| 社交机器人检测:Detect Me If You Can: Spam Bot Detection Using InductiveRepresentation Learning | 您所在的位置:网站首页 › 推特社交机器人是什么 › 社交机器人检测:Detect Me If You Can: Spam Bot Detection Using InductiveRepresentation Learning |
社交机器人检测:Detect Me If You Can: Spam Bot Detection Using InductiveRepresentation Learning
|
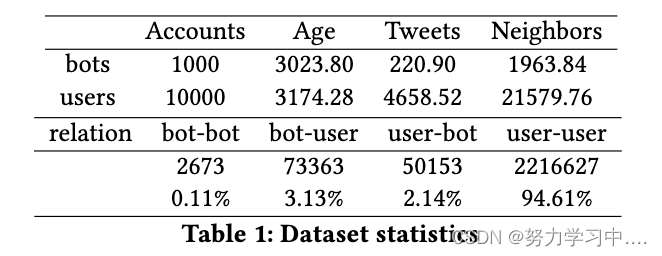
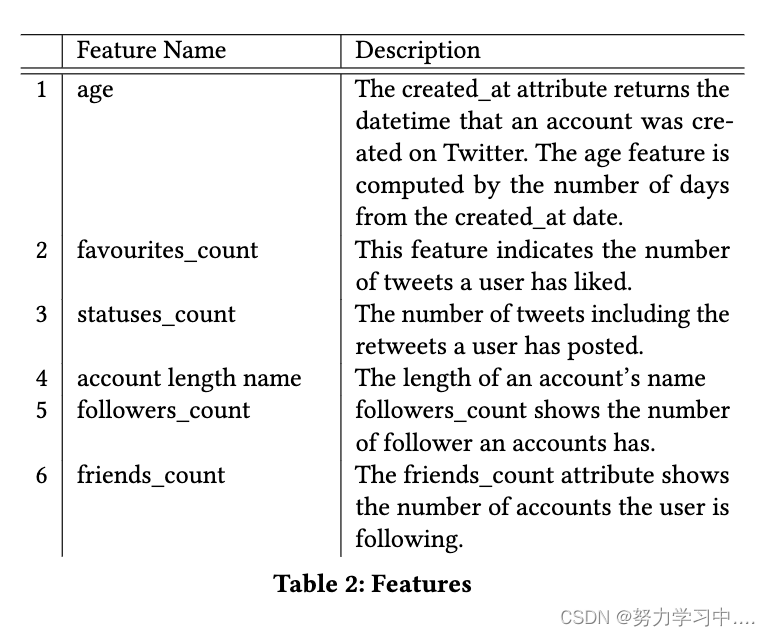
论文链接:Detect Me If You Can: Spam Bot Detection Using Inductive Representation Learning | Companion Proceedings of The 2019 World Wide Web Conference 目录 1 摘要 2 CCS CONCEPTS 3 关键字 4 绪论 5 相关工作 5.1 垃圾邮件检测相关工作 5.2 图卷积神经网络相关工作 6 数据集 7 方法 7.1 问题定义 7.2 Features 8 评估 8.1 与 MLP 和信念传播的比较 9 结论和未来的工作 1 摘要垃圾邮件机器人已经成为在线社交网络的一个威胁,他们的恶意行为,发布错误的信息和影响在线平台来实现他们的动机。 随着时间的推移,垃圾邮件机器人已经变得越来越先进,创建识别机器人的算法仍然是一个公开的挑战。 学习图结构数据中节点的低维嵌入已被证明在各种领域是有用的。 在本文中,我们提出了一个基于图卷积神经网络(GCNN)的垃圾机器人检测模型。我们的假设是,为了更好地检测垃圾邮件机器人,除了定义一个特征集外,还必须考虑到社会图。 GCNN能够同时利用一个节点的特征和一个节点的邻居的特征。我们将我们的方法与两种仅在特征集和图的结构上工作的方法进行比较。据我们所知,这项工作是在垃圾邮件机器人检测中使用图卷积神经网络的首次尝试。 2 CCS CONCEPTS信息系统→社会网络; -安全与隐私→社会网络安全与隐私; -计算方法→神经网络; 3 关键字社会媒体分析,机器人检测,图嵌入,图卷积神经网络 4 绪论在线社交网络(OSN)为个人提供了一种通信手段,使其能够以自由和简单的方式分享信息和表达意见。 推特、脸书和其他社交媒体网站已经改变了我们消费新闻和相互交流的方式。这些平台的重要作用导致利益集团试图影响用户,夺取他们的注意力,并最终改变公众意见。 社交机器人是由计算机程序操作的自动化用户帐户,该程序模仿人类行为,目的是滥用社交媒体平台 。 他们的恶意行为通过广告和诈骗 URL 发送垃圾邮件、宣传特定主题标签、传播错误信息并影响选举,显然已成为在线社交网络的威胁。 研究界已经提出了几种机器人检测方法。这些工作的差异取决于机器人帐户的定义、代表帐户的所选功能集以及用于将机器人帐户与普通用户帐户分类的机器学习算法; 然而,由于几个原因,垃圾邮件机器人检测仍然是一个开放的挑战: 第一个原因依赖于机器人帐户的定义,因为没有单一的定义可以精确地将帐户确定为机器人帐户。这是一个重要的问题,特别是对于建立一个ground truth数据集; 另一个问题是,机器人在避免现有提出的检测方法方面变得更加先进和复杂。事实上,机器人一直在随着时间的推移而发展。 社交机器人能够与其他帐户进行交互,发布不同主题的推文,并像人类一样显示类似的活动。 最近,针对图结构数据的深度学习的进展导致了一种新的表示学习方法,即图卷积网络(Graph Conolution Networks,GCNs)。GCNs的主要思想是根据一个节点的特征和其相邻节点的特征用神经网络在向量空间中表示该节点。GCNs的优点是,它既能抓住节点的特征,又能抓住图的结构,从而学习到节点的低维表示。 在这项工作中,我们提出了一种基于用户配置文件特征和社交网络图的机器人检测的归纳表示学习方法。这项工作的主要贡献总结如下: 我们在文献中使用的众所周知的垃圾邮件机器人数据集上部署了图卷积神经网络。; 我们通过 MLP 分类器将我们的方法与两种算法进行比较,并在数据集上应用信念传播; 我们表明,在我们的方法中使用图结构在垃圾邮件检测中获得了更好的性能; 本文的其余部分的结构如下。首先,我们介绍垃圾邮件机器人检测和图卷积神经网络方面的相关工作。第 3 节详细描述了使用的数据集。在第 4 节中,我们概述了我们的方法。我们在第 5 节中说明了结果,并讨论了我们工作的局限性和对未来工作的建议。最后,我们在第 6 节结束本文。 5 相关工作在这一节中,我们首先回顾了关于垃圾邮件检测的文献,并通过他们对垃圾邮件的定义、使用的特征和他们采用的分类算法来比较每项工作。接下来,我们看一下图卷积网络。 5.1 垃圾邮件检测相关工作论文(Kyumin Lee, Brian David Eoff, and James Caverlee. 2011. Seven months with the devils: a long-term study of content polluters on Twitter. In In AAAI IntâĂŹl Conference on Weblogs and Social Media (ICWSM))提出了一种作为机器人账户的蜜罐陷阱的方法。他们创建了60个twitter账户,并开始发布毫无意义的推文,这些推文对人类来说毫无兴趣。尽管这样,他们还是能够吸引一些账户的注意力来关注他们创建的账户。对这些账户的详细分析表明,它们实际上是试图增加其关注名单的机器人账户。 论文(Chao Yang, Robert Harkreader, and Guofei Gu. 2013. Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. IEEE Transactions on Information Forensics and Security (2013). | Chao Yang, Robert Harkreader, Jialong Zhang, Seungwon Shin, and Guofei Gu. 2012. Analyzing Spammers’ Social Networks for Fun and Profit: A Case Study of Cyber Criminal Ecosystem on Twitter. In Proceedings of the 21st International Conference on World Wide Web (WWW ’12). ACM, New York, NY, USA, 71–80. https://doi.org/10.1145/2187836.2187)对僵尸账户使用了一个保守的定义,即只考虑发布链接到恶意内容的URL的账户。他们还在BayesNet分类器上引入并考虑了几个强大的特征来预测垃圾邮件账户。杨和等人调查了机器人为避免被Twitter发现而采取的不同方法。他们的研究结果表明,机器人倾向于通过购买追随者和发布更多的推文来提高其账户的声誉。 论文(S. Cresci, R. Di Pietro, M. Petrocchi, A. Spognardi, and M. Tesconi. 2016. DNA-Inspired Online Behavioral Modeling and Its Application to Spambot Detection.IEEE Intelligent Systems 31, 5 (Sept 2016), 58–64. https://doi.org/10.1109/MIS.2016.29)引入了一种受 DNA 启发的技术,该技术将每个帐户建模为行为信息序列,并根据相似序列检测垃圾邮件机器人。他们将每个用户的推文分类为不同的类型,并根据推文是否包含 URL、主题标签、图片等,为其分配不同的字符。帐户的相似性由其 DNA 序列中最长的公共子串来衡量。 BotOrNot(Clayton Allen Davis, Onur Varol, Emilio Ferrara, Alessandro Flammini, and Filippo Menczer. 2016. BotOrNot: A System to Evaluate Social Bots. In Proceedings of the 25th International Conference Companion on World Wide Web (WWW ’16 Companion). International World Wide Web Conferences Steering Committee, 273–274. https://doi.org/10.1145/2872518.2889)在1000多个特征上使用随机森林分类器算法来检测机器人。这些特征被分为6组:网络(程度分布,聚类系数, ......),用户的账户信息,朋友(粉丝数量,关注度, ......),时间(推特率, ......),内容(自然语言处理, ......)和情感特征。BotOrNot的缺点是,它是在英语推文上训练的,所以它在用英语以外的其他语言推文的机器人上的表现会下降。 DeBot (N. Chavoshi, H. Hamooni, and A. Mueen. 2016. DeBot: Twitter Bot Detection via Warped Correlation. In 2016 IEEE 16th International Conference on Data Mining (ICDM). 817–822. https://doi.org/10.1109/ICDM.2016.0096 | Nikan Chavoshi, Hossein Hamooni, and Abdullah Mueen. 2017. Temporal Patterns in Bot Activities. In Proceedings of the 26th International Conference on World Wide Web Companion (WWW ’17 Companion). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, Switzerland, 1601–1606. https://doi.org/10.1145/3041021.30)是一个无监督的机器人检测系统。他们的工作背后的想法是,在他们的活动(推文、转推……)中具有高度相关性的帐户很有可能成为机器人。DeBot监测账户在特定时期的活动,并为每个账户创建一个时间序列。然后,它根据账户的时间序列的相似性,使用滞后敏感的散列方法对账户进行聚类。最后,DeBot将具有高相关性的账户报告为机器人。 论文(Real-time Detection of Content Polluters in Partially Observable Twitter Networks)将垃圾邮件机器人定义为出于政治或广告原因试图接管讨论的内容污染者。他们的方法考虑个别推文来检测机器人。他们没有关注朋友和追随者网络,而是创建了一个事件网络,其中节点是用户,边是基于用户对同一事件的推文。他们还根据一条推文提到的URL和标签来计算它的多样性。他们的工作结果表明,垃圾邮件机器人作为一个群体运作,经常在同一时间发推。 5.2 图卷积神经网络相关工作图神经网络是专门用来处理图数据的神经网络架构,给定图的临界矩阵以及每个节点的特征,将这两个输入进行图上的映射,从而得到每个节点下一层的特征,临界矩阵A对输入特征H给每一个节点聚合其自身以及其邻居节点的特征,进而得到其自身的表示(比如在社交网络中,想要知道用户的偏好,不仅要知道其自己的特征,也要知道其好友的偏好,对用户自己便好有重要参考价值); 图卷积神经网络映射函数设计: 图结构被用于许多领域和应用中,如社交网络、推荐系统等。图结构的挑战性任务是如何在机器学习算法中使用它们。 这一领域最初的工作考虑了图的统计数据,如节点的度数、中心度和间性系数作为训练模型的特征。换句话说,他们认为图的结构是提取结构信息的一个预处理步骤。因此,这些方法在学习阶段不使用图结构。这些方法的另一个缺点是,计算图的统计数据具有很高的复杂性,其输出不能用于未见过的数据。 随着卷积神经网络 (CNN) 的最新进展,人们一直在努力将这种流行的深度学习模型用于编码图结构。 已使用两种主要方法将图结构嵌入到维空间中。这些方法之间的区别在于如何定义卷积操作。 第一种方法旨在采用图结构的固定长度节点序列,并直接在欧几里得域中工作的原始 CNN 模型中使用它。或者,其他方法将图结构建模为非欧几里得域。 论文(Thomas N. Kipf and Max Welling. 2016. Semi-Supervised Classification with Graph Convolutional Networks. CoRR abs/1609.02907 (2016). arXiv:1609.02907 http://arxiv.org/abs/1609.02)提出了图卷积网络(GCN);考虑图结构上的谱卷积。使用卷积这个术语是因为节点的邻域被认为是它的表示。他们的方法可以被认为是图半监督分类任务的初始步骤。然而,他们的方法的缺点是它需要计算完整的图拉普拉斯算子,并且每一层中节点的输出嵌入依赖于其在前一层的所有邻居。 最近论文(Inductive Representation Learning on Large Graphs.)引入了 GraphSage;一种节点嵌入算法,它使用神经网络来学习图结构中节点的嵌入。他们的主要贡献是解决了上述限制,并展示了如何聚合来自节点邻域的信息。他们的方法包括两个主要阶段: (1) 定义计算图和训练神经网络。一个节点的邻域结构将定义用于训练神经网络的计算图。目的是建立神经网络,确保相互靠近的节点有相似的嵌入,而相互远离的节点有不同的嵌入; (2)传播对于每个节点,其邻居的信息被聚合并通过第一阶段训练的神经网络。 6 数据集有几个著名的数据集是由不同的再搜索组收集的,专门用于Twitter上的机器人检测。 Lee等人提供了一个社会蜜罐数据集,其中包含大约22000个内容污染者。他们已经收集了账户的元数据和每个账户的推文。然而,在他们发布的数据集中,他们对Twitter账户的ID进行了匿名处理。因此,收集进一步的信息是不可能的; Cresci等人在中研究了不同的Twitter数据集,通过使用一个众包平台,他们对不同类型的账户进行了标注。公布了他们检测到的垃圾邮件账户的Twitter ID; 杨等人。 2013 年收集的 Twitter 垃圾邮件发送者及其数据集包含每个帐户的关注者和粉丝。据我们所知,这是我们发现的为 Twitter 帐户收集此信息的数据集。该工作的作者已经分享了他们的数据集,我们在本文中使用了该数据集。数据集包含 11000 个节点和它们之间的 2342816 条边。 表 1 显示了本文使用的数据集的统计数据。年龄、推文和邻居栏表示每组的平均数量。年龄列是以天为单位报告的帐户的平均年龄,并通过将最早的一天设置为第一天进行标准化。节点之间的大多数边是用户到用户的连接。然而,大约 5.4% 的边缘关系包括机器人帐户。
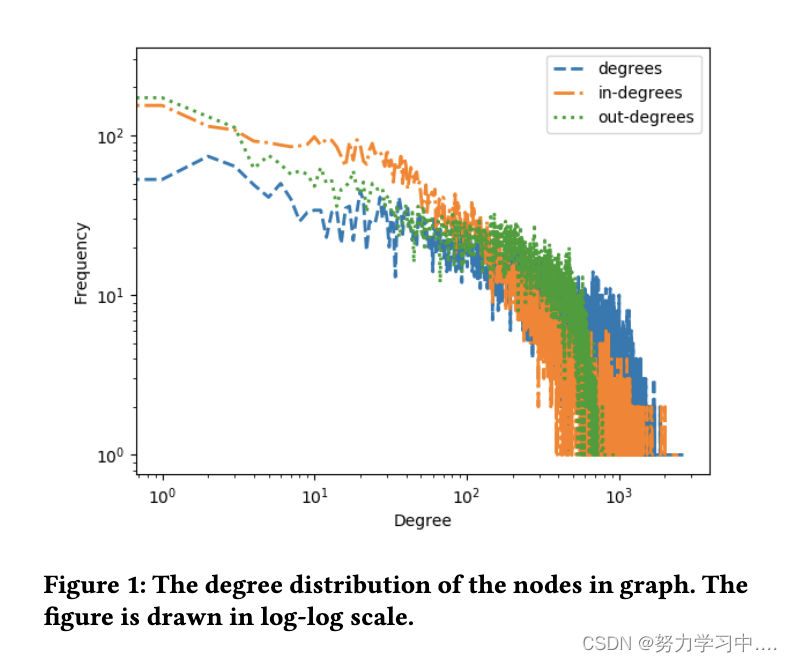
图 1 显示了数据集中账户的度数分布。大多数帐户的关注者和追随者数量很少,少数帐户在其附近拥有超过 1000 个帐户;
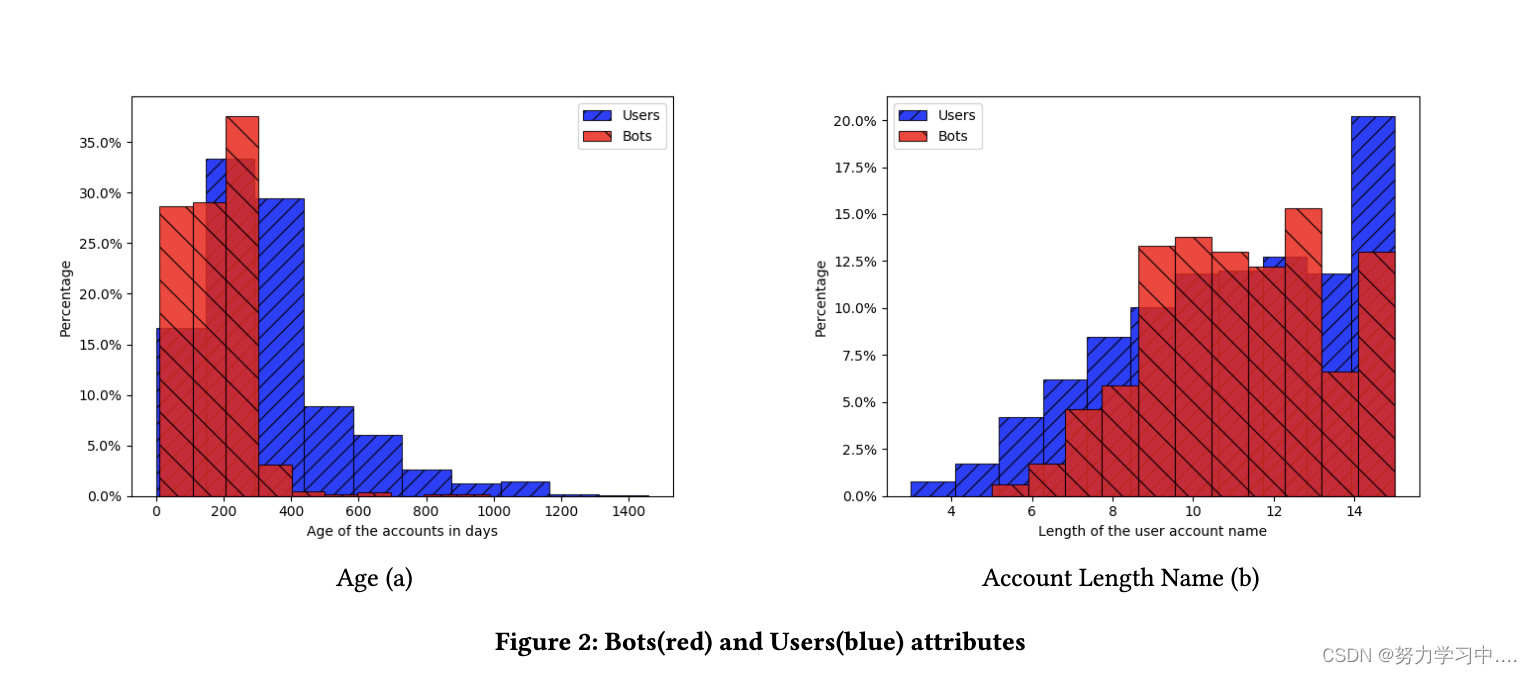
图 2.a 显示了机器人和用户帐户的用户帐户名称的年龄和长度。如图 2.b 所示,并在之前的工作中报告,机器人帐户的年龄较小,这意味着与用户帐户相比,它们是最近创建的。
我们使用类似于(Inductive Representation Learning on Large Graphs. | Representation Learning on Graphs: Methods and Applications. )的归纳表示学习方法来检测 twitter bot 帐户。 7.1 问题定义 令 G =(V ,E) 是一个图,其中对于每个 v ∈ V 存在一个特征向量 与图像处理中的卷积滤波器类似,图卷积网络将节点邻居的属性视为该节点的表示。让我们将 k 定义为从中聚合信息的节点的邻居的深度。如果 k=1,则只考虑来自其自己邻居的信息。对于 k=2,信息也是从其邻居的邻居中收集的,依此类推。每个深度的输出
其中 神经网络基于交叉熵损失函数进行优化: 每个用户的初始向量(
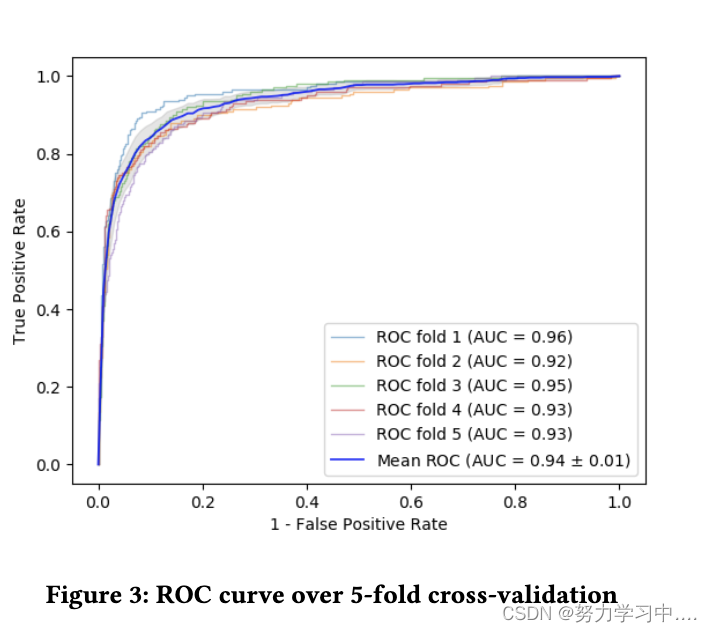
在本节中,我们评估我们方法的性能。我们对数据集进行了 5 折交叉验证,以评估模型的准确性。图 3 显示了每个折叠的曲线下面积。平均而言,GCNN 具有 0.94 的准确度,由 roc 曲线下的面积测量。
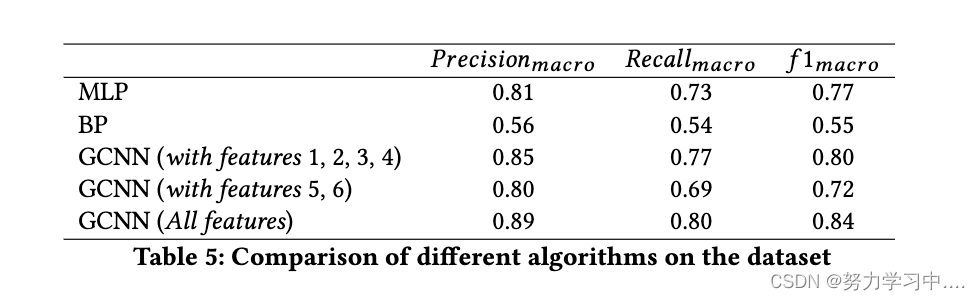
我们测量了准确率、召回率和 f1 指标,如表 5 所示用于评估。为分类任务选择一个有意义的评估指标很重要。例如,可以使用等式 4 中定义的精度度量来评估模型的性能。在这种情况下,度量值是在不考虑类标签的情况下对所有数据进行计算的。
然而,对于大多数标签属于一个类的数据集的这个定义,即使模型没有正确检测到另一类的标签,精度得分仍然很高。因此,为了更好地评估模型,我们分别计算每个类的准确率、召回率、f1 分数,并报告两个类的平均分数。这在 scikit-learn python 库中也称为宏分数:
我们通过与其他两种方法进行比较,进一步评估了我们的方法。 由于图卷积神经网络同时考虑了特征集和图结构,我们通过与多层感知器(MLP)和信念传播(BP)的比较来证明该方法的性能。 MLP分类器是根据特征部分中定义的特征集进行训练的。输入层将每个账户的特征向量归一化为0和1之间的值。隐藏层由两层组成,分别有25个和10个神经元,使用整流的线性单元作为传递函数。对数损失函数使用随机梯度下降法进行优化,学习率为0.0001。 另一方面,信念传播算法只在图的结构上运行。信念传播(BP)算法最初由Judea Pearl(Probabilistic reasoning in intelligent systems: networks of plausible inference. r)提出,通过在图中所有节点对之间反复传递消息,从关于一个节点和其他邻近节点的一些先验知识中推断出该节点的标签。发送的消息表明节点对其邻居的状态的信念。 在本实验中,我们采用了表3和表4所示的原始BP与节点和边缘指标。此外,我们进行了7次迭代的实验,因为在7次迭代之后,节点间传递的信息没有明显的变化。
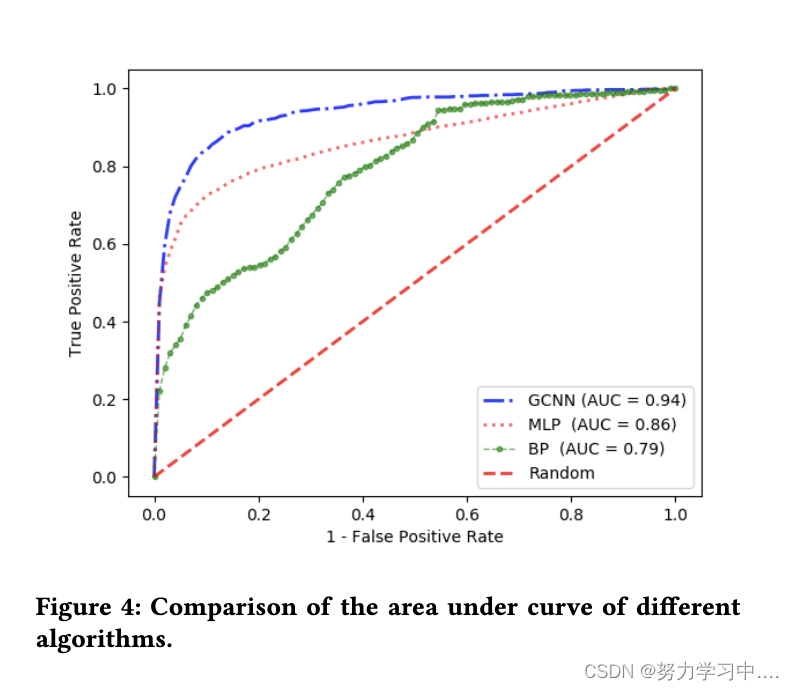
我们绘制了不同模型的接收操作特征(ROC),如图4所示。
我们观察到,GCNN方法的ROC曲线下的面积为94%,比MLP和BP方法分别高出8%和16%。虽然神经网络在各个领域都有良好的表现,但当涉及到它们为什么会产生这样的输出时,它们往往被认为是黑箱。 解释输出的每个条目和生成的嵌入向量的意义仍然是开放的问题,也是未来研究的课题。 9 结论和未来的工作在本文中,我们研究了一种使用图卷积网络检测 Twitter 上的恶意账户和社交机器人的新方法。我们方法的主要思想是利用 Twitter 帐户的图形结构和关系对帐户进行分类。每个帐户都从其邻域聚合特征信息。 我们在以前的一个著名的机器人检测数据集上进行了验证。结果显示,我们的方法优于最先进的分类算法,曲线下面积的准确性提高了8%。由于Twitter API有每15分钟每个速率限制窗口15个请求的限制,基于账户的追随者和朋友关系建立Twitter图结构并不是一件容易的事。我们知道这可能被认为是对我们方法的限制。因此,可以建议根据用户账户的转发图来建立图结构。最后,未来工作的一个具体扩展是在Twitter的流媒体API上实时部署这个方法,以进行垃圾邮件检测。 |

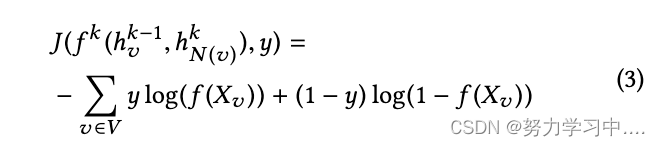
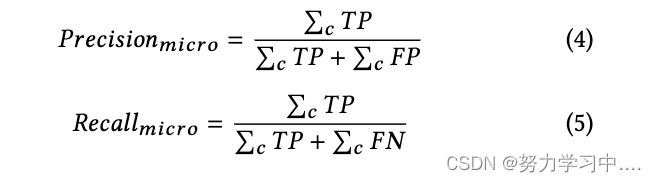
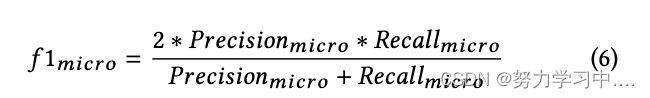


【本文地址】