| 远程服务器AutoDL登录/配环境/部署运行大模型方法 | 您所在的位置:网站首页 › 怎么访问远程服务器 › 远程服务器AutoDL登录/配环境/部署运行大模型方法 |
远程服务器AutoDL登录/配环境/部署运行大模型方法
|
1. AutoDL
autodl平台,是一个功能强大的本地大语言模型LLM运行专家,为用户提供了简单高效的方式来运行大型语言模型.通过优化设置和配置细节。 地址:AutoDL官方地址 AutoDL快速了解及上手教程:AutoDL使用教程 2. 登录远程服务器方式登录远程服务器上传数据的方式的方式和工具有很多种, 详情参考AutoDL官网上传数据 2.1 方法一用AutoDL自带的工具,如下图,进入JupyterLab,里面有终端工具,可以连接AuDL上的远程服务器。 2.2.1 复制SSH指令和密码 进入autoDL的控制台,进入自己租用的实例后,将SSH登录的登录指令和密码复制下来备用,SSH指令形如ssh -p 19267 [email protected] ,其中: root : 用户名connect.bjb1.seetacloud.com : 主机名19267 : 端口号 2.2.2 用Xshell和Xftp登录并传输文件 Xshell和Xftp使用教程:B站上一个关于Xshell和Xftp较为完整全面的使用教程 在Xshell->文件->新建中,新建一个会话,将主机号和端口号填写进去,点击确定 2.2.2 用Xshell和Xftp登录并传输文件 Xshell和Xftp使用教程:B站上一个关于Xshell和Xftp较为完整全面的使用教程 在Xshell->文件->新建中,新建一个会话,将主机号和端口号填写进去,点击确定 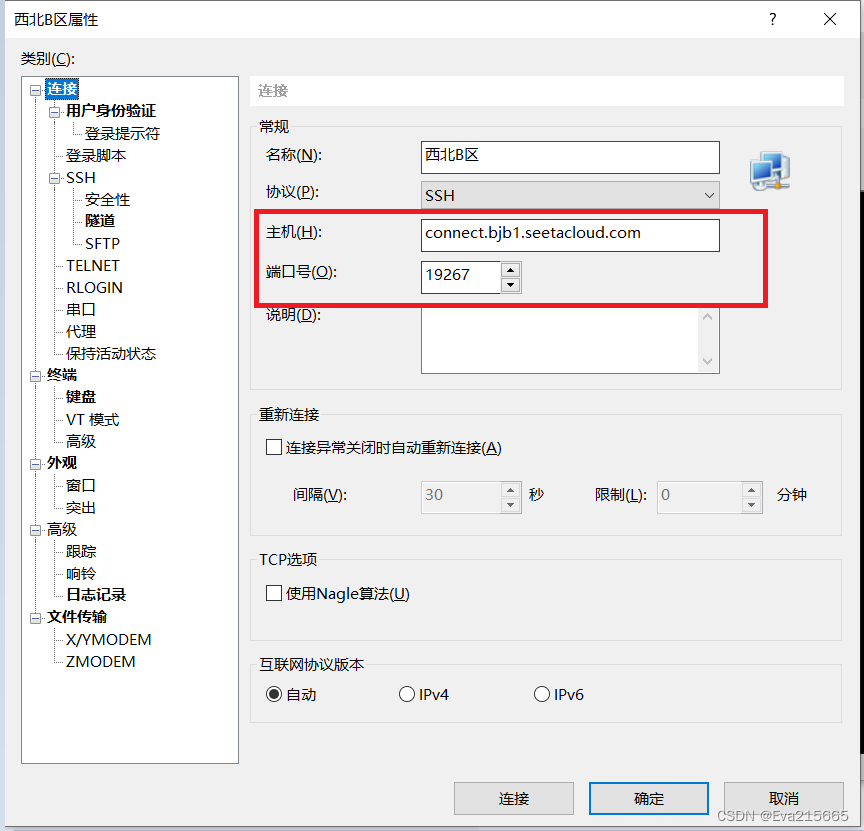 输入密码后确定,出现下图则连接成功。 输入密码后确定,出现下图则连接成功。 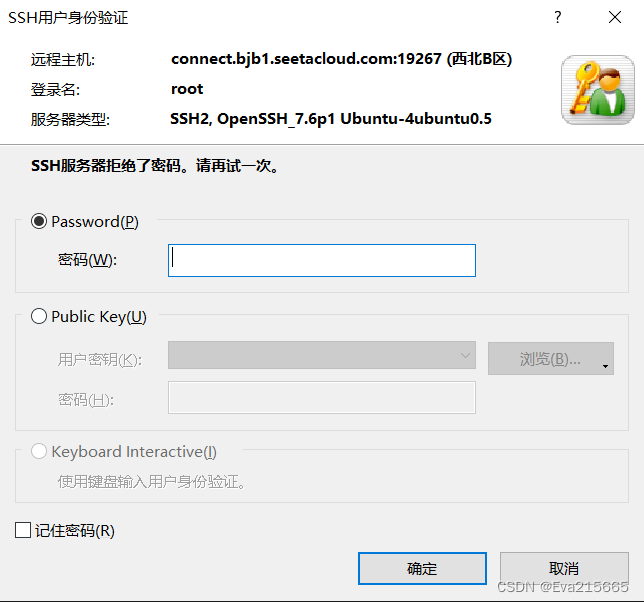 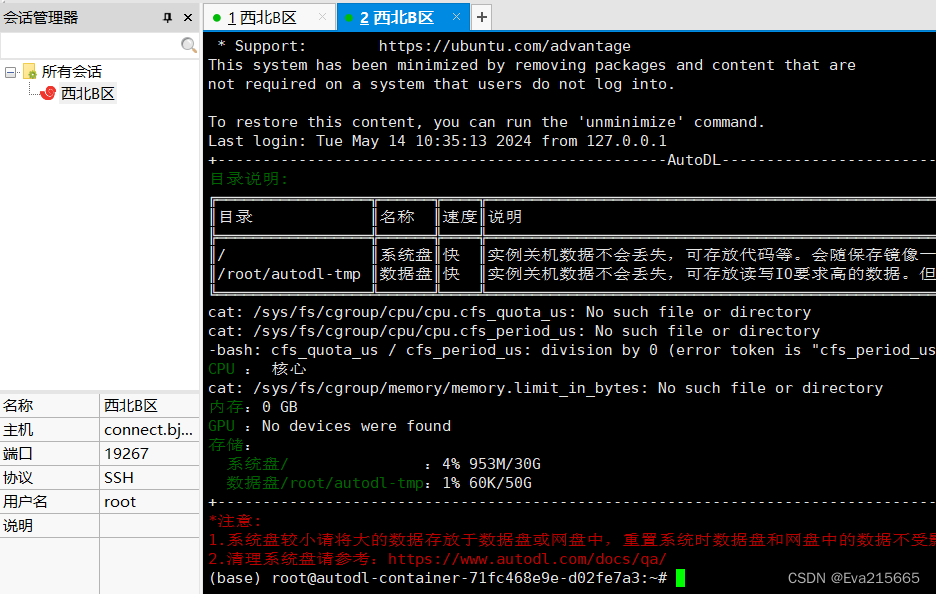 在Xshell中打开Xftp 在Xshell中打开Xftp  左侧是本地电脑左面上的文件,右侧是远程服务器上的文件,可以通过拖拽的方式双边相互传输。 左侧是本地电脑左面上的文件,右侧是远程服务器上的文件,可以通过拖拽的方式双边相互传输。 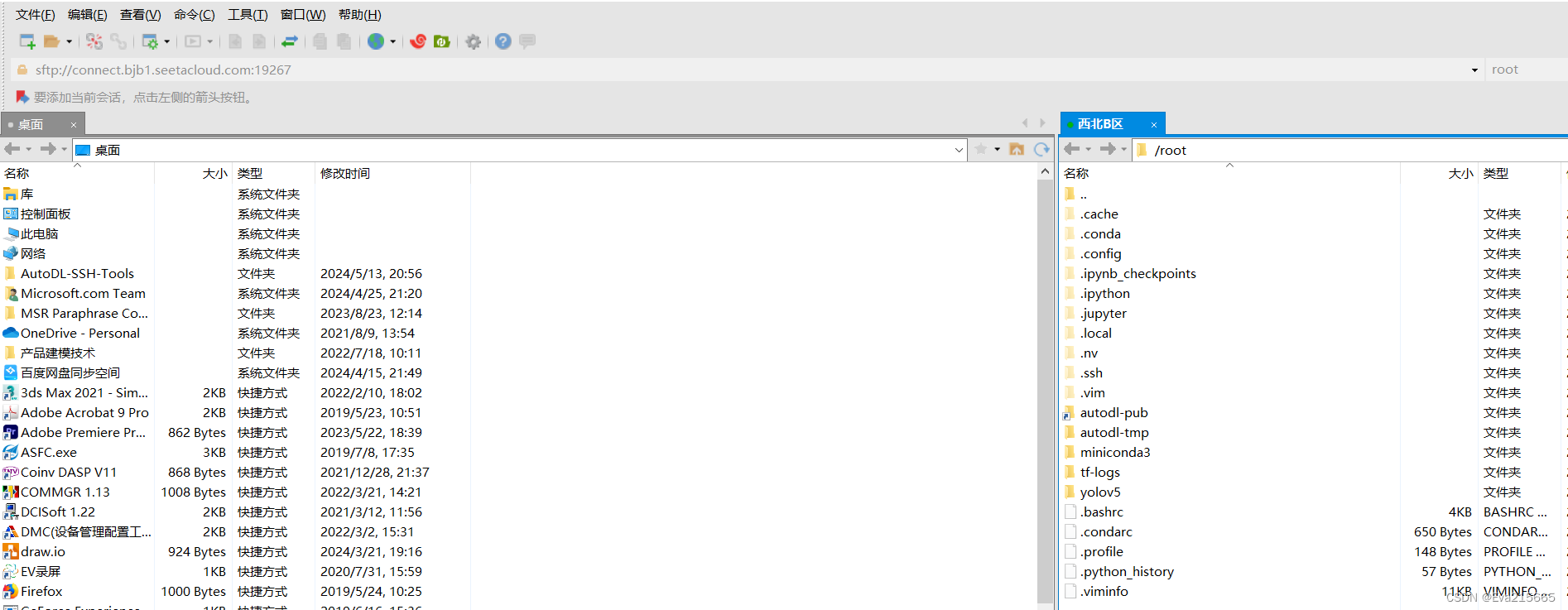 3. 远程服务器上的环境配置
3. 远程服务器上的环境配置
参考之前的博客windows/linux系统下Anaconda3安装配置/创建删除虚拟环境/在特定虚拟环境下安装库 以及这篇AutoDL从0到1搭建stable-diffusion-webui 几个地址需要注意: (1). 环境地址 先在默认路径下创建一个纯净的python环境,这个里面只有一些基础包,不含任何框架,在AutoDL远程服务器上,该环境的挂载目录为/root/miniconda3/envs conda create -n llmft python=3.10(3). 训练脚本地址 将自己在本地电脑上写的训练脚本,通过Xftp传输到远程服务器上,路径对应关系为,即挂载目录为/root/LLMFuntuning 这里将模型(本身较大,20G)挂载到了以下目录/root/autodl-tmp,这里解释一下autoDL提供的几个目录,autodl-tmp是数据盘,大小为100G,用于存在用户的个人数据,/root根目录下的文件,为系统盘,在系统盘存放训练文件xx并且在数据盘下存在模型xx后,存储空间占用情况如下。 在运行中遇到的问题 报错:ValueError: FP16 Mixed precision training with AMP or APEX (--fp16) and FP16 half precision evaluation (--fp16_full_eval) can only be used on CUDA or MLU devices or NPU devices or certain XPU devices (with IPEX). 原因及解决方案:使用AutoDL过程中,由于只是传输数据,并不进行训练,因此选择了无卡开机模式,导致没有GPU可用,重新关机在开机即可。 如果遇到关机再开发后GPU资源不足,则选择克隆镜像,然后再在可用的区域重新选择实例即可,大约需要5分钟,就会将所配置的环境、模型等完全克隆到新的实例上,还是比较方便的。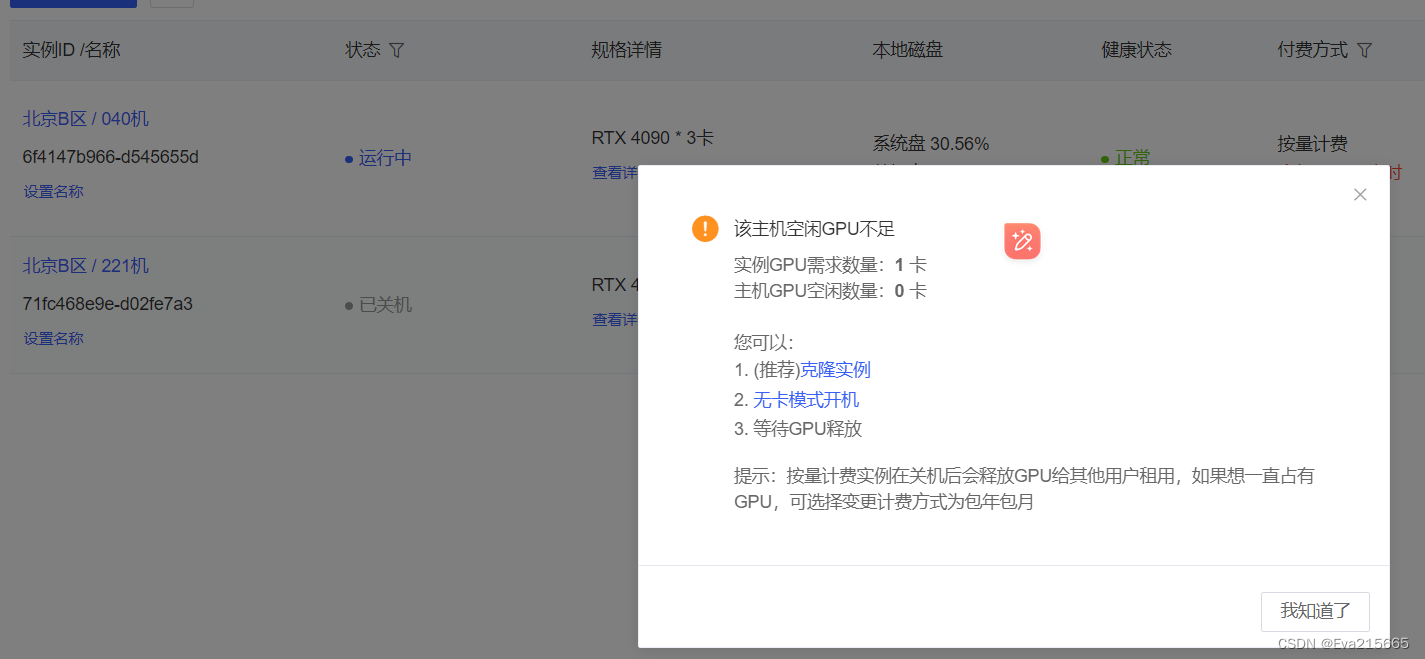 报错:NotImplementedError: Using RTX 4000 series doesn’t support faster communication broadband via P2P or IB. Please set NCCL_P2P_DISABLE="1" and NCCL_IB_DISABLE="1" or use accelerate launch` which will do this automatically. 原因及解决方案:表示尝试使用的功能或方法在当前环境或上下文中尚未实现。在这个具体的错误信息中,它指出使用 NVIDIA RTX 4000 系列的显卡时,不支持更快的通信(faster communicat)。这可能是指在使用某些深度学习框架(如 PyTorch)进行分布式训练时,尝试利用 NCCL 后端进行跨 GPU 的更高效通信,但是 RTX 4000 系列的显卡不支持这种更快的通信方式。 在终端运行以下两个命令:
export NCCL_P2P_DISABLE="1"
export NCCL_IB_DISABLE="1" 报错:NotImplementedError: Using RTX 4000 series doesn’t support faster communication broadband via P2P or IB. Please set NCCL_P2P_DISABLE="1" and NCCL_IB_DISABLE="1" or use accelerate launch` which will do this automatically. 原因及解决方案:表示尝试使用的功能或方法在当前环境或上下文中尚未实现。在这个具体的错误信息中,它指出使用 NVIDIA RTX 4000 系列的显卡时,不支持更快的通信(faster communicat)。这可能是指在使用某些深度学习框架(如 PyTorch)进行分布式训练时,尝试利用 NCCL 后端进行跨 GPU 的更高效通信,但是 RTX 4000 系列的显卡不支持这种更快的通信方式。 在终端运行以下两个命令:
export NCCL_P2P_DISABLE="1"
export NCCL_IB_DISABLE="1"
微调训练结束后,会出现一个lora微调的参数文件,需要将新的参数与原始模型合并,合并完成后,能够在预先指定的路径中看到一系列模型文件 5. 运行微调后的模型step1: 直接在gihub上clone chatglm3的仓库 cd 到autodl-tmp目录下,运行以下git命名 git clone https://github.com/THUDM/ChatGLM3.git在autodl-tmp下创建项目ChatGLM3 为ChatGLM3这个项目创建一个单独的叫做envChatGLM3的环境,环境的位置为默认即可 conda create -n envChatGLM3 python=3.10cd到ChatGLM3项目路径下,安装requirements.txt pip install -r requirements.txt环境创建完毕! ChatGLM3这个项目文件目录主要关注以下两个文件夹 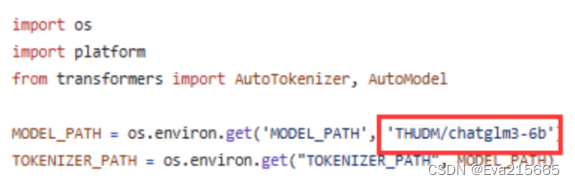 cd到/root/autodl-tmp/ChatGLM3/basic_demo路径下,用以下命令运行微调后的大模型 不要忘记激活相应的环境!
conda activate envChatGLM3
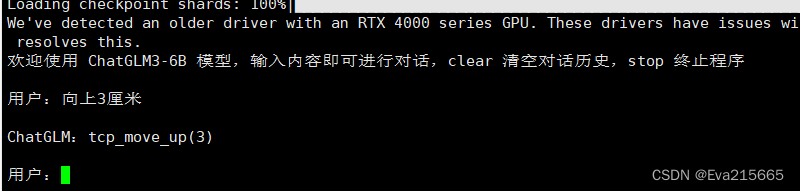
python cli_demo.py cd到/root/autodl-tmp/ChatGLM3/basic_demo路径下,用以下命令运行微调后的大模型 不要忘记激活相应的环境!
conda activate envChatGLM3
python cli_demo.py
运行效果如下: 用户: 向上3厘米 ChatGLM: tcp_move_up(3) 输出正确!! |

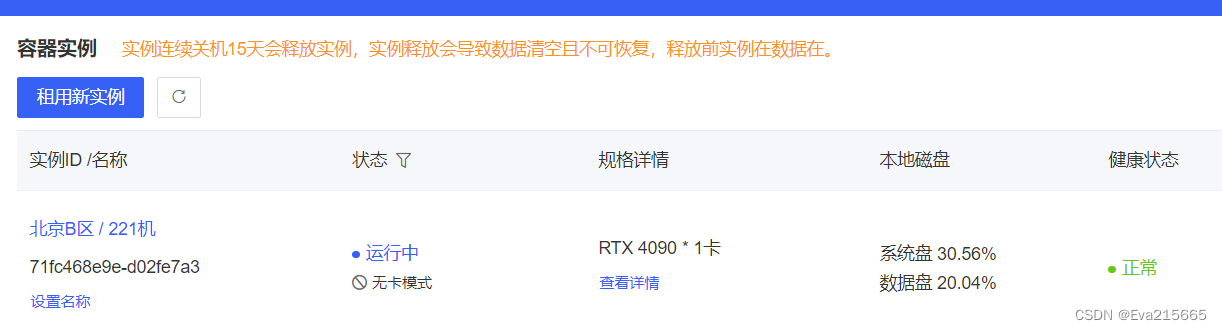
 (4). chatglm模型本身地址 这里用的是chatglm3-6b,可以用2种方式将大模型下载到远程服务器端 方法一 如果已经把大模型下载到了本地电脑上,那么可以通过Xftp拖拽到远程服务器上想要保存的路径下,传输速度6M/s,一个20G的模型大约需要1小时,还可以接收,如图。
(4). chatglm模型本身地址 这里用的是chatglm3-6b,可以用2种方式将大模型下载到远程服务器端 方法一 如果已经把大模型下载到了本地电脑上,那么可以通过Xftp拖拽到远程服务器上想要保存的路径下,传输速度6M/s,一个20G的模型大约需要1小时,还可以接收,如图。 
 模型传输完成后,对比一下,本地电脑和远程服务器端,文件结构完全一致,没有遗漏。
模型传输完成后,对比一下,本地电脑和远程服务器端,文件结构完全一致,没有遗漏。 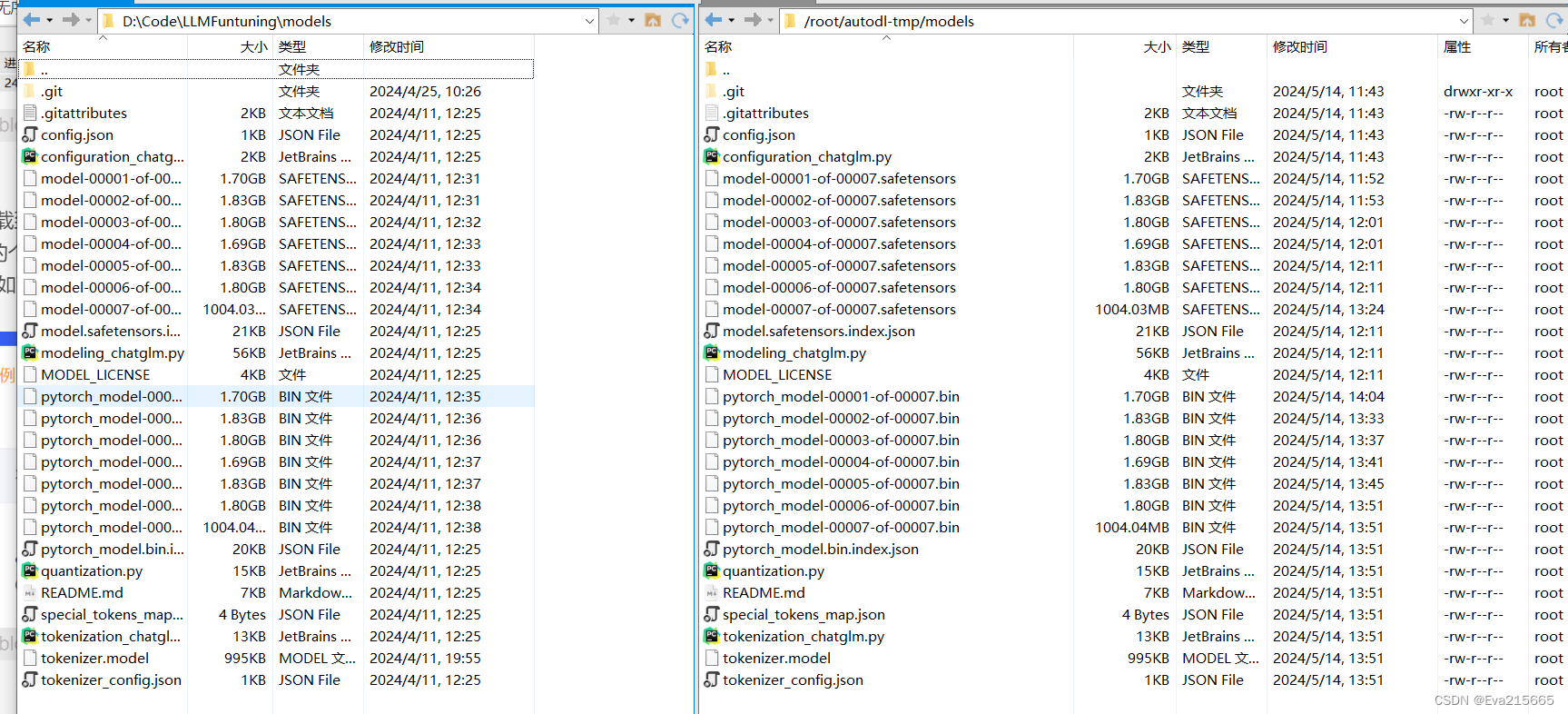 方法二 从网上下载,关于如何快速下载大模型,可以参考之前的博客如何快速下载大模型 也可以参考这篇AutoDL从0到1搭建stable-diffusion-webui 值得指出的是,开启学术加速要快很多,否则很慢甚至下载不了,开启方式
方法二 从网上下载,关于如何快速下载大模型,可以参考之前的博客如何快速下载大模型 也可以参考这篇AutoDL从0到1搭建stable-diffusion-webui 值得指出的是,开启学术加速要快很多,否则很慢甚至下载不了,开启方式
 使用类似autoDL这样的云服务器弊端:
使用类似autoDL这样的云服务器弊端:【本文地址】