| 聚类总结(二)聚类性能评估、肘部法则、轮廓系数 | 您所在的位置:网站首页 › 拐点怎么算 › 聚类总结(二)聚类性能评估、肘部法则、轮廓系数 |
聚类总结(二)聚类性能评估、肘部法则、轮廓系数
|
文章目录
一、聚类K的选择规则1.1 肘部法则–Elbow Method1.2 轮廓系数–Silhouette Coefficient
二、聚类性能评估2.1 外部评估(external evaluation)2.1.1 Adjusted Rand Index(兰德指数)2.1.2 Entropy 熵2.1.3 purity(纯度)2.1.4 Accuracy(AC)
2.2 内部评估(internal evaluation)2.2.1 Silhouette coefficient(轮廓系数)2.2.2 Calinski-Harabaz(CH)
2.3 其它内部评估方法(others)2.3.1 Davies-Bouldin Index(DBI)2.3.2 Dunn Index(DI)
有趣的事,Python永远不会缺席培训说明
聚类(一)https://blog.csdn.net/u010986753/article/details/97821890
聚类(二)https://blog.csdn.net/u010986753/article/details/97885955
一、聚类K的选择规则
1.1 肘部法则–Elbow Method
我们知道k-means是以最小化样本与质点平方误差作为目标函数,将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度(distortions),那么,对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度越高,代表簇内结构越松散。 畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。 from sklearn.cluster import KMeans model = KMeans(n_clusters=k) model.fit(vector_points) md = model.inertia_ / vector_points.shape[0]
基于这个指标,我们可以重复训练多个k-means模型,选取不同的k值,来得到相对合适的聚类类别(簇内误方差(SSE)) 如上图所示,在k=3时,畸变程度得到大幅改善,可以考虑选取k=3作为聚类数量,附简单代码: 1.2 轮廓系数–Silhouette Coefficient对于一个聚类任务,我们希望得到的类别簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集与分散程度的评价指标,公式表达如下 s=(b−a)/max(a,b) a簇样本到彼此间距离的均值b代表样本到除自身所在簇外的最近簇的样本的均值s取值在[-1, 1]之间。如果s接近1,代表样本所在簇合理,若s接近-1代表s更应该分到其他簇中。 同样,利用上述指标,训练多个模型,对比选取合适的聚类类别:
图, 当k=3时,轮廓系数最大,代表此时聚类的效果相对合理,简单代码如下: from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score model = KMeans(n_clusters=k) model.fit(vector_points) s = silhouette_score(vector_points, model.labels_) 二、聚类性能评估说到聚类性能比较好,就是说同一簇的样本尽可能的相似,不同簇的样本尽可能不同,即是说聚类结果簇内相似度(intra-cluster similarity)高,而簇间相似度(inter-cluster similarity)低。 有监督的分类算法的评价指标通常是accuracy, precision, recall, etc;由于聚类算法是无监督的学习算法,评价指标则没有那么简单了。因为聚类算法得到的类别实际上不能说明任何问题,除非这些类别的分布和样本的真实类别分布相似,或者聚类的结果满足某种假设,即同一类别中样本间的相似性高于不同类别间样本的相似性。聚类模型的评价指标如下: 2.1 外部评估(external evaluation)将结果与某个“参考模型”(reference model)进行比较。 2.1.1 Adjusted Rand Index(兰德指数)ARI的优点: 随机均匀的标签分布的ARI值接近0,这点与raw Rand Index和 V-measure指标不同;ARI值的范围是[-1,1],负的结果都是较差的,说明标签是独立分布的,相似分布;ARI结果是正的,1是最佳结果,说明两种标签的分布完全一致;不用对聚类结果做任何假设,可以用来比较任意聚类算法的聚类结果间的相似性。 ARI的缺点: ARI指标需要事先知道样本的真实标签,这和有监督学习的先决条件是一样的。然而ARI也可以作为一个通用的指标,用来评估不同的聚类模型的性能。数学公式: 如果C是真实类别,K是聚类结果,我们定义a和b分别是: a: 在C和K中都是同一类别的样本对数 b: 在C和K中都是不同类别的样本对数 C 2 n C^n_2 C2nsamples 是样本所有的可能组合对. raw Rand Index 的公式如下 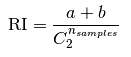
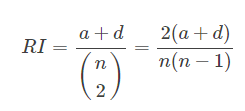 2.1.2 Entropy 熵
2.1.2 Entropy 熵
对于一个聚类i,首先计算。指的是聚类 i 中的成员(member)属于类(class)j 的概率,。其中是在聚类 i 中所有成员的个数,是聚类 i 中的成员属于类 j 的个数。每个聚类的entropy可以表示为,其中L是类(class)的个数。整个聚类划分的entropy为,其中K是聚类(cluster)的数目,m是整个聚类划分所涉及到的成员个数。  2.1.3 purity(纯度)
2.1.3 purity(纯度)
使用上述Entropy中的定义,我们将聚类 i 的purity定义为。整个聚类划分的purity为,其中K是聚类(cluster)的数目,m是整个聚类划分所涉及到的成员个数。  def purity(cluster, labels, k, label_set):
p = np.zeros((k, len(label_set)))
purity = 0
for i in range(len(cluster)):
p[int(cluster[i]), label_set.index(labels[i])] += 1
purity = sum(np.max(p, axis=1))/len(labels)
return purity
2.1.4 Accuracy(AC)
def purity(cluster, labels, k, label_set):
p = np.zeros((k, len(label_set)))
purity = 0
for i in range(len(cluster)):
p[int(cluster[i]), label_set.index(labels[i])] += 1
purity = sum(np.max(p, axis=1))/len(labels)
return purity
2.1.4 Accuracy(AC)
Accuracy, (Accuracy 里可以包含了precision, recall, f-measure.),AC是目前最流行的聚类评价指标。在很多文献里面,都将AC作为聚类结果的评价指标。 
map(pi) 是一个排列映射函数,将聚类得到的标签映射到与之等价的真实标签,聚类标签与真实标签之间是1-1映射(不一定是满的)。  CA计算 聚类正确的百分比CA越大证明聚类效果越好
def f_score(cluster, labels, label_set):
TP, TN, FP, FN = 0, 0, 0, 0
n = len(labels)
# a lookup table
for i in range(n):
if i not in cluster:
continue
for j in range(i + 1, n):
if j not in cluster:
continue
same_label = (labels[i] == labels[j])
same_cluster = (cluster[i] == cluster[j])
if same_cluster:
if same_label:
TP += 1
else:
FP += 1
elif same_label:
FN += 1
else:
TN += 1
precision = TP / (TP + FP)
recall = TP / (TP + FN)
fscore = 2 * precision * recall / (precision + recall)
return fscore, precision, recall, TP + FP + FN + TN
CA计算 聚类正确的百分比CA越大证明聚类效果越好
def f_score(cluster, labels, label_set):
TP, TN, FP, FN = 0, 0, 0, 0
n = len(labels)
# a lookup table
for i in range(n):
if i not in cluster:
continue
for j in range(i + 1, n):
if j not in cluster:
continue
same_label = (labels[i] == labels[j])
same_cluster = (cluster[i] == cluster[j])
if same_cluster:
if same_label:
TP += 1
else:
FP += 1
elif same_label:
FN += 1
else:
TN += 1
precision = TP / (TP + FP)
recall = TP / (TP + FN)
fscore = 2 * precision * recall / (precision + recall)
return fscore, precision, recall, TP + FP + FN + TN
在二分类中: TP(true positive):分类正确,把原本属于正类的样本分成正类。TN(true negative):分类正确,把原本属于负类的样本分成负类。FP(false positive):分类错误,把原本属于负类的错分成了正类。FN(false negative):分类错误,把原本属于正类的错分成了负类。 2.2 内部评估(internal evaluation)直接考虑聚类结果而不利用任何参考模型。 2.2.1 Silhouette coefficient(轮廓系数)轮廓系数–Silhouette Coefficient 1.2 已讲。 2.2.2 Calinski-Harabaz(CH)CH也适用于实际类别信息未知的情况,以下以K-means为例,给定聚类数目K  2.3 其它内部评估方法(others)
2.3.1 Davies-Bouldin Index(DBI)
σi:本簇中到其它所有样本点的距离的平均;cici :簇的中心;d(ci,cj):样本间距。
2.3 其它内部评估方法(others)
2.3.1 Davies-Bouldin Index(DBI)
σi:本簇中到其它所有样本点的距离的平均;cici :簇的中心;d(ci,cj):样本间距。
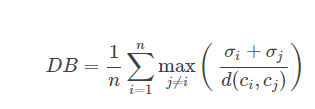
DBI越小越好。 2.3.2 Dunn Index(DI) d(i,j) :样本间距;d′(k) :本簇内样本对间的最远距离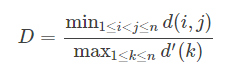
DI越大越好。 加油 有趣的事,Python永远不会缺席欢迎关注小婷儿的博客 文章内容来源于小婷儿的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解 如需转发,请注明出处:小婷儿的博客python https://www.cnblogs.com/xxtalhr/ 博客园 https://www.cnblogs.com/xxtalhr/ CSDN https://blog.csdn.net/u010986753 有问题请在博客下留言或加作者: 微信:tinghai87605025 联系我加微信群 QQ :87605025 python QQ交流群:py_data 483766429  培训说明
培训说明
OCP培训说明连接 https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA OCM培训说明连接 https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA 小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。重要的事多说几遍。。。。。。 |


【本文地址】