| socket实现简单的Web服务器 | 您所在的位置:网站首页 › 所请求的传送移动无法安全进行 › socket实现简单的Web服务器 |
socket实现简单的Web服务器
|
套接字编程:Web服务器
基本说明
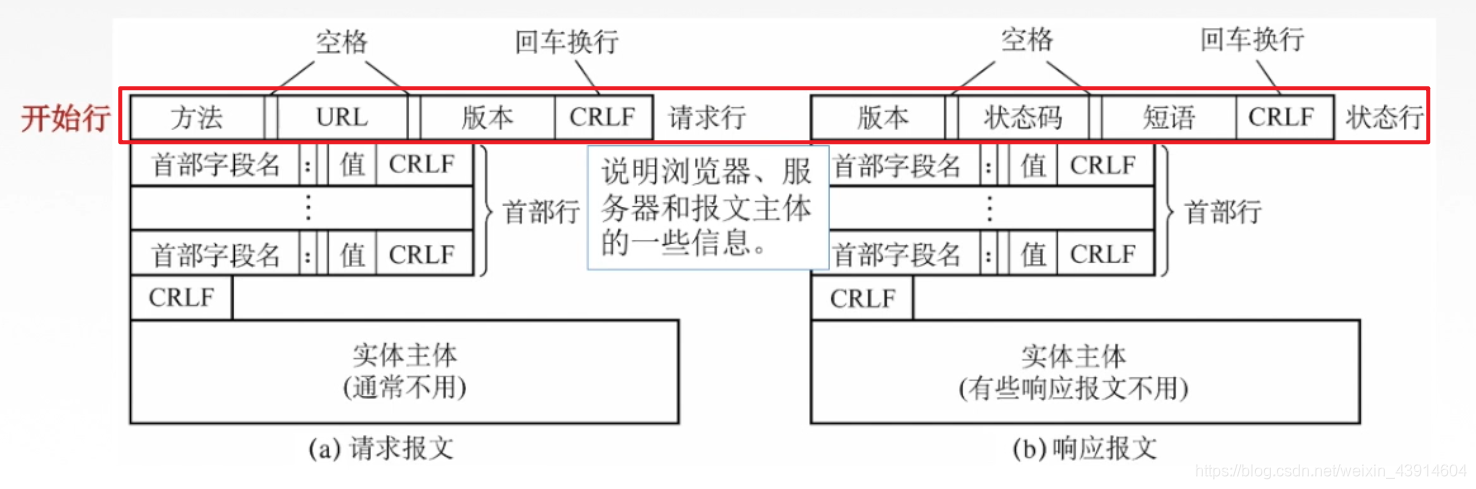
《计算机网络:自顶向下方法》中第二章末尾(P119)给出了此编程作业的简单描述: 在这个编程作业中,你将用Python语言开发一个简单的Web服务器,它仅能处理一个请求。具体而言,你的Web服务器将: 当一个客户(浏览器)联系时创建一个连接套接字;从这个连接套接字接收HTTP请求;解释该请求以确定所请求的特定文件;从服务器的文件系统获得请求的文件;创建一个由请求的文件组成的HTTP响应报文,报文前面有首部行;经TCP连接向请求浏览器发送响应。如果浏览器请求一个在该服务器种不存在的文件,服务器应当返回一个“404 Not Found”差错报文。在配套网站中,我们提供了用于该服务器的框架代码,我们提供了用于该服务器的框架代码。你的任务是完善该代码,运行服务器,通过在不同主机上运行的浏览器发送请求来测试该服务器。如果运行你服务器的主机上已经有一个Web服务器在运行,你应当为该服务器使用一个不同于80端口的其他端口。 流程分析和代码实现 1、基础知识本实验根据之前的TCP和UDP套接字编程的实现,进行相应的拓展即可实现;也就是加入相应的HTTP请求和相应报文分析,需要了解HTTP的报文格式(请求报文和响应报文)。 由于HTTP使用TCP作为它的支撑运输协议,因此只需要将报文进行解析即可。如果对TCP套接字编程不是很熟悉,可以参照之前的博客。 UDP和TCP套接字(socket)编程实现及原理阐述 (1)HTTP的报文格式如下:
万维网(World Wide Web, WWW)是一个资料空间,在这个空间中: 一样有用的事物称为一样“资源”,并由一个全域“统一资源定位符”(URL)标识。 这些资源通过超文本传输协议(HTTP)传送给使用者,通过单击链接来获取资源。
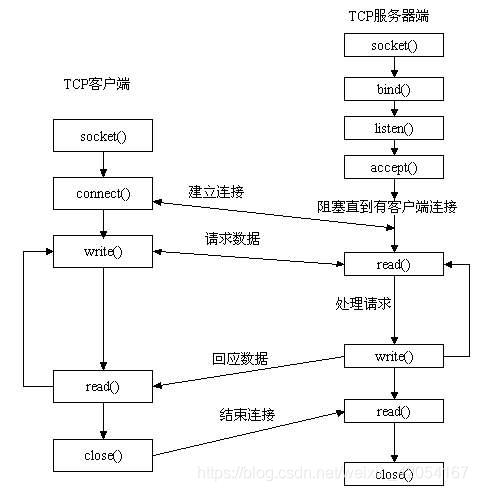
URL是对可以从因特网上得到的资源的位置和访问方法的一种简洁表示。URL相当于一个文件名在网络范围的扩展。 URL的一般形式是: ://:/。 常见的有http、ftp 等; < (主机>是存放资源的主机在因特网中的域名,也可以是IP地址; 和有时可以省略。 在URL中不区分大小写。 (3)发送 read() 和 接收 recv()不论是客户还是服务器应用程序: 用send函数来向TCP连接的另一端发送数据,用recv函数从TCP连接的另一端接收数据。 int send(SOCKET s, const char FAR *buf, int len, int flags); int recv(SOCKET s, char FAR *buf, int len, int flags);客户程序一般用send函数向服务器发送请求,而服务器则通常用send函数来向客户程序发送应答。该函数的第一个参数指定发送端套接字描述符;第二个参数指明一个存放应用程序要发送数据的缓冲区;第三个参数指明实际要发送的数据的字节数;第四个参数一般置0。 由于只是实现简单的Web服务器,以下参数的设置可以暂时不考虑。 原理阐述: (1)数据长度比较 当调用send()函数时,先比较待发送数据的长度len和套接字s的发送缓冲的长度,如果len大于s的发送缓冲区的长度,该函数返回SOCKET_ERROR;如果len小于或者等于s的发送缓冲区的长度,那么send先检查协议是否正在发送s的发送缓冲中的数据; (2)如果长度小于或者等于缓冲区的长度,检测是否正在发送 如果是就等待协议把数据发送完,如果协议还没有开始发送s的发送缓冲中的数据或者s的发送缓冲中没有数据,那么 send就比较s的发送缓冲区的剩余空间和len; (2)如果没有开始发送或者缓冲区没有数据,检测长度判断是否copy 如果len大于剩余空间大小send就一直等待协议把s的发送缓冲中的数据发送完,如果len小于剩余空间大小send就仅仅把buf中的数据copy到剩余空间里(注意并不是send把s的发送缓冲中的数据传到连接的另一端的,而是协议传的,send仅仅是把buf中的数据copy到s的发送缓冲区的剩余空间里)。如果send函数copy数据成功,就返回实际copy的字节数,如果send在copy数据时出现错误,那么send就返回SOCKET_ERROR;如果send在等待协议传送数据时网络断开的话,那么send函数也返回SOCKET_ERROR。 要注意send函数把buf中的数据成功copy到s的发送缓冲的剩余空间里后它就返回了,但是此时这些数据并不一定马上被传到连接的另一端。如果协议在后续的传送过程中出现网络错误的话,那么下一个Socket函数就会返回SOCKET_ERROR。(每一个除send外的Socket函数在执行的最开始总要先等待套接字的发送缓冲中的数据被协议传送完毕才能继续,如果在等待时出现网络错误,那么该Socket函数就返回 SOCKET_ERROR)。 2、流程分析
(1)代码注解版本: # ----------------Web服务器实现------------------- # Import socket module from socket import * # sys.argv: 实现从程序外部向程序传递参数。sys.exit([arg]): 程序中间的退出,arg=0为正常退出。 import sys #为了终止程序 # 创建一个TCP套接字(使用IPV4, 类型为TCP套接字) serverSocket = socket(AF_INET, SOCK_STREAM) # 分配/指派一个端口号 serverPort = 6789 # 将套接字绑定到服务器地址和服务器端口 serverSocket.bind(("", serverPort)) # 监听端口,并指定最大连接数为1 serverSocket.listen(1) # 服务器持续启动运行,并侦听传入的连接 while True: print('The server is ready to receive') # 一直进行监听,如果客户端进行连接,相应并建立来自客户端的新连接 connectionSocket, addr = serverSocket.accept() try: # 接受客户端的请求信息,而1024表示,最多每次接受1024字节,size的设置是一个值得研究的问题。socket中,调用send()和recv()时都会判断一下返回值,如果返回值是-1(或者SOCKET_ERROR),那么就进行错误处理(一般是打印出错信息,关闭socket,退出) message = connectionSocket.recv(1024).decode() # 从消息(请求报文)中提取所请求对象的路径(URL),由HTTP的请求报文可知,URL是HTTP标头的第二部分,由[1]标识 filename = message.split()[1] # 因为HTTP请求的提取路径包括一个字符“ \”,我们从第二个字符读取路径。因为URL的一般形式是: ://:/。 # python open()函数用于打开一个文件,创建一个file对象。open(name[, mode[, buffering]]),mod为读取模式默认只读。 f = open(filename[1:]) # 将请求文件的全部内容存储在临时缓冲区中 # read(),readlines()读取整个文件,分别返回字符串类型和list类型。readline(),读取一行 outputdata = f.read() # 将HTTP响应标头行(版本,状态码,短语,CRLF(回车换行))发送到连接套接字 connectionSocket.send("HTTP/1.1 200 OK\r\n\r\n".encode()) # 将请求文件的内容发送到连接套接字 for i in range(0, len(outputdata)): connectionSocket.send(outputdata[i].encode()) connectionSocket.send("\r\n".encode()) # connectionSocket.send(outputdata.encode()) #两种发送方法都可,显然上一种速度更慢 connectionSocket.close() except IOError: # 发送未找到文件的HTTP响应消息 connectionSocket.send("HTTP/1.1 404 Not Found\r\n\r\n".encode()) connectionSocket.send("404 Not Found\r\n".encode()) # Close the client connection socket connectionSocket.close() serverSocket.close() sys.exit()#发送相应数据后终止程序(1)简洁版本: # Import socket module from socket import * import sys serverSocket = socket(AF_INET, SOCK_STREAM) serverPort = 6789 serverSocket.bind(("", serverPort)) serverSocket.listen(1) # 服务器持续启动运行,并侦听传入的连接 while True: print('The server is ready to receive') # 一直进行监听,如果客户端进行连接,相应并建立来自客户端的新连接 connectionSocket, addr = serverSocket.accept() try: # 接受客户端的请求信息 message = connectionSocket.recv(1024).decode() # 从消息(请求报文)中提取所请求对象的路径(URL) filename = message.split()[1] # 由URL的一般形式,需要从第二个字符读取路径。 f = open(filename[1:]) # 将请求文件的全部内容存储在临时缓冲区中 outputdata = f.read() # 将HTTP响应标头行发送到连接套接字 connectionSocket.send("HTTP/1.1 200 OK\r\n\r\n".encode()) # 将请求文件的内容发送到连接套接字 for i in range(0, len(outputdata)): connectionSocket.send(outputdata[i].encode()) connectionSocket.send("\r\n".encode()) connectionSocket.close() except IOError: # 发送未找到文件的HTTP响应消息 connectionSocket.send("HTTP/1.1 404 Not Found\r\n\r\n".encode()) connectionSocket.send("404 Not Found\r\n".encode()) connectionSocket.close() serverSocket.close() sys.exit()#发送相应数据后终止程序HelloWorld.html 在text文件中输入如下语句,并命名为HelloWorld.html,注意后缀。 Hello world! 实验结果服务器端: 在一台主机上的同一目录下放入WebServer.py和HelloWorld.html两个文件,并运行WebServer.py,作为服务器。 客户端: 在另一台主机上打开浏览器,并输入"http://XXX.XXX.XXX.XXX:6789/HelloWorld.html" (其中"XXX.XXX.XXX.XXX"是服务器IP地址),以获取服务器上的HelloWorld.html文件。 一切正常的话,可以看到如下页面: 输入新地址"http://XXX.XXX.XXX.XXX:6789/abc.html",以获取服务器上不存在的abc.html。 将出现以下页面(注意页面中的"HTTP ERROR 404"): |




【本文地址】