| 病例对照研究的基本统计分析策略 | 您所在的位置:网站首页 › 探讨探讨图图他 › 病例对照研究的基本统计分析策略 |
病例对照研究的基本统计分析策略
|
比如以下案例: 例1:某医师基于某医院开展病例对照研究,探讨冠心病发病有关的影响因素,收集新发冠心病患者作为病例组,收集同期医院非循环系统疾病患者作为对照组,研究的暴露因素是病人的年龄age、性别sex、心电图检验是否异常ecg、高血压hpyer、糖尿病diabetes。数据见casecontrol.sav。
病例对照研究一般可以同时研究多个暴露因素对结局的影响。本题是传统流行病学的病例对照研究,探讨的是发病的影响因素,从理论上来判断,潜在的影响因素或者原因变量包括性别、年龄、心电图异常状况、高血压、和糖尿病。 本研究的研究结局为二分类数据,暴露因素则存在着定量、二分类和多分类数据。研究影响因素,统计学上是开展差异性或者关联性研究(两组实质一致),分析变量与变量的相关性。 2、统计策略探讨不同类型变量的相关性,统计学方法包括基础统计学方法和高级统计学方法。基础统计学方法探讨的是简单关联性,方法包括t检验、F检验、卡方检验、相关分析等,高级统计学方法常见为回归分析方法。一般情况下,一个完整的分析报告,往往采取基础统计学方法和高级统计学方法相结合的方法。 病例对照洋酒简单关联性方法,应从差异性角度来探讨(差异即相关)。病例对照研究的差异性比较是按照病例/对照分组,即各个暴露因素的在病例组和对照组的分布有无统计学差异。比如病例组和对照组年龄有无差异、性别构成有无统计学差异。 不同组差异性比较,将根据暴露因素变量类型的不同,选择不同的统计学方法。这些差异性方法与实验性研究分析方法无异。 年龄分布的差异:定量数据,应考虑t检验或者秩和 性别分布的差异:二分类数据,卡方 心电图分布的差异:有序多分类,可以考虑卡方或者秩和。不过由于心电图异常各级别非等距,本案例只要分析构成比分布差异即可,因此推荐卡方检验。 糖尿病分布的差异:二分类数据,卡方 高血压病分布的差异:二分类数据,卡方 卡方检验是最常见的病例对照研究统计分析方法,暴露因素与结局往往形成四格表或者多行多列交叉表数据。
高级统计学方法常用的方法包括分层分析、回归分析、倾向得分方法等,最常见也最重要的方法便是回归分析方法。回归分析方法可以同时研究多个影响因素,它较简单关联性分析方法具有明显的优势(多因素线性回归分析,为什么和单因素回归结果不一样?),是病例对照研究的最重要方法。回归分析方法很多,本例研究结局为二分类数据,线性回归分析方法不再适用,应该选择logistic回归分析方法。 无论简单关联性还是logistic回归分析,我们必须关注暴露因素与研究结局的效应值,那就是暴露因素到底在多大程度上影响了研究结局。病例对照研究最重要的效应结局为OR值。 3、OR值病例对照研究几乎都需要计算各个暴露因素的效应值OR值,来反映暴露因素对阳性事件发生的影响。OR值指的是,优势比/比数比(oddsratio,OR)。优势(odds)是指二分类事件中一类事件相对于其对立事件的优势。病例组中优势是暴露者数/非暴露数,对照组中暴露数/非暴露数。 对于上文交叉表而言,OR值计算如下:
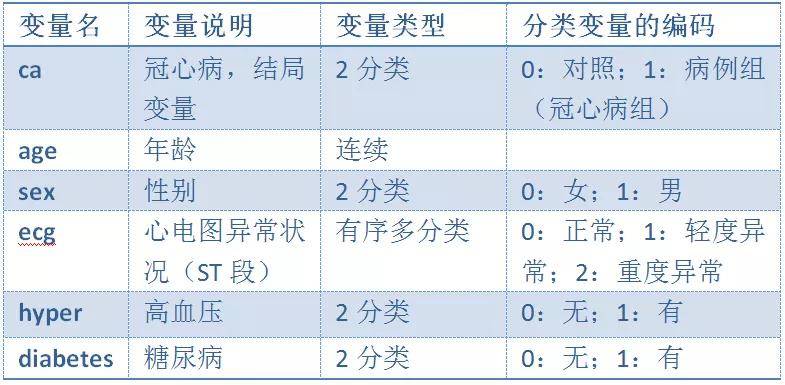
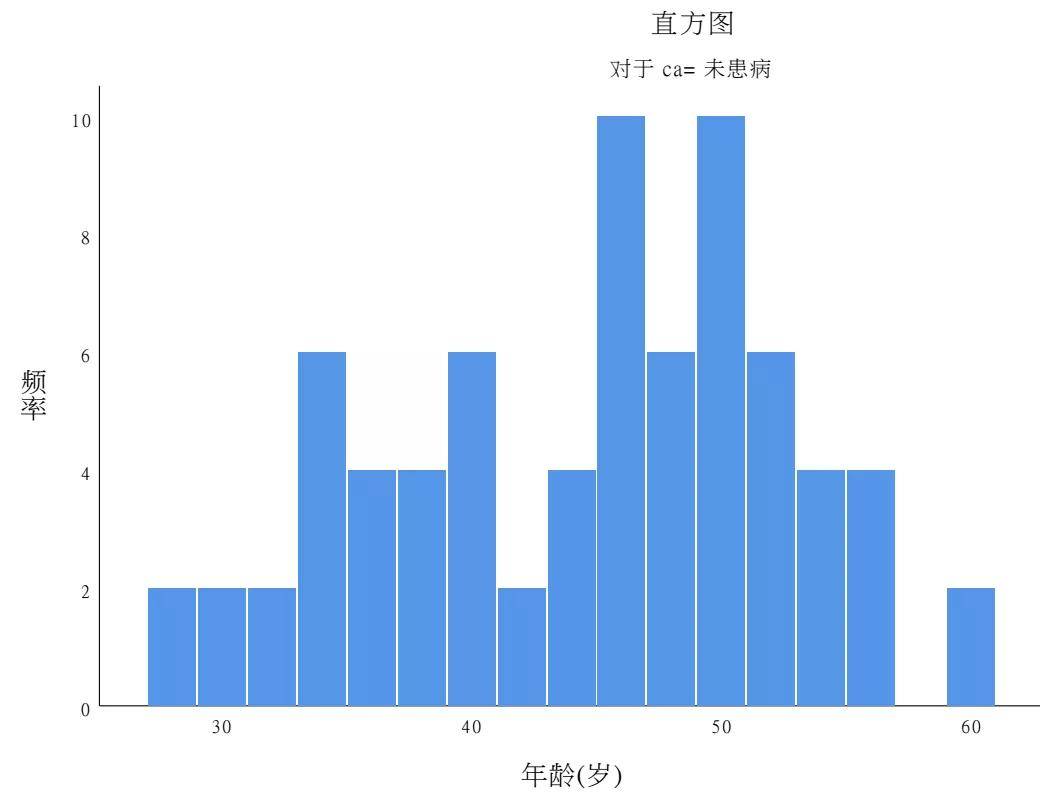
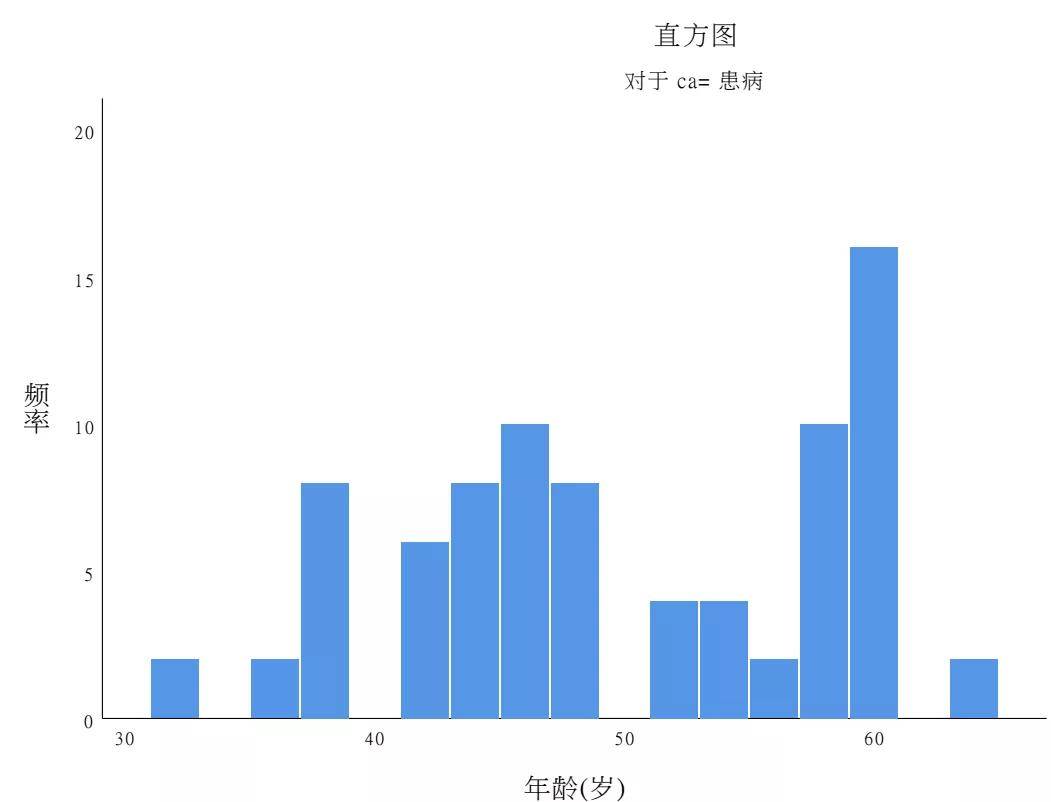
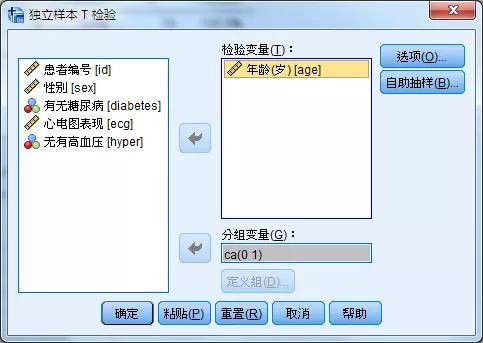
实际上,OR反映的是病例组和对照组暴露人群构成比分布的差异性。若没有差异,则OR等于1;若存在着差异,OR不等于1。 OR值大于1,提示暴露因素是阳性事件的促进因素; OR值小于1,提示暴露因素是阳性事件的预防因素; OR值等于1,提示暴露因素对阳性事件无影响。 这里提醒一下,一般流行病研究教材一般把OR值大于1作为危险因素,小于1作为暴露因素,这种说法不适合现代医学的范畴,请学过流行病学的朋友更新对OR值的理解。 OR值越远离1,暴露因素对结局的影响程度越大,它几乎可以用倍数或者百分比来反映暴露因素相对结局的影响。比如,OR=3,意味着暴露组相对对照组,产生阳性结局的可能性几乎增加2倍;若OR=0.6,意味着暴露组相对对照组,产生阳性结局的可能性几乎减少40%。我将在后文继续探讨OR值这一指标。 OR值是统计量,需要进一步统计推断,包括置信区间估计和假设检验。假设检验一般即采用卡方检验方法,而置信区间估计依靠各统计软件求得,本文稍后进行讲解。 病例对照研究大部分简单差异性分析和logistic回归分析在分析过程中均可计算OR值,P值及置信区间。 4、病例对照研究基本统计过程病例对照研究总体来说分为以下若干步骤: 1.统计描述 任何研究首先都需对研究对象的特征、病例和对照数量与特征进行描述,此次不再赘述。 2.分组均衡性比较 不同于实验性研究,病例对照研究并非随机化研究,研究对象在患者的特征分布上往往存在着不均衡的现象。因此,一般需要开展差异性比较分析,探讨病例组和对照组在一些非暴露因素的分布上的差异性。 3.暴露因素与结局的简单关联性分析 诚如上文所言,我们需要开展简单关联性分析,采用的手段也是差异性比较分析,同时最好计算OR值和置信区间。 第2步和第3步方法如出一辙,方法和表格完全相同,一般可以将两者合二为一来进行处理。在有些病例对照研究中,所有因素都是为暴露因素,此时,统计分析省略第2步过程;而有些研究中,只是若干个、甚至是1-2个因素视为暴露因素,其它因素则视为干扰因素(主要是混杂因素),即第2步中分组不均衡的因素,比如说年龄和性别,它们更多的时候是控制变量(混杂变量),而非暴露因素。 对于第2步和第3步,本案例具体策略如下: (1)针对年龄这一定量变量的暴露因素,须开展两步工作。第一,判断正态性;第二,采用统计推断方法进行分析,同时计算效应值。特别提醒初学者在SPSS的分析中,年龄为检验变量,有无冠心病变量为分组变量。 正态性情况:直方图显示,偏态情况不严重,仍然可以采用采用参数检验(两组采用t检验)
t检验的界面和结果:结果显示,冠心病患者和对照组在年龄分布上存在着统计学差异。
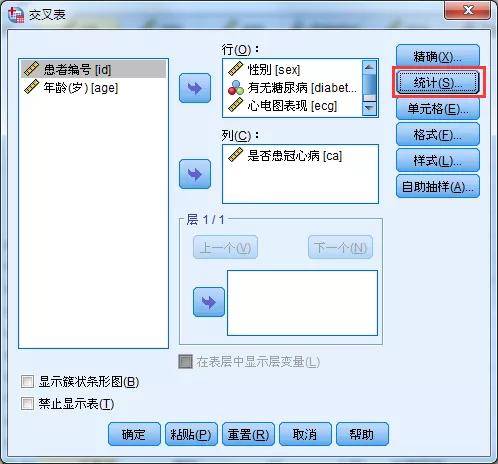
(2)其它变量均采用卡方检验进行分析。病例对照研究SPSS操作在进行卡方检验同时,可以计算OR值 卡方检验入口:分析--描述统计-交叉表
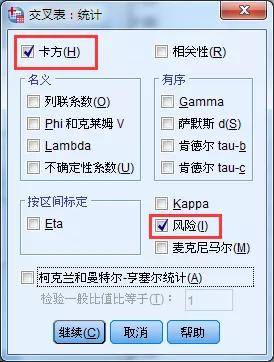
在交叉表界面,选择点击“统计”,可以分别选择卡方和风险(risk)。
以高血压为例,卡方检验,卡方值为20.72,P |



【本文地址】