ,包含了损失函数、激活函数、优化器、采样器、评估等其它功能,可能因为东西比较多所以统一叫 utils 吧。 查看项目文件树
框架图体现设计思路,实际项目文件结构没有严格按照框架图来设计,还是有一些差别的。 Data (数据)模块没有独立的 module ,预处理似乎是写到了 examples 里(毕竟每个数据集的处理方式都不一样,难以统一),三种 Feature 的处理写在了 basic/features.py 里。 框架图里 Utils 的功能基本都写在了 basic 里 Toy example以 dataset=ml-1m, model=GRU4Rec 为例介绍整个 pipeline。 文件位于 examples/matching/run_ml_gru4rec.py 为了和框架图对应上,本人将 pipeline 分为三个环节:定义阶段、训练阶段、推理阶段。定义阶段里定义了 Torch-RecHub 架构里最核心的三个模块, Data 、Model 和 Trainer;训练阶段做训练模型;推理阶段做模型评估。
下面是主体代码,将逐步介绍。 1234567891011121314151617181920212223242526272829303132333435363738394041#========== 1.定义阶段 ==========## 数据预处理和特征工程user_features, history_features, item_features, neg_item_feature, x_train, y_train, all_item, test_user = get_movielens_data(dataset_path)# 定义 DataGenerator (Dataset + Dataloader)dg = MatchDataGenerator(x=x_train, y=y_train)# 定义 modelmodel = GRU4Rec(user_features, history_features, item_features, neg_item_feature, user_params={"dims": [128, 64, 16]}, temperature=0.02)# 定义 trainer#mode=1 means pair-wise learningtrainer = MatchTrainer(model, mode=2, optimizer_params={ "lr": learning_rate, "weight_decay": weight_decay }, n_epoch=epoch, device=device, model_path=save_dir, gpus=[0])train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=batch_size, num_workers=0)#========== 2.训练阶段 ==========#trainer.fit(train_dl)#========== 3.推理阶段 ==========## model inferenceprint("inference embedding")user_embedding = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=save_dir)item_embedding = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=save_dir)print(user_embedding.shape, item_embedding.shape)# 保存 embedding#torch.save(user_embedding.data.cpu(), save_dir + "user_embedding.pth")#torch.save(item_embedding.data.cpu(), save_dir + "item_embedding.pth")# evaluatematch_evaluation(user_embedding, item_embedding, test_user, all_item, topk=10) 1.定义阶段Data预处理和特征工程123#========== 1.定义阶段 ==========## 数据预处理和特征工程user_features, history_features, item_features, neg_item_feature, x_train, y_train, all_item, test_user = get_movielens_data(dataset_path)这个示例使用的数据集是 Movielens,调用get_movielens_data()函数进行预处理,代码里比较通用的部分在于提取三种特征:Dense Feature 、 Sparse Feature 和 Sequence Feature。 Dense Feature:数值型特征,例如年龄、薪资、日点击量等。 这里好像已经把所有 dense 特征都处理成 sparse 了。 Sparse Feature:类别型特征,例如城市、学历、性别等。主要使用了 sklearn 的 LabelEncoder。 123456789101112from sklearn.preprocessing import MinMaxScaler, LabelEncoderfeature_max_idx = {}for feature in sparse_features: lbe = LabelEncoder() data[feature] = lbe.fit_transform(data[feature]) + 1 # lbe默认从0开始编号,这里+1表示从1开始编号 feature_max_idx[feature] = data[feature].max() + 1 if feature == user_col: user_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode user id: raw user id if feature == item_col: item_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode item id: raw item idnp.save("./data/ml-1m/saved/raw_id_maps.npy", (user_map, item_map)) # 保存 user_id 和 item_id 的索引这里需要留意两点,第一,所有类别特征都从 1 开始编号。第二,user_id 和 item_id 也作为 Sparse Feature 来处理,并且保存了 user_id 和 item_id 的索引。 Sequence Feature:序列特征,分为有序(时序)兴趣序列:例如最近一周点击过的 item list 和 无序标签特征:例如电影类型(动作|悬疑|犯罪)。 1234567891011121314151617if load_cache: #if you have run this script before and saved the preprocessed data x_train, y_train, x_test = np.load("./data/ml-1m/saved/data_cache.npy", allow_pickle=True)else: #Note: mode=2 means list-wise negative sample generate, saved in last col "neg_items" df_train, df_test = generate_seq_feature_match(data, user_col, item_col, time_col="timestamp", item_attribute_cols=[], sample_method=1, mode=2, neg_ratio=3, min_item=0) x_train = gen_model_input(df_train, user_profile, user_col, item_profile, item_col, seq_max_len=50, padding='post', truncating='post') y_train = np.array([0] * df_train.shape[0]) #label=0 means the first pred value is positiva sample x_test = gen_model_input(df_test, user_profile, user_col, item_profile, item_col, seq_max_len=50, padding='post', truncating='post') np.save("./data/ml-1m/saved/data_cache.npy", (x_train, y_train, x_test))调用 torch_rechub/utils/match.py 的 generate_seq_feature_match 函数构建序列特征。该函数主要实现以下功能: 提取点击序列特征 具体地,对每个 user 在规定时间段内的点击序列用留一法进行切分,即最后一次点击作为测试集 label ,前 n-1 次作为测试集序列;用 数据增强 的方式生成训练集。举个例子比较容易说明,例如用户依次点击了 [A, C, B, D, E],那么很自然地得到一条训练集:[A, C, B, D] —> E ,用 [A, C, B, D] 作为输入,预测 label = E。数据增强的意思是,除了将最后一个标签作为 label 外,每个标签(除第一次点击以外)也都可以作为 label ,label 之前的序列都当作输入。这个例子里就可以额外产生:[A, C, B]—> D, [A, C]—> B ,[A]—> C。所以由 [A, C, B, D, E] 可以生成E、D、B、C 为 label 的四条训练数据。只不过为了训练和评估模型,把 [A, C, B, D] —> E 当作测试集了。 提取无序标签特征 其实也是有序的,把标签特征也当作序列里的 item 。 line 118:sample.append(hist[attr_col].tolist()[:i]) 负采样 提供了三种负采样方式,point-wise、pair-wise 和 list-wise。 调用 gen_model_input ,对序列进行 truncating 和 padding,生成训练集和测试集,最后输出的是 pandas.DataFrame 格式。 最后再对上面三种特征进行封装,对 Sparse Feature 主要定义了每个特征的词表大小、 embedding 维度、embedding 初始化方法,对 Sequence Feature 还定义了 pooling 的方式,目前支持 [“mean”, “sum”, “concat”] 三种方式。 定义 DataGenerator12345# 定义 DataGenerator (Dataset + Dataloader)# 1.dg = MatchDataGenerator(x=x_train, y=y_train)# 2.train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=batch_size, num_workers=0)DataGenerator 主要继承了 torch 的 Dataset 类和 Dataloader 类,最终会返回三个 dataloader,分别是训练集 dataloader 、测试集 dataloader 和 item_dataloader,前两个比较好理解,最后一个 item_dataloader Model定义模型12# 定义 modelmodel = GRU4Rec(user_features, history_features, item_features, neg_item_feature, user_params={"dims": [128, 64, 16]}, temperature=0.02)所有模型都在 torch_rechub/models 下,都可以直接 call (所有计算都在 model.forward() 里) Train定义训练器1234567891011# 定义 trainertrainer = MatchTrainer(model, mode=2, optimizer_params={ "lr": learning_rate, "weight_decay": weight_decay }, n_epoch=epoch, device=device, model_path=save_dir, gpus=[0])Trainer 主要定义了模型训练的有关参数,比如:训练模式:{0:point-wise, 1:pair-wise, 2:list-wise},不同训练模式决定使用不同的损失函数;学习率;权重衰减系数;训练轮次;训练设备;gpu编号等。 Trainer 的方法有 fit(用于训练)、evaluate(用于评估)、predict(用于预测)、inference_embedding(用于推断),但是似乎这个代码只用到了 fit 和 inference_embedding,evaluate 和 predict 的具体用法还不清楚,predict 和 inference_embedding 的区别也不清楚。 2. 训练阶段Train12#========== 2.训练阶段 ==========#trainer.fit(train_dl)只需要调用 trainer.fit() 3. 推理阶段Evaluation12345678910111213#========== 3.推理阶段 ==========## model inferenceprint("inference embedding")user_embedding = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=save_dir)item_embedding = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=save_dir)print(user_embedding.shape, item_embedding.shape)# 保存 embedding#torch.save(user_embedding.data.cpu(), save_dir + "user_embedding.pth")#torch.save(item_embedding.data.cpu(), save_dir + "item_embedding.pth")# evaluatematch_evaluation(user_embedding, item_embedding, test_user, all_item, topk=10)user_embedding 和 item_embedding 分别调用不同模式(mode=[“user”, “item”])的 model 推理得到。这似乎是双塔特有的方式:user 和 item 联合训练,但是推理时解耦,分别推理。(第一次接触双塔的代码,不确定说的对不对…) match_evaluation() 用 annoy 进行向量检索召回 topk 个 item ,接着调用 torch_rechub/basic/metric.py 中的 topk_metrics() 函数评估,涵盖了 NDCG、MRR、Recall、Hit、Precision 。 总结这次任务有赖神直播讲解,讲解后再摸盘整个项目就比较顺利了。于是通过 debug 一个 toy example 大致了解了 Torch-RecHub 项目的架构、工程设计,以及大致的 pipeline。因为我是做会话推荐的,对 GRU4Rec 这个模型比较熟悉,所以上来就用它来当作 example 学习,原以为会很顺利,结果发现在 Model 里使用了我不太熟悉的”双塔结构“,有点懵逼。因为会话推荐任务里,其实没有 user 侧信息,所以根本不需要 model.inference_embedding(),只需要调用 model.predict() 做模型推断,所以刚开始一直没转过弯,也没有理解这两个的区别。后来想起曾经听过赖神的双塔分享,才恍然大悟。。 第一次打卡任务顺利完成!希望可以坚持! |

【本文地址】