| 数据结构基础 | 您所在的位置:网站首页 › 情怀的概念和定义 › 数据结构基础 |
数据结构基础
|
数据结构基础——堆的概念、结构及应用
目录
堆的概念堆这种数据结构的代码实现堆在排序算法上的应用
1.堆的概念
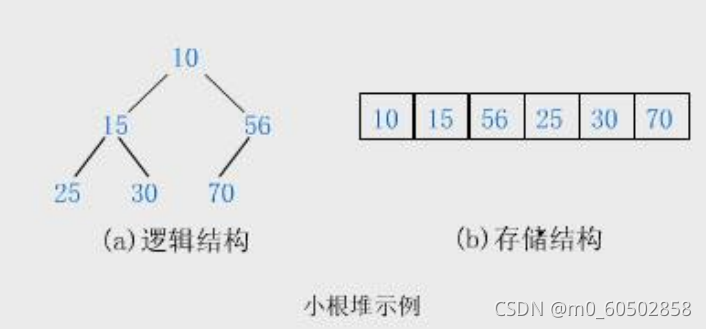
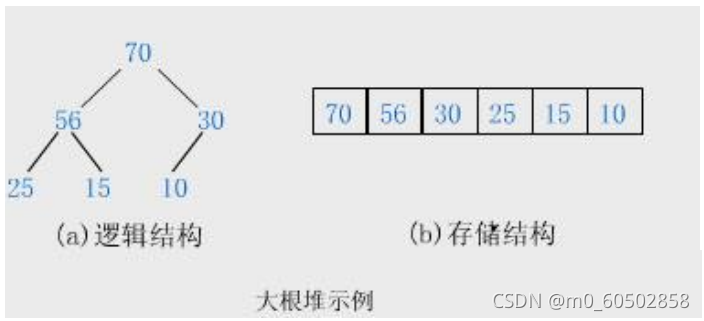
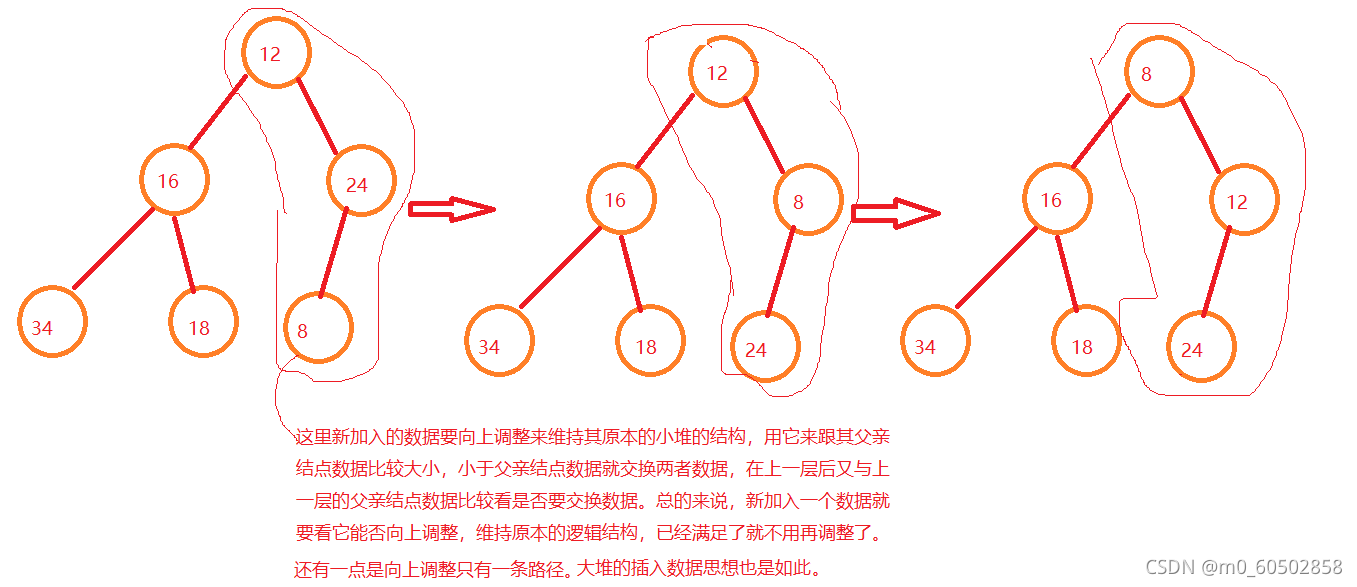
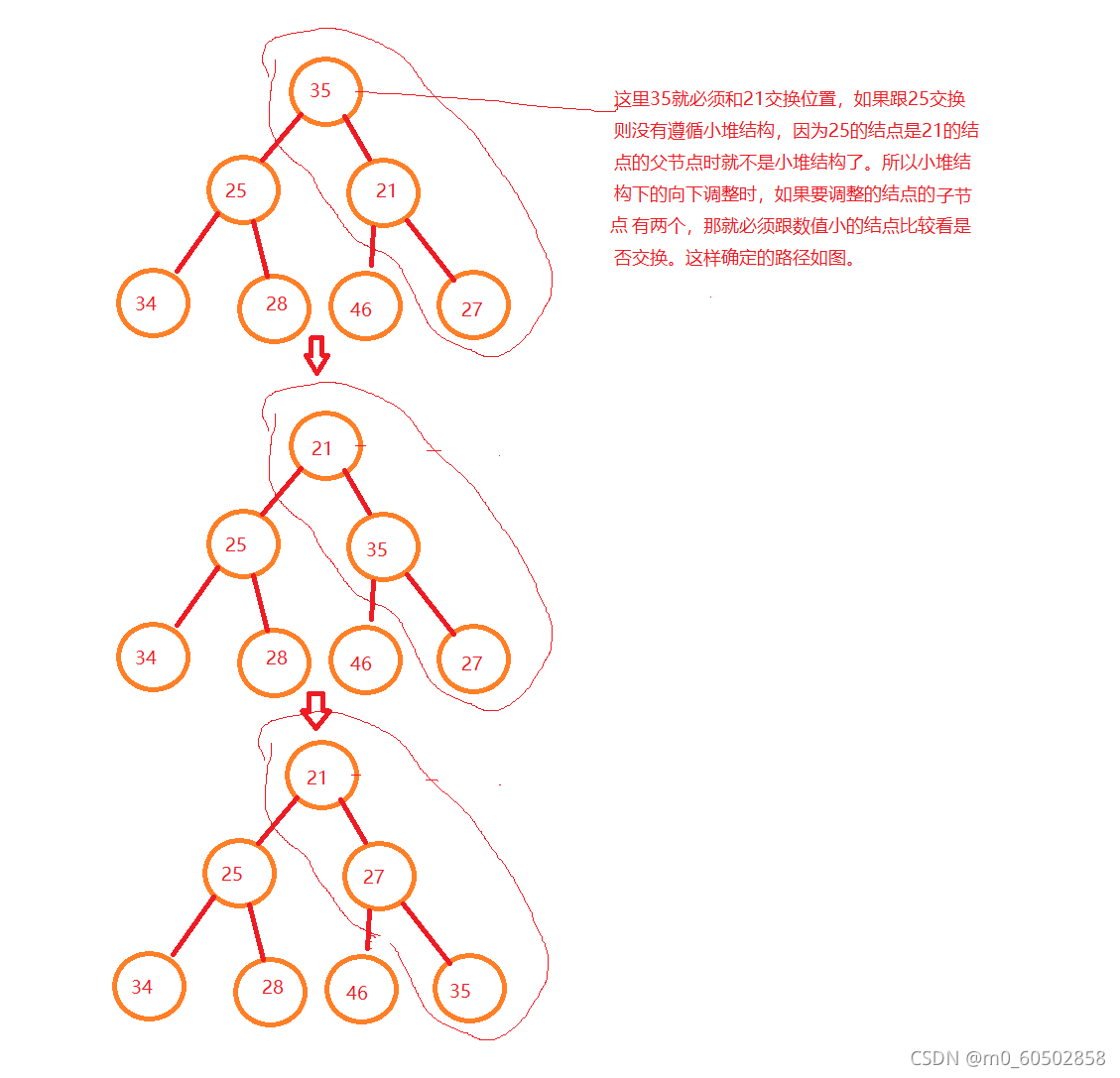
堆就是以二叉树的顺序存储方式来存储元素,同时又要满足父亲结点存储数据都要大于儿子结点存储数据(也可以是父亲结点数据都要小于儿子结点数据)的一种数据结构。堆只有两种即大堆和小堆,大堆就是父亲结点数据大于儿子结点数据,小堆则反之。 堆的性质: 堆中某个节点的值总是不大于或不小于其父节点的值; 堆总是一棵完全二叉树。 用图画展示就如下图所示: 了解了堆的概念之后,我们要实际写出一个堆来,先写个小堆为例。 物理结构是用一个数组来存储数据,先定义一个动态增长的数组来。 typedef int Datatype; typedef struct { Datatype* a; int size; int capacity; }heap; //这就是堆的基本形式了,然后再按照完全二叉数的逻辑形式插入数据在测试的源文件中创建一个堆 heap hp; //之后就可以写各种堆的功能函数来操作堆了,都是通过传堆的地址过去来操作的 //在头文件中就先声明跟堆有关的各种接口函数 void heapinit(heap* hp); //堆的初始化 void heapdestroy(heap* hp); //堆的销毁 void heappush(heap* hp, Datatype x); //数据进堆 void heappop(heap* hp); //数据出堆 void heapadjustdown(int* a, int n, int x);//向下调整 void heapadjustup(int* a, int n, int x); //向上调整 void swap(int* a, int* b); //交换两个数值 void print(heap* hp); //打印堆的数据 bool heapEmpty(heap* hp); //判断堆是否时空堆 int heapSize(heap* hp); //计算堆的数据元素个数 Datatype heaptop(heap* hp); //获得堆顶的数据然后在另一个源文件中定义这些函数,并加以详细说明。 void heapinit(heap* hp) { assert(hp); hp->a = NULL; //堆的初始化,此时堆中没有数据 hp->capacity = hp->size = 0; }//往堆中加入数据,物理结构上是不断地在数组尾部加入数据,但加入数据后就要调整数据维持一个小堆或大堆的逻辑结构,要有一个向上调整的函数。如下图所示 向下调整就跟向上调整有区别了,从根结点开始向下可能有不同的路径,我们要维持住小堆则最小的数在堆顶,大堆则最大的数在堆顶。具体看下图所示 后面其它函数的实现 void swap(int* a, int* b) //交换两个位置的数据 { int tem = *a; *a = *b; *b = tem; } void print(heap* hp) //在屏幕上打印堆的数据 { assert(hp); assert(hp->a); for (int i = 0; i size; i++) printf("%d ", hp->a[i]); printf("\n"); } bool heapEmpty(heap* hp) //判断堆是否为空,空就返回真,否则返回假 { assert(hp); return hp->size == 0; } int heapSize(heap* hp) //返回堆的数据个数 { assert(hp); return hp->size; } Datatype heaptop(heap* hp) /获得堆顶的数据 { assert(hp); assert(!heapEmpty(hp)); return hp->a[0]; } void heapdestroy(heap* hp) //最红销毁堆 { assert(hp); assert(hp->a); free(hp->a); hp->capacity = hp->size = 0; } 3.堆在排序算法上的应用用堆这种数据结构来找一组数据中最大的或者最小的几个数据是一种比较高效的算法,小堆就是比较大的数据都在堆的下面,如果要找出N个数中最大的K个数,我们可以先用N个数中的K个数建一个小堆,最小的数在堆顶,拿其余N-K个数依次与堆顶数据比较,大于堆顶数据,就拿它更新堆顶数据,在向下调整,比较完这N-K个数后,堆中的K个数就是这N个数中最大的K个数。同理在大堆中最大的数在堆顶,较小的数在堆下面,以同样的规律,比较数据,如果小于堆顶数据就更新堆顶数据,最后留在堆中的K个数就是N个数中最小的数据。 这里来找一下N个数中最大的K个数。 void printTok(int* a, int n, int k);//找最大的K个数的函数声明 void testTok() //找出N个数中最大的K个数的函数测试 数据的准备 { int N = 10000, k = 10; int* a = (int*)malloc(sizeof(int) * N); if (a == NULL) { printf("malloc fail\n"); exit(-1); } srand((size_t)time(0)); for (int i = 0; i int i; heap hp; heapinit(&hp); for (i = 0; i if (a[i] > heaptop(&hp)) { hp.a[0] = a[i]; heapadjustdown(hp.a, hp.size, 0); } } print(&hp); heapdestroy(&hp); }最后代码没问题的话,效果如下图 |

【本文地址】
公司简介
联系我们