|
1. 移动平均
from sklearn.metrics import r2_score, mean_absolute_error, median_absolute_error
# 滑动窗口估计,发现数据变化趋势
def plotMovingAverage(series, window, plot_intervals=False, scale=1.96, plot_anomalies=False):
"""
series - dataframe with timeseries
window - rolling window size
plot_intervals - show confidence intervals
plot_anomalies - show anomalies
"""
rolling_mean = series.rolling(window=window).mean()
plt.figure(figsize=(13,5))
plt.title("Moving average\n window size = {}".format(window))
plt.plot(rolling_mean, "g", label="Rolling mean trend")
# Plot confidence intervals for smoothed values
if plot_intervals:
mae = mean_absolute_error(series[window:], rolling_mean[window:])
deviation = np.std(series[window:] - rolling_mean[window:])
lower_bond = rolling_mean - (mae + scale * deviation)
upper_bond = rolling_mean + (mae + scale * deviation)
plt.plot(upper_bond, "r--", label="Upper Bond / Lower Bond")
plt.plot(lower_bond, "r--")
# Having the intervals, find abnormal values
if plot_anomalies:
anomalies = pd.DataFrame(index=series.index)
anomalies['seriesupper_bond'] = series[series>upper_bond]
plt.plot(anomalies, "ro", markersize=10)
plt.plot(series[window:], label="Actual values")
plt.legend(loc="upper left")
plt.grid(True)
plotMovingAverage(data['trend'],12,plot_intervals=True, scale=1.96, plot_anomalies=True)
拟合图像:

2. 单指数平滑
公式: 

单指数平滑值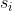 表示为当前统计值 表示为当前统计值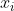 与上一期平滑值 与上一期平滑值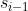 的加权平均, 的加权平均,![\alpha\in [0,1]](https://private.codecogs.com/gif.latex?%5Calpha%5Cin%20%5B0%2C1%5D) 叫做平滑因子,调节远期和近期数据对预测值的影响权重,平滑因子取值越接近0时拟合曲线越平滑,单指数平滑法仅考虑数据的baseline,适用于没有总体趋势的时间序列,如果用来处理有总体趋势的序列,平滑值将滞后于原始数据。 叫做平滑因子,调节远期和近期数据对预测值的影响权重,平滑因子取值越接近0时拟合曲线越平滑,单指数平滑法仅考虑数据的baseline,适用于没有总体趋势的时间序列,如果用来处理有总体趋势的序列,平滑值将滞后于原始数据。
# 单指数平滑
def exponential_smoothing(series, alpha):
"""
series - dataset with timestamps
alpha - float [0.0, 1.0], smoothing parameter
"""
result = [series[0]] # first value is same as series
for n in range(1, len(series)):
result.append(alpha * series[n] + (1 - alpha) * result[n-1])
return result
def plotExponentialSmoothing(series, alphas):
"""
Plots exponential smoothing with different alphas
series - dataset with timestamps
alphas - list of floats, smoothing parameters
"""
with plt.style.context('seaborn-white'):
plt.figure(figsize=(15, 7))
for alpha in alphas:
plt.plot(exponential_smoothing(series, alpha), label="Alpha {}".format(alpha))
plt.plot(series.values, "c", label = "Actual")
plt.legend(loc="best")
plt.axis('tight')
plt.title("Exponential Smoothing")
plt.grid(True);
plotExponentialSmoothing(data['trend'], [0.5, 0.1])
拟合图像:

3. 双指数平滑
公式: 


双指数平滑法在单指数平滑法基础上增加趋势信息,第二个等式描述趋势平滑过程,趋势的未平滑值是当前时刻平滑值减去前一时刻平滑值,再引入参数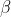 对趋势进行一次指数平滑处理;双指数平滑法同时考虑了时间序列数据的baseline和趋势,适用于具有趋势的时间序列预测; 对趋势进行一次指数平滑处理;双指数平滑法同时考虑了时间序列数据的baseline和趋势,适用于具有趋势的时间序列预测;
# 双指数平滑
def double_exponential_smoothing(series, alpha, beta):
"""
series - dataset with timeseries
alpha - float [0.0, 1.0], smoothing parameter for level
beta - float [0.0, 1.0], smoothing parameter for trend
"""
# first value is same as series
result = [series[0]]
for n in range(1, len(series)+1):
if n == 1:
level, trend = series[0], series[1] - series[0]
if n >= len(series): # forecasting
value = result[-1]
else:
value = series[n]
last_level, level = level, alpha*value + (1-alpha)*(level+trend)
trend = beta*(level-last_level) + (1-beta)*trend
result.append(level+trend)
return result
def plotDoubleExponentialSmoothing(series, alphas, betas):
"""
Plots double exponential smoothing with different alphas and betas
series - dataset with timestamps
alphas - list of floats, smoothing parameters for level
betas - list of floats, smoothing parameters for trend
"""
with plt.style.context('seaborn-white'):
plt.figure(figsize=(13, 5))
for alpha in alphas:
for beta in betas:
plt.plot(double_exponential_smoothing(series, alpha, beta), label="Alpha {}, beta {}".format(alpha, beta))
plt.plot(series.values, label = "Actual")
plt.legend(loc="best")
plt.axis('tight')
plt.title("Double Exponential Smoothing")
plt.grid(True)
plotDoubleExponentialSmoothing(data['trend'], alphas=[0.5,0.3], betas=[0.9,0.3])
拟合结果:

4. 三次指数平滑法(Holt-Winters)
公式: 


三次指数平滑法增加了一个季节分量,适用于带有季节特征的时间序列预测。3个参数值都位于 [0, 1] 之间,可以通过交叉验证、网格搜索寻的最优参数值;s, t, p初值选取对于算法整体影响不大,通常的取值为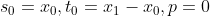 ,累乘时p=1 ,累乘时p=1
class HoltWinters:
"""
Holt-Winters model with the anomalies detection using Brutlag method
# series - initial time series
# slen - length of a season
# alpha, beta, gamma - Holt-Winters model coefficients
# n_preds - predictions horizon
# scaling_factor - sets the width of the confidence interval by Brutlag (usually takes values from 2 to 3)
"""
def __init__(self, series, slen, alpha, beta, gamma, n_preds, scaling_factor=1.96):
self.series = series
self.slen = slen
self.alpha = alpha
self.beta = beta
self.gamma = gamma
self.n_preds = n_preds
self.scaling_factor = scaling_factor
def initial_trend(self):
s = 0.0
for i in range(self.slen):
s += float(self.series[i + self.slen] - self.series[i]) / self.slen
return s / self.slen
def initial_seasonal_components(self):
seasons = {}
season_averages = []
n_seasons = int(len(self.series) / self.slen)
# calculate season averages
for j in range(n_seasons):
season_averages.append(self.series[self.slen * j:self.slen * j + self.slen].sum() / float(self.slen))
# calculate initial values
for i in range(self.slen):
sum_of_vals_over_avg = 0.0
for j in range(n_seasons):
sum_of_vals_over_avg += self.series[self.slen * j + i] - season_averages[j]
seasons[i] = sum_of_vals_over_avg / n_seasons
return seasons
def triple_exponential_smoothing(self):
self.result = []
self.Smooth = []
self.Season = []
self.Trend = []
self.PredictedDeviation = []
self.UpperBond = []
self.LowerBond = []
seasons = self.initial_seasonal_components()
for i in range(len(self.series) + self.n_preds):
if i == 0: # components initialization
smooth = self.series[0]
trend = self.initial_trend()
self.result.append(self.series[0])
self.Smooth.append(smooth)
self.Trend.append(trend)
self.Season.append(seasons[i % self.slen])
self.PredictedDeviation.append(0)
self.UpperBond.append(self.result[0] +
self.scaling_factor *
self.PredictedDeviation[0])
self.LowerBond.append(self.result[0] -
self.scaling_factor *
self.PredictedDeviation[0])
continue
if i >= len(self.series): # predicting
m = i - len(self.series) + 1
self.result.append((smooth + m * trend) + seasons[i % self.slen])
# when predicting we increase uncertainty on each step
self.PredictedDeviation.append(self.PredictedDeviation[-1] * 1.1314)
else:
val = self.series[i]
last_smooth, smooth = smooth, self.alpha * (val - seasons[i % self.slen]) + (1 - self.alpha) * (
smooth + trend)
trend = self.beta * (smooth - last_smooth) + (1 - self.beta) * trend
seasons[i % self.slen] = self.gamma * (val - smooth) + (1 - self.gamma) * seasons[i % self.slen]
self.result.append(smooth + trend + seasons[i % self.slen])
# Deviation is calculated according to Brutlag algorithm.
self.PredictedDeviation.append(self.gamma * np.abs(self.series[i] - self.result[i])
+ (1 - self.gamma) * self.PredictedDeviation[-1])
self.UpperBond.append(self.result[-1] +
self.scaling_factor *
self.PredictedDeviation[-1])
self.LowerBond.append(self.result[-1] -
self.scaling_factor *
self.PredictedDeviation[-1])
self.Smooth.append(smooth)
self.Trend.append(trend)
self.Season.append(seasons[i % self.slen])
# 图形结果展示
def plot_holt_winters(series, model, plot_intervals=False, plot_anomalies=False, save_pic=False):
"""
series - dataset with timeseries
plot_intervals - show confidence intervals
plot_anomalies - show anomalies
"""
plt.figure(figsize=(13, 4))
xt = series.index
plt.plot(xt, model.result, 'g', label="Model")
plt.plot(xt, series.values, 'b', label="Actual")
error = mean_absolute_percentage_error(series.values[-model.n_preds:], model.result[-model.n_preds:])
pic_title = ' ( ' + series.name + ' ) ' + 'Mean Absolute Percentage Error: {0:.2f}%'.format(error)
plt.title(pic_title)
if plot_anomalies:
anomalies = np.array([np.NaN] * len(series))
anomalies[series.values < model.LowerBond[:len(series)]] = \
series.values[series.values < model.LowerBond[:len(series)]]
anomalies[series.values > model.UpperBond[:len(series)]] = \
series.values[series.values > model.UpperBond[:len(series)]]
plt.plot(xt, anomalies, "r*", markersize=10, label="Anomalies")
if plot_intervals:
plt.plot(xt, model.UpperBond, "r--", alpha=0.5, label="Up/Low confidence")
plt.plot(xt, model.LowerBond, "r--", alpha=0.5)
plt.fill_between(x=xt[0:len(model.result)], y1=model.UpperBond,
y2=model.LowerBond, alpha=0.2, color="grey")
plt.vlines(xt[len(series)-model.n_preds], ymin=min(model.LowerBond), ymax=max(model.UpperBond),
linestyles='dashed')
plt.axvspan(xt[len(series)-model.n_preds], xt[len(model.result)-1], alpha=0.3, color='lightgrey')
plt.grid(True)
plt.axis('tight')
plt.legend(loc="best", fontsize=13)
if save_pic:
pic_name = './out/TestResult/202007/{}.png'.format(series.name)
plt.savefig(pic_name)
# 交叉验证求参数
def cv_score(params, series, loss_function=mean_squared_error, slen=12):
"""
Returns error on CV
params - vector of parameters for optimization
series - dataset with timeseries
slen - season length for Holt-Winters model
"""
# errors array
errors = []
values = series.values
alpha, beta, gamma = params
# set the number of folds for cross-validation
tscv = TimeSeriesSplit(n_splits=4)
# iterating over folds, train model on each, forecast and calculate error
for train, test in tscv.split(values):
if len(train) < 24:
print(' : The train set is not large enough!')
else:
model = HoltWinters(series=values[train], slen=slen,
alpha=alpha, beta=beta, gamma=gamma, n_preds=len(test))
model.triple_exponential_smoothing()
predictions = model.result[-len(test):]
actual = values[test]
error = loss_function(predictions, actual)
errors.append(error)
return np.mean(np.array(errors))
# 网格搜索参数初值
def get_best_params(Series):
warnings.filterwarnings("ignore")
best_score = 100
best_param_ini = 0
best_param_fin = 0
for i in list(np.arange(0, 1.1, 0.1)):
try:
x = [i, i, i]
opt = minimize(cv_score, x0=x, args=(Series, mean_squared_log_error),
method="TNC", bounds = ((0, 1), (0, 1), (0, 1)))
alpha_final, beta_final, gamma_final = opt.x
except ValueError:
continue
else:
hw = HoltWinters(Series, slen = 12, alpha = alpha_final, beta = beta_final, gamma = gamma_final,
n_preds = 12, scaling_factor = 3)
hw.triple_exponential_smoothing()
error = mean_absolute_percentage_error(Series.values[-12:], hw.result[-24:-12])
# print(x,': ',mape)
if error < best_score:
best_score = error
best_param_ini = i
best_param_fin = alpha_final, beta_final, gamma_final
# print("best_score:{:.2f}".format(best_score))
# print("best_para_initial:{}".format(best_param_ini))
# print("best_para_final:{}".format(best_param_fin))
return best_param_fin
alpha_final, beta_final, gamma_final = get_best_params(train_scalar)
model = HoltWinters(train_scalar, slen = 12,
alpha = alpha_final,
beta = beta_final,
gamma = gamma_final,
n_preds = 3,
scaling_factor = 20)
model.triple_exponential_smoothing()

|